-
初识ElasticSearch
初识ElasticSearch
前言
本文是作者对于ElastiSearch的初步学习笔记,ElasticSearch属于NoSQL,能够进行高效的全文搜索,并且是基于分布式架构的,天然支持分布式、高并发,被广泛应用于各大搜索引擎。通过本篇文章,你将学习到ElasticSearch中的一些常见但重要的概念,掌握基本的DSL语法,同时学会使用SpringBoot整合ElasticSearch并掌握RestClient提供的常见API。
PS:如果文章存在纰漏、或者描述不当、错误,恳请您能够即使指出1、初识ElasticSearch
1.1 ES概述
-
ElasticSearch是什么?
Elasticsearch,简称ES(不要和JavaScript中的ES搞混了,JavaScript中的ES一般要带上版本号,比如ES6,ES2015,一般直接说ES都是指ElasticSearch),是一个开源的分布式搜索和分析引擎(也是一种文档型数据库)。它使用Lucene搜索引擎来提供全文搜索功能,并提供了大量的API,用于聚合、过滤和分析数据。Elasticsearch支持实时数据搜索和分析,并可以在多个节点之间分发数据和工作负载。它广泛用于构建企业搜索应用程序、日志分析、安全信息和业务分析等场景。
官网地址:https://www.elastic.co/cn/
-
ElasticSearch有什么用?
-
搜索和查询:ElasticSearch被广泛用于网站和应用程序中的搜索功能,可以通过简单的HTTP请求实现高效、灵活的搜索和查询。
-
日志分析:ElasticSearch可以处理大量的实时和历史日志数据,并提供强大的搜索和可视化能力,支持针对大规模数据的实时分析和监控。
-
数据聚合和分析:ElasticSearch支持对大型数据集进行聚合分析,可以将多个数据源进行聚合并生成高级数据分析和可视化报告。
-
全文搜索:ElasticSearch支持多种语言、分词、聚合和扩展,可以帮助用户完成各种全文搜索和相关性匹配操作。
-
地理空间搜索:ElasticSearch支持地理空间搜索和位置数据可视化,可以针对地理位置信息进行搜索和分析。
像在Github上搜代码、在电商网站搜索商品、在百度搜索答案、在打车软件搜索附近的车……都可以使用ElasticSearch实现
-
-
ElasticSearch的特点有哪些?
-
分布式存储和搜索:Elasticsearch 能够无缝地扩展到多台服务器上,并自动分布式存储和搜索数据。支持水平和垂直扩展,不需要停机维护。
-
高可用性:Elasticsearch有多节点架构,可以设置数据备份数量,以保证数据的可用性和容灾性。
-
实时搜索:Elasticsearch 通过实时索引机制,能够快速搜索并返回最新的结果。
-
全文检索和分析:Elasticsearch 能够对文本和结构化数据进行全文检索、聚合、统计和分析,支持多种查询方式,包括模糊查询、短语查询、前缀查询、通配符查询等。
-
自动建模和更新:Elasticsearch 能够自动处理数据的结构,创建索引、映射、数据类型等,并支持动态添加或修改字段。
-
多语言支持:Elasticsearch 支持多种语言的分词器,能够更好地适应全球化需求。
-
开发者友好:Elasticsearch 支持多种语言客户端,包括 Java、Python、PHP、Ruby、JavaScript 等,也提供了 Restful API 接口,易于集成和开发。
-
-
ElasticSearch的优缺点
- 优点:
-
高效的全文搜索:ElasticSearch 引擎基于 Lucene,具有高效的全文搜索能力,可以对海量的数据进行快速的检索。
-
高可用性和可伸缩性:ElasticSearch 支持分布式部署,数据可以被分散保存在多个节点上,实现高可用性和可伸缩性。
-
方便的数据聚合和分析:ElasticSearch 对数据聚合和分析提供了强大的支持,不仅可以进行基本的统计和聚合操作,还可以进行关系型数据库无法完成的复杂数据分析。
-
灵活的实时更新和扩展:ElasticSearch 支持实时更新数据,并且可以方便地进行扩展。例如,可以通过增加新的节点来提高搜索的速度和处理能力。
-
- 缺点:
-
学习成本较高:ElasticSearch具有很多的配置项和复杂的查询语法,需要用户学习和掌握。
-
硬盘资源消耗较大:ElasticSearch 采用磁盘存储数据,需要大量硬盘资源。
-
数据安全性问题: Elasticsearch 的默认设置对数据安全性的保护相对较低,需要用户进行必要的设置才能增强数据的安全性。
-
- 优点:
-
ELK技术栈
ELK(Elastic Stack)是一个开源的数据分析平台,包括 Elasticsearch、Logstash、Kibana和Beats这几个核心组件。
-
Elasticsearch:是一个分布式的搜索和分析引擎,能够通过RESTful API提供实时的搜索、分析和数据可视化功能。
-
Logstash:是一个数据收集和处理工具,支持从各种源获取数据,并将其转换为指定的格式,以供Elasticsearch等工具使用。
-
Kibana:是一个用于可视化和分析Elasticsearch数据的开源平台,能够提供交互式的数据可视化和实时监控功能。
-
Beats:是一个轻量级的数据收集器,能够从服务器、操作系统和各种设备中收集数据,并将其发送到Elasticsearch、Logstash和Kibana等组件进行分析和可视化。
Elastic Stack在企业中广泛应用于各种应用场景,如搜索、日志分析、安全监控、数据可视化等。由于其开源、可扩展和易于管理等特性,逐渐成为了开发人员和运维人员的首选数据分析平台。
-
-
Lucene是什么?
Lucene是一个Java语言实现的的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。
官网地址:https://lucene.apache.org/ 。

