-
基础算法--离散化
基本介绍
离散化:把无限空间中有限的个体映射到有限的空间中去,以此提高算法的时空效率。通俗的说,离散化是在不改变数据相对大小的条件下,对数据进行相应的缩小。
适用范围:数组中元素值域很大,但个数不是很多。
比如将a[]=[1,3,100,2000,500000]映射到[0,1,2,3,4]这个过程就叫离散化。离散化常与差分、前缀和、数组数组、线段树结合考查。
离散化实现方式:
手写离散化
例如:对于序列 [105,35,35,79,-7],排序并去重后变为 [-7,35,79,105],由此就得到了对应关系 -7->1, 35->2, 79->3, 105->4。
基本的步骤可以分为:
- 用一个辅助的数组把你要离散的所有数据存下来。
- 排序,排序是为了后面的二分。
- 去重,因为我们要保证相同的元素离散化后数字相同。
- 索引,再用二分把离散化后的数字放回原数组。
vector<int> alls; // 存储所有待离散化的值 sort(alls.begin(), alls.end()); // 将所有值排序 alls.erase(unique(alls.begin(), alls.end()), alls.end()); // 去掉重复元素 // 二分求出x对应的离散化的值 int find(int x) // 找到第一个大于等于x的位置 { int l = 0, r = alls.size() - 1; while (l < r) { int mid = l + r >> 1; if (alls[mid] >= x) r = mid; else l = mid + 1; } return r + 1; // +1:映射到1, 2, ...n(不加的话就是0~n-1) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
【知识点】
对于随机给定的一个数组,去除其中所包含的重复元素可以通过调用C++的库函数unique来实现。
但有一点需要注意的是,unique仅是对相邻的重复元素进行去重,若要对随机给定的数组进行去重则需要先对数组进行排序,使得重复元素相邻.
#include#include using namespace std; int main() { int n = 10; int a[10] = {4, 7, 4, 7, 2, 4, 6, 7, 4, 2}; sort(a, a + n); int m = unique(a, a + n) - a;// 从0开始 cout << "数组新的长度 " << m << endl; cout << "新数组 "; for(int i = 0;i < m; ++i) { cout << ' ' << a[i]; } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
数组新的长度 4
新数组 2 4 6 7注意事项:
1、去重并不是把数组中的元素删去,而是重复的部分元素在数组末尾,去重之后数组的大小要减一。
2、二分的时候,注意二分的区间范围,一定是离散化后的区间。
3、如果需要多个数组同时离散化,那就把这些数组中的数都用数组存下来。map映射
(由于不需要排序和去重等操作,会比第一种好写,且代码量会少很多):可以用 map(每次在map中查询一下这个值是否存在,如果存在则返回对应的值,否则对应另一个值)或 hash表(即unordered_map或手写hash表,运用方式和map相同)。
map与unordered_map的区别
- 对于map的底层原理,是通过红黑树(一种非严格意义上的平衡二叉树)来实现的,因此map内部所有的数据都是有序的(默认按key进行升序排序),map的查询、插入、删除操作的时间复杂度都是O(logn)。