-
ElasticSearch的发展历史
Elasticsearch最初是由Shay Banon在2010年创建的一个开源搜索引擎。在创业公司Compass的基础上,他开始发展一个新的分布式搜索引擎。最初,这个搜索引擎的原型被命名为Compass2,后来改名为Elasticsearch。
-
2004年Shay Banon基于Lucene开发了Compass
-
2010年Shay Banon 重写了Compass,取名为Elasticsearch。
-
2012年2月,Elasticsearch第一次发布了alpha版本,之后接着发布了beta版本。在发布了第一个1.0版本后,Elasticsearch的用户群迅速增加,Elasticsearch站在了开源搜索引擎的前沿位置。
-
2015年2月,Elasticsearch公司更名为Elastic,并发布了更广泛的Elastic Stack产品系列,包括Elasticsearch、Kibana、Logstash和Beats等。
随着时间的推移,Elasticsearch不断发展和改进,现在成为了全球最受欢迎和广泛采用的搜索引擎之一,被广泛应用于大数据分析、日志收集、安全分析、企业搜索和电子商务等领域。
题外话:据说ShayBanon最先是为他老婆写的,他老婆喜欢做菜,于是他就为他老婆写了一个搜索引擎, 用于搜索各种菜谱

PS:看这发亮,就知道这是一个大佬🤣
-
-
为什么学ElasticSearch而不是其它的搜索引擎?
其一,学技术我们要大众化,大众化好找工作,其二大众化的技术肯定是有它的优点的,不然也不会这么多人用它,是吧(●ˇ∀ˇ●)。其二它免费,各大社区活跃,生态较好,学起来会比较顺畅,遇到问题,可能已经有前辈给出了解决方案
下面这张图是2021年各大搜索引擎排行榜👇

虽然在早期,Apache Solr是最主要的搜索引擎技术,但随着发展elasticsearch已经渐渐超越了Solr,独占鳌头:

1.2 倒排索引
倒排索引的概念是基于MySQL这样的正向索引而言的,所以要了解倒排索引,就得先了解正向索引。在倒排索引中有两个十分重要的概念:文档 和 词条
-
文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 -
词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条 -
什么是正向索引?
正向索引是MySQL中所使用的索引,它以每个文档的id(或者说每条记录的id)为关键字,建立索引。每次查看记录时,先通过id(这个在MySQL中称之为聚集索引)查找到对应的内容,或者通过二级索引查找到id,然后再查早到对应的内容,最后再判断该条记录中的内容是否符合我们的查找要求。
简而言之:就是必须要先有文档id,然后通过文档id查找文档内容,最后判断文档内容是否是我们要查找的,是则根据文档id得到文档内容
查找流程如下所示:
-
如果是根据id查询,那么直接走索引,查询速度非常快。
-
但如果是基于title做模糊查询(索引失效),只能是逐行扫描数据(全表搜索),流程如下:
- Step1:用户输入。用户搜索数据,条件是title符合
"%手机%" - Step2:查找。逐行获取数据,比如id为1的数据
- Step3:比对。判断数据中的title是否符合用户搜索条件
- Step4:获取数据。如果符合则放入结果集,不符合则丢弃。回到步骤1
- Step1:用户输入。用户搜索数据,条件是title符合

-
-
什么是倒排索引?
倒排索引是ElasticSearch所使用的索引,它将每个文档中的内容划分为一个个的词条,然后以每个词条作为关键字,建立索引。每次查找先通过词条确定文档id,然后根据文档id查找对应的内容。感觉类似于MySQL中的二级索引。
简而言之:就行必须先有词条,然后有文档id,最后通过文档id得到要查找的内容
倒排索引的创建流程:
- Step1:将每一个文档的数据利用算法分词,得到一个个词条
- Step2:创建表,每行数据包括词条、词条所在文档id、位置等信息
- Step3:因为词条唯一性,可以给词条创建索引,例如hash表结构索引
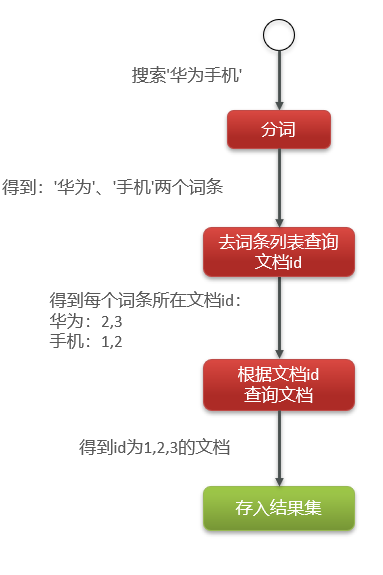
查找流程如下所示:
- Step1:用户输入。用户输入条件"华为手机"进行搜索。
- Step2:分词。对用户输入内容分词,得到词条:华为、手机。
- Step3:查找。拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
- Step4:获取数据。拿着文档id到正向索引中查找具体文档。
1.3 ES中的一些常见概念
ElasticSearch中有很多独有的概念,与MySQL中略有差别,但也有相似之处,这里就着重介绍一下ES中的常见概念
-
文档(Document):在Elasticsearch中,文档是存储在索引(Index)中的基本数据单元。它可以是JSON、XML或其他格式,它们通常包含了一些关键字和对应的值。每个文档都有一个唯一的标识符(ID),可以通过ID来获取或修改该文档的内容。 在Elasticsearch索引中,文档可以看做是可搜索、可分析的数据单位,可以直接进行检索、聚合和过滤操作。
PS:数据库中的一条记录可以对应一个文档
-
字段(Field):在Elasticsearch中,字段是文档的最基本组成部分。在一份文档中,字段表示文档中的一个单独数据项(类似于数据库中的列)。字段可以是以下类型之一:
-
文本字段(Text field):包含一个文本字符串,可分词。例如,一篇文章的标题。
-
日期字段(Date field):包含一个日期或日期时间。例如,一个事件的日期和时间。
-
数字字段(Numeric field):包含数字值,可以是整数或浮点型。例如,一个产品的价格。
-
布尔字段(Boolean field):包含一个布尔值,即“true”或“false”。例如,一个任务的完成状态。
-
地理位置字段(Geo field):包含一个点或一组点的地理位置坐标。例如,一家商店的经纬度。
-
二进制字段(Binary field):包含二进制数据,例如图片或PDF文件。
-
-
索引(Index):就是相同类型的文档的集合。
例如:
- 所有用户文档,就可以组织在一起,称为用户的索引;
- 所有商品的文档,可以组织在一起,称为商品的索引;
- 所有订单的文档,可以组织在一起,称为订单的索引;

-
映射:我们可以把索引当做是数据库中的表。数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
-
MySQL与ElasticSearch中概念的对比
MySQL Elasticsearch 说明 Table Index 索引(index),就是文档的集合,类似数据库的表(table) Row Document 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 Column Field 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) Schema Mapping Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) SQL DSL DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD -
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
-
对安全性要求较高的写操作,使用mysql实现
-
对查询性能要求较高的搜索需求,使用elasticsearch实现
-
两者再基于某种方式,实现数据的同步,保证一致性