- unordered_map和map类似,都是存储的key-value的值,可以通过key快速索引到value。不同的是unordered_map不会根据key的大小进行排序,存储时是根据key的hash值判断元素是否相同,即unordered_map内部元素是无序的。unordered_map的底层是一个防冗余的哈希表(开链法避免地址冲突)。
巩固练习
电影
【题目链接】步骤:
1、用 alls数组收集所有语言。
2、对 alls数组排序、去重。
3、find 函数用于把原始的稀疏编号转变为稠密编号。
4、ans 数组记录每种语言的科学家数。即这门语言有多少科学家会。
5、遍历所有电影,以每部电影的语音语言为条件,在ans数组中找最大值,若有多个相同的最大值,就找字幕语言最多的。【代码实现】
#include#include #include using namespace std; const int N = 2e5 + 10; int a[N], b[N], c[N]; int ans[N * 3];//3*N是因为语言的来源有3个地方,假设都不相同,则有3*N种语言 vector<int> alls; int n, m; int find(int x) { int l = 0, r = alls.size() - 1; while(l < r) { int mid = l + r >> 1; if(alls[mid] >= x) r = mid; else l = mid + 1; } return r; } int main() { cin >> n; for (int i = 0; i < n; i ++ )//保存科学家会的语言 { cin >> a[i]; alls.push_back(a[i]); } cin >> m; for (int i = 0; i < m; i ++ ) { cin >> b[i]; alls.push_back(b[i]); } for (int i = 0; i < m; i ++ ) { cin >> c[i]; alls.push_back(c[i]); } // 排序 + 去重 sort(alls.begin(), alls.end()); alls.erase(unique(alls.begin(), alls.end()), alls.end()); //a[i]中保存原始的稀疏编号,用find转变成稠密编号,并用ans数组记录每种语言出现的次数。 for(int i = 0; i < n; i ++) ans[find(a[i])]++; //遍历所有电影,按要求找到最多科学家会的电影 int ans0 = 0, ans1 = 0, ans2 = 0; //ans0保存最终结果,ans1和ans2为中间结果 for (int i = 0; i < m; i ++ ) { //会第i个电影音频的科学家数;会第i个电影字幕的科学家数 int anx = ans[find(b[i])]; int any = ans[find(c[i])]; // 前者判断条件表示有电影刷新 // 后者判断条件表示相同电影条件下的字幕刷新 if(anx > ans1 || (anx == ans1 && any > ans2)) { ans0 = i + 1;// 我们下标从0开始的 ans1 = anx; ans2 = any; } } if(ans0 == 0) puts("1");// 如果所有电影的音频和字幕科学家都不懂,随便选一个电影 else cout << ans0; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