-
1.4 安装ES和Kibana
略……详情见
ElasticSearch安装教程.md2、索引库操作
2.1 Mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
type:字段数据类型,常见的简单类型有:- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
index:是否创建索引,默认为trueanalyzer:使用哪种分词器properties:该字段的子字段
示例
{ "age": 21, "weight": 52.1, "isMarried": false, "info": "黑马程序员Java讲师", "email": "zy@itcast.cn", "score": [99.1, 99.5, 98.9], "name": { "firstName": "云", "lastName": "赵" } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
对应的每个字段映射(mapping):
- age:类型为 integer;参与搜索,因此需要index为true;无需分词器
- weight:类型为float;参与搜索,因此需要index为true;无需分词器
- isMarried:类型为boolean;参与搜索,因此需要index为true;无需分词器
- info:类型为字符串,需要分词,因此是text;参与搜索,因此需要index为true;分词器可以用ik_smart
- email:类型为字符串,但是不需要分词,因此是keyword;不参与搜索,因此需要index为false;无需分词器
- score:虽然是数组,但是我们只看元素的类型,类型为float;参与搜索,因此需要index为true;无需分词器
- name:类型为object,需要定义多个子属性
- name.firstName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
- name.lastName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
2.2 索引库的CRUD
这里我们统一使用Kibana编写DSL的方式来演示。
备注:在Kibana中,DSL是指“领域特定语言”(Domain Specific Language),即用于查询和过滤数据的查询语言。Kibana前端用户可以使用Kibana的查询DSL,通过图形界面,以文本格式或使用过滤器,从Elasticsearch中检索数据。
Kibana查询DSL具有丰富的语句类型,包括查询、聚合、过滤器等。语法类似于SQL,但具有Elasticsearch特定的查询语言元素。通过使用DSL,用户可以在Kibana中更好地与数据进行交互,并且可以更轻松地构建和管理他们的查询。另外,用户也可以利用Kibana的DSL来建立定期抽出和导出数据任务,方便数据的备份、共享和处理。
2.2.1 创建索引和映射
-
基本语法:
-
请求方式:PUT
-
请求路径:/索引库名 (可以自定义)
-
请求参数:mapping映射
-
-
格式:
PUT /索引库名称 { "mappings": { "properties": { "字段名":{ "type": "text", "analyzer": "ik_smart" }, "字段名2":{ "type": "keyword", "index": "false" }, "字段名3":{ "properties": { "子字段": { "type": "keyword" } } }, // ...略 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
示例
创建索引库和映射:
PUT /test { "mappings": { "properties": { "info": { "type": "text", "analyzer": "ik_smart" }, "email": { "type": "keyword", "index": false }, "name": { "type": "object", "properties": { "firstName": { "type": "keyword" }, "lastName": { "type": "keyword" } } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26

2.2.2 查询索引库
-
基本语法:
-
请求方式:GET
-
请求路径:/索引库名
-
请求参数:无
-
-
格式:
GET /索引库名- 1
示例
查询2.2.1中创建的索引库
GET /test- 1
注意:查询不存在的索引库会报错
{ "test" : { "aliases" : { }, "mappings" : { "properties" : { "email" : { "type" : "keyword", "index" : false }, "info" : { "type" : "text", "analyzer" : "ik_smart" }, "name" : { "properties" : { "firstName" : { "type" : "keyword" }, "lastName" : { "type" : "keyword" } } } } }, "settings" : { "index" : { "routing" : { "allocation" : { "include" : { "_tier_preference" : "data_content" } } }, "number_of_shards" : "1", "provided_name" : "test", "creation_date" : "1684480784390", "number_of_replicas" : "1", "uuid" : "wrF-3jxuTgGTq5Z8j7yWHg", "version" : { "created" : "7120199" } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
2.2.3 修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。
-
基本语法
- 请求方式:PUT
- 请求路径:/索引库名/_mapping
- 请求参数:properties
-
格式
PUT /索引库名/_mapping { "properties": { "新字段名":{ "type": "integer" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
示例
新增字段
PUT /test/_mapping { "properties": { "age": { "type": "integer" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

如果直接修改会报错:

2.2.4 删除索引库
-
基本语法
-
请求方式:DELETE
-
请求路径:/索引库名
-
请求参数:无
-
-
格式
DELETE /索引库名- 1
示例
删除索引库
DELETE /test- 1
注意:如果删除不存在的索引库,会报错

3、文档操作
3.1 新增文档
-
语法
POST /索引库名/_doc/文档id { "字段1": "值1", "字段2": "值2", "字段3": { "子属性1": "值3", "子属性2": "值4" }, // ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
示例
往test索引库中添加一个文档
POST /test/_doc/1 { "info":"往test索引库中添加一个文档", "email":"ghp@qq.com", "name":{ "firstName":"你", "lastName":"好" } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注意:
- 如果不手动设置文档id,ES会自动随机生成一个文档id
- 可以重复添加,每添加以此,文档的
_version都会自增1

3.2 查询文档
-
语法
GET /{索引库名称}/_doc/{id}- 1
-
示例
查询id为1的文档(不存在就会报错)
GET /test/_doc/1- 1

3.3 删除文档
-
语法
DELETE /{索引库名}/_doc/id值- 1
-
示例
DELETE /test/_doc/1- 1
注意:每执行一次删除或者查询,
_version字段都会自增1
3.4 修改文档
修改有两种方式:
- 全量修改:直接覆盖原来的文档,新生成的文档只含修改的字段,未修改的字段直接丢失了
- 增量修改:修改文档中的部分字段,未修改的字段不会丢失
温馨提示:尽量慎用全量修改
3.4.1 全量修改
全量修改是覆盖原来的文档,其本质是:
- 根据指定的id删除文档
- 新增一个相同id的文档
所以说全量修改既可以当作修改操作,又可以当作新增操作
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
-
语法
PUT /{索引库名}/_doc/文档id { "字段1": "值1", "字段2": "值2", // ... 略 }- 1
- 2
- 3
- 4
- 5
- 6
-
示例
全量修改info和age字段
PUT /test/_doc/1 { "info":"进行全量修改", "age":"18" }- 1
- 2
- 3
- 4
- 5

可以看到,name字段没有了,但是多了一个age字段。如果如果文档id没有与之对应的文档,则直接新增
PUT /test/_doc/2 { "info":"进行全量修改", "age":"18" }- 1
- 2
- 3
- 4
- 5

3.4.2 增量修改
-
语法
POST /{索引库名}/_update/文档id { "doc": { "字段名": "新的值", } }- 1
- 2
- 3
- 4
- 5
- 6
-
示例:
增量修改info字段
POST /test/_update/1 { "doc":{ "info":"增量修改" } }- 1
- 2
- 3
- 4
- 5
- 6