区间和
思路:值域很大用离散化压缩优化!

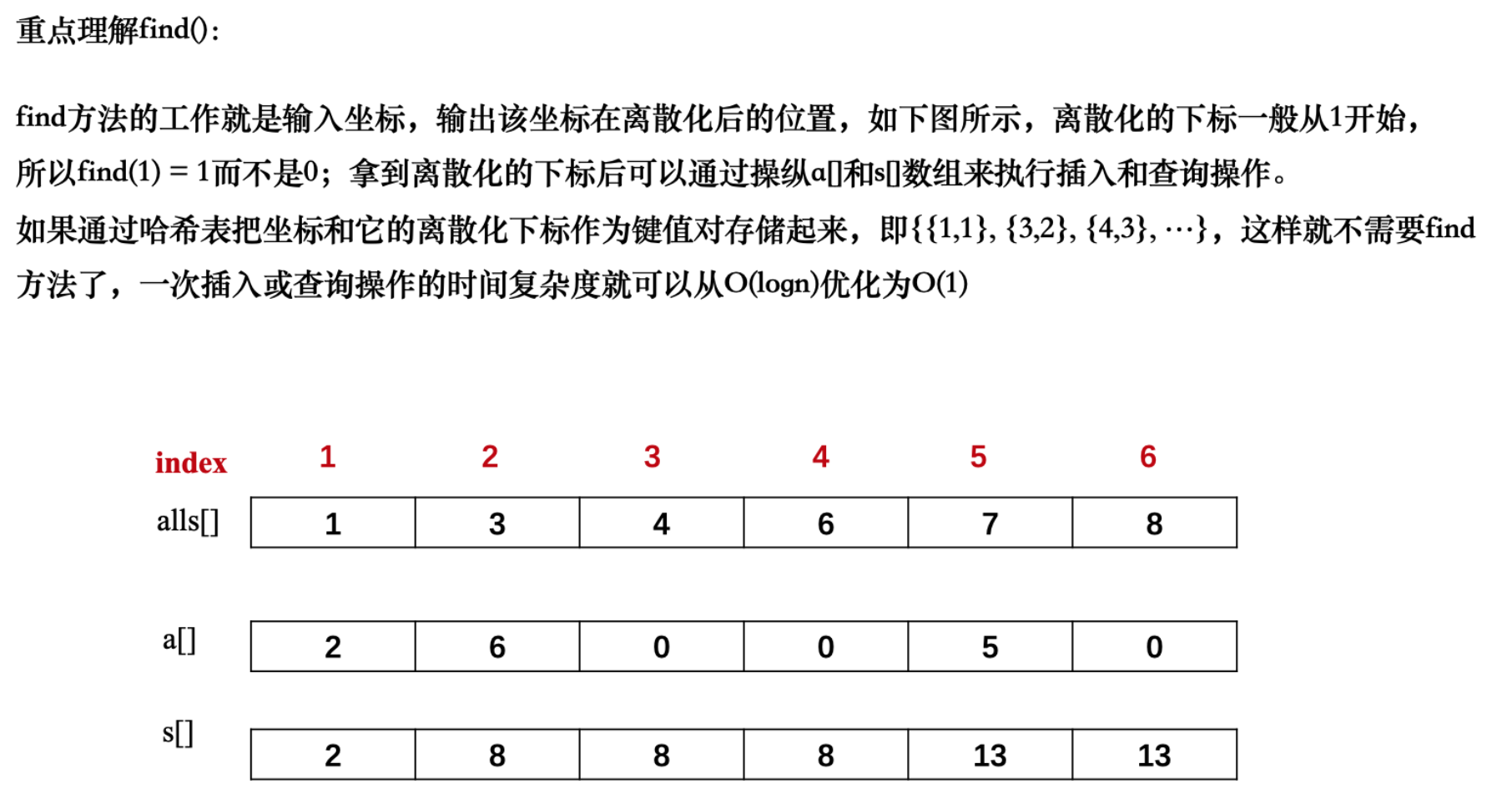
【代码实现】#include#include #include #define x first #define y second using namespace std; typedef pair<int, int> PII; const int N = 3e5 + 10; int a[N], s[N]; vector<PII> add, query; // 方便我们离散化还原数值,和区间查询操作 vector<int> alls; // 存储数值进行离散化操作 int n, m; // 二分求出x对应的离散化的值 int find(int x) { int l = -1, r = alls.size(); while(l + 1 != r) { int mid = l + r >> 1; if(alls[mid] <= x) l = mid; else r = mid; } // 从1开始映射,所以返回 加1 return l + 1; } int main() { cin >> n >> m; for (int i = 0; i < n; i ++ ) { int x, c; cin >> x >> c; add.push_back({x, c}); alls.push_back(x); } for (int i = 0; i < m; i ++ ) { int l, r; cin >> l >> r; query.push_back({l, r}); alls.push_back(l); alls.push_back(r); } // 排序 + 去重 sort(alls.begin(), alls.end()); alls.erase(unique(alls.begin(), alls.end()), alls.end()); // 数值还原映射到a[]数组 for(auto item : add) { int x = find(item.x);// 找到映射后的位置 a[x] += item.y;// 插入数值 } // 预处理前缀和 for (int i = 1; i <= alls.size(); i ++ ) s[i] = s[i - 1] + a[i]; // 处理区间和 for(auto item : query) { // 找到离散化后对应的位置 int l = find(item.x), r = find(item.y); cout << s[r] - s[l - 1] << endl; // 前缀和求区间和 } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
-
相关阅读:
关于电影的HTML网页设计—— 电影小黄人6页 HTML+CSS+JavaScript
11.外观模式
Vue79-路由组件独有的2个新的生命周期钩子
java.lang.Float类下hashCode()方法具有什么功能呢?
适合家电和消费类应用R7F101GEE4CNP、R7F101GEG4CNP、R7F101GEG3CNP、R7F101GEE3CNP新一代RL78通用微控制器
【密评】商用密码应用安全性评估从业人员考核题库(二)
ElasticSearch安装在SpringBoot下的使用,Mysql数据同步到ES包含多表
第八章 通过 REST 使用 Web 会话(Sessions)
安装配置vscode
day50-正则表达式01
- 原文地址:https://blog.csdn.net/qq_42673622/article/details/133162333