注意:如果使用增量修改,修改一个不存在的文档,则会直接报错

4、RestClient
-
RestClient是什么?
RestClient(Restful Client)是一种HTTP请求工具,它可以模拟HTTP请求,用于测试和调试RESTful Web服务的API。RestClient通常被用于调试或测试服务端API是否正常工作,也可以用来将数据推送到Web服务端。
RestClient可以直接在浏览器中运行,它的操作界面简单易用,支持GET、POST、PUT、DELETE等常用的HTTP请求方法,并且用户可以在请求中添加请求参数、请求头部等元素,进行数据传输、调试和测试。同时,RestClient也支持设置SSL协议、HTTBP代理等高级选项,消除了在开发和测试过程中遇到的许多网络难题。
在开发过程中,RestClient是一个非常方便实用的工具,它不依赖任何语言、任何平台,只需要指定要测试的API URL和请求方法,就可以模拟HTTP请求,获取响应结果,有效地提高了开发效率。
官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/index.html
ES 提供了各种语言的 RestClient,而我们要使用的 JavaRestClient
-
JavaRestClient的分类
- Java Low-Level Rest Client:提供了基本的 REST API 功能,例如发送 HTTP 请求、从 HTTP 响应中解析出返回数据、错误处理等。因此,Java Low-Level Rest Client 是一个类似于其他 HTTP 客户端框架,例如 Apache HttpClient 的低级别客户端。需要自己手动构建请求和响应解析,相对比较繁琐和底层。
- Java High-Level Rest Client:提供了更高级别的接口,简化了与 Elasticsearch 交互的过程。它提供了自动序列化和反序列化数据、自动生成 JSON 等功能,可以更轻松地执行操作,并且支持 Elasticsearch 的复杂查询、聚合和操作。Java High-Level Rest Client 更加适合于业务开发人员,易于使用且具有更强的可读性,并且提供了更好的错误处理和重试机制。
总的来说,Java Low-Level Rest Client 捆绑比较低,主要用于开发者自己封装管理类库,而 Java High-Level Rest Client则提供了许多用于处理数据的帮助程序类,可以大大加速业务开发的进程。
4.0 前置知识
在体验RestClient之前,我们需要对依据MySQL中的表来创建索引库有一定程度的了解
创建索引库,最关键的是mapping映射,而mapping映射要考虑的信息包括:
- 字段名
- 字段数据类型
- 是否参与搜索
- 是否需要分词
- 如果分词,分词器是什么?
其中:
-
字段名、字段数据类型,可以参考数据表结构的名称和类型
-
是否参与搜索要分析业务来判断,例如图片地址,就无需参与搜索
-
是否分词呢要看内容,内容如果是一个整体就无需分词,反之则要分词
-
分词器,我们可以统一使用ik_max_word
-
什么情况需要分词
在 Elasticsearch 中,分词是将文本拆解为一段一段的单词或词汇的过程。对于需要被搜索、聚合1、过滤的文本数据,需要使用分词来进行处理和索引,从而提高搜索的准确性和可靠性。
-
什么情况下不需要索引?
在 Elasticsearch 中,每个字段的 index 参数控制是否要对该字段进行索引。当 index 参数设置为 true 时,该字段将会被索引,可以进行全文搜索等相关操作。当 index 参数设置为 false 时,则意味着该字段不会被建立索引,也就不会被搜索、排序或聚合,只能被存储和请求。
一般来说:
- 对于需要被搜索和过滤的字段,index 应该设置为 true。比如内容需要检索,日期需要筛选。
- 对于不需要搜索、但是需要显示的字段,如用户的姓名、ID等,index 应该设置为 false。因为这样的字段不需要进行搜索和分析,可以减小索引的大小,提高检索效率。
同时请注意,设置 index 为 false 并不意味着该字段不能进行查询,只是该字段不能进行全文搜索、检索和聚合操作。如果对于不希望被搜索的敏感字段,可以考虑设置 index 为 false,但同时进行 store 参数设置为 true,即存储字段内容的值,避免对敏感数据的泄漏。或者也可以考虑使用加密等方式进行保护。
-
地址坐标
ES中支持两种地理坐标数据类型:
geo_point:由纬度(latitude)和经度(longitude)确定的一个点。例如:“32.8752345,120.2981576”geo_shape:有多个 geo_point 组成的复杂几何图形。例如一线,“LINESTRING(-77.0365338.897676,-77.00905138.889939)”
-
copy_to根据一个字段比根据一个字段搜的效率要高,但有时候在进行搜索时需要匹配多个或全部字段,此时一个一个字段进行查询会造成效率低下的情况。这时候可以使用 copy to 的方法,在索引时将多个字段的值合并成一个字段进行索引。这种方式在索引创建时将文本数据合并成一个字段,然后在搜索时只需要对一个字段进行搜索,从而提高了搜索速度和效率。这种方式的好处在于可以减少需要索引的字段数量,从而减小索引的大小,加快搜索速度。同时,使用 copy to 还可以简化查询语句,提高索引的可读性和可维护性。
需要注意的是,使用 copy to 的方法可能会增加索引时间和内存的消耗,因此需要权衡索引时间和查询效率的影响,在实际使用中选择合适的方法来进行数据处理。
字段拷贝可以使用copy_to属性将当前字段拷贝到指定字段。示例(将brand字段拷贝到all字段中):

4.1 快速体验
示例
在Java中使用RestHighLevelClient创建索引库
-
Step1:环境搭建
1)创建数据库,导入数据
创建一个数据库,名称为
heima,然后将课程资料中的SQL导入到该数据库中,数据库的表结构如下所示:
CREATE TABLE `tb_hotel` ( `id` bigint(20) NOT NULL COMMENT '酒店id', `name` varchar(255) NOT NULL COMMENT '酒店名称;例:7天酒店', `address` varchar(255) NOT NULL COMMENT '酒店地址;例:航头路', `price` int(10) NOT NULL COMMENT '酒店价格;例:329', `score` int(2) NOT NULL COMMENT '酒店评分;例:45,就是4.5分', `brand` varchar(32) NOT NULL COMMENT '酒店品牌;例:如家', `city` varchar(32) NOT NULL COMMENT '所在城市;例:上海', `star_name` varchar(16) DEFAULT NULL COMMENT '酒店星级,从低到高分别是:1星到5星,1钻到5钻', `business` varchar(255) DEFAULT NULL COMMENT '商圈;例:虹桥', `latitude` varchar(32) NOT NULL COMMENT '纬度;例:31.2497', `longitude` varchar(32) NOT NULL COMMENT '经度;例:120.3925', `pic` varchar(255) DEFAULT NULL COMMENT '酒店图片;例:/img/1.jpg', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2)创建Maven工程,构建SpringBoot项目,导入依赖,编写application.yml配置文件

-
Step2:初始化 Java Rest Client
1)引入ES的Java Rest Hign Level Client依赖
<dependency> <groupId>org.elasticsearch.clientgroupId> <artifactId>elasticsearch-rest-high-level-clientartifactId> dependency>- 1
- 2
- 3
- 4
2)覆盖默认的ES版本
SpringBoot默认的ES版本是7.6.2,但我在Linux中安装的ES是7.12.1,所以需要进行版本覆盖
<properties> <java.version>1.8java.version> <elasticsearch.version>7.12.1elasticsearch.version> properties>- 1
- 2
- 3
- 4
3)初始化 Java Rest Hign Level Client
@BeforeEach public void setUp(){ this.restHighLevelClient = new RestHighLevelClient(RestClient.builder( HttpHost.create("http://192.168.88.130:9200") )); }- 1
- 2
- 3
- 4
- 5
- 6
-
Step3:创建索引库
来看下酒店数据的索引库结构:
-
字段分析
-
id字段,在数据库中是long类型,但是ES中id一般都是字符串类型,而字符串类型有text(分词),keyword(不分词),显然文档id是不参与用户搜索(用户不可能直接输入id来搜索),所以type类型为keyword;又因为id要参与CRUD操作,所以需要index,index默认true即可
-
name字段,在数据库中是varchar类型,并且酒店名参与用户搜索,需要分词,所以为text;分词器统一采用ik_max_word,name参与了搜索所以需要index,默认为true即可
-
address字段,用户很少会根据地址搜索酒店(这个也可以分词,看具体场景吧,这里就参考一般情况),所以不需要分词,type为keyword,因为不参与搜索,不需要索引,所以index设置为false
-
price字段,参与排序、过滤等操作,所以需要分词,type为integer,同样需要索引,所以index默认为true
-
socre字段,参与求平均操作,所以需要分词,type为integer,index默认即可
-
brand字段,不参与搜索,所以不需要分词,type为keyword,但参与过滤,所以需要index
-
latitude字段在mysql中是varchar类型,但是在ES中有一个单独的数据类型 geo_point 用来存放地理坐标
-
copy to说明:由于name、brand、city等字段我们有时候需要一起来搜,为了提高效率,我们将他们统一拷贝到all字段中,然后ES会为all这个字段建立一个索引,此时搜索起来效率就会提高很多(类似于MySQL中的联合索引)
-
PUT /hotel { "mappings": { "properties": { "id": { "type": "keyword" }, "name":{ "type": "text", "analyzer": "ik_max_word", "copy_to": "all" }, "address":{ "type": "keyword", "index": false }, "price":{ "type": "integer" }, "score":{ "type": "integer" }, "brand":{ "type": "keyword", "copy_to": "all" }, "city":{ "type": "keyword", "copy_to": "all" }, "starName":{ "type": "keyword" }, "business":{ "type": "keyword" }, "location":{ "type": "geo_point" }, "pic":{ "type": "keyword", "index": false }, "all":{ "type": "text", "analyzer": "ik_max_word" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
特殊字段说明:
- location:地理坐标,里面包含精度、纬度
- all:一个组合字段,其目的是将多字段的值 利用copy_to合并,提供给用户搜索
上面的DSL语句只能在Kibana的DevTools工具中运行,如果我们想要在Java代码中运行,需要换种写法
@Test public void createHotelIndex() throws IOException { // 创建Request对象(参数是要操作索引库的名称) CreateIndexRequest request = new CreateIndexRequest("hotel"); // 准备请求参数(DSL语句) request.source(HotelConstants.MAPPING_TEMPLATE, XContentType.JSON); // 发送请求 restHighLevelClient.indices().create(request, RequestOptions.DEFAULT); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
备注:HotelConstants.MAPPING_TEMPLATE是一个字符串,它就是上面的DSL语句
-
4.2 操作索引库
在4.1中我们学会了如何使用RestClient创建索引库,本小节我们将学习RestClient其它的API,比如:删除索引库、判断索引库是否存在
JavaRestClient操作elasticsearch的流程基本类似。核心是client.indices()方法来获取索引库的操作对象。
索引库操作的基本步骤:
-
初始化RestHighLevelClient
-
创建XxxIndexRequest。XXX是Create、Get、Delete
-
准备DSL( Create时需要,其它是无参)
-
发送请求。调用RestHighLevelClient#indices().xxx()方法,xxx是create、exists、delete
-
删除索引库
@Test void testDeleteHotelIndex() throws IOException { // 创建Request对象(参数是要操作索引库的名称) DeleteIndexRequest request = new DeleteIndexRequest("hotel"); // 发送请求 restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
判断索引库是否存在
@Test void testExistsHotelIndex() throws IOException { // 创建Request对象(参数是要操作索引库的名称) GetIndexRequest request = new GetIndexRequest("hotel"); // 发送请求 boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT); // 输出 System.err.println(exists ? "索引库已经存在!" : "索引库不存在!"); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4.3 操作文档
文档操作的基本步骤:
- 初始化RestHighLevelClient
- 创建XxxRequest。XXX是Index、Get、Update、Delete、Bulk
- 准备参数(Index、Update、Bulk时需要)
- 发送请求。调用RestHighLevelClient#.xxx()方法,xxx是index、get、update、delete、bulk
- 解析结果(Get时需要)
4.3.1 新增文档
示例
我们要将 heima 这个数据库中的 hotel 表中的酒店数据查询出来,写入ES中
-
Step1:环境搭建
略……参考4.1的环境搭建
-
Step2:创建文档实体对象
我们从数据库查询出来的是一个Hotel类型的对象,它与我们在ES索引库中的数据类型和结构有一定程度差异,我们要将longitude和latitude需要合并为location,所以我们需要创建一个新的类 HotelDoc,用于对应ES索引库
-
Step3:新增文档
@Test public void testAddDocument() throws IOException { // 根据id查询出酒店的数据 Hotel hotel = hotelService.getById(36934L); // 将查询到的酒店数据转换成文档类型的数据 HotelDoc hotelDoc = new HotelDoc(hotel); // 创建Request对象 IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString()); // 准备请求参数(DSL语句) request.source(JSON.toJSONString(hotelDoc), XContentType.JSON); // 发送请求 restHighLevelClient.index(request, RequestOptions.DEFAULT); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.3.2 查询文档

示例
@Test void testGetDocumentById() throws IOException { // 准备Request GetRequest request = new GetRequest("hotel", "36934"); // 发送请求,得到响应 GetResponse response = restHighLevelClient.get(request, RequestOptions.DEFAULT); // 解析响应结果 String json = response.getSourceAsString(); System.out.println(json); HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class); System.out.println(hotelDoc); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

4.3.3 删除文档
@Test public void testDeleteDocument() throws IOException { // 准备Request DeleteRequest request = new DeleteRequest("hotel", "36934"); // 发送请求 restHighLevelClient.delete(request, RequestOptions.DEFAULT); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
4.3.4 修改文档
在RestClient的API中,全量修改与新增的API完全一致,判断依据是ID:
- 如果新增时,ID已经存在,则修改(增量修改)
- 如果新增时,ID不存在,则新增(全量修改)
- 1

4.3.5 批量导入文档
RestClient提供BulkRequest用户进行批处理,其本质就是将多个普通的CRUD请求组合在一起发送
其中提供了一个add方法,用来添加其他请求:

可以看到,能添加的请求包括:
- IndexRequest,也就是新增
- UpdateRequest,也就是修改
- DeleteRequest,也就是删除
因此Bulk中添加了多个IndexRequest,就是批量新增功能了。示例:
示例
利用BulkRequest批量将数据库数据导入到索引库中
@Test public void testBulkRequest() throws IOException { // 批量查询酒店数据 List<Hotel> hotels = hotelService.list(); // 创建Request BulkRequest request = new BulkRequest(); // 准备参数,添加多个新增的Request for (Hotel hotel : hotels) { // 转换为文档类型HotelDoc HotelDoc hotelDoc = new HotelDoc(hotel); // 创建新增文档的Request对象 request.add(new IndexRequest("hotel") .id(hotelDoc.getId().toString()) .source(JSON.toJSONString(hotelDoc), XContentType.JSON)); } // 发送请求 restHighLevelClient.bulk(request, RequestOptions.DEFAULT); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
常见的DSL语句
# 查询所有的索引库 GET _search { "query": { "match_all": {} } } # 测试ES分词器对于中文的分词 POST /_analyze { "text":"你好呀,ElasticSearch太优秀了!", "analyzer": "ik_smart" } # 测试添加了扩展词和禁用词 POST /_analyze { "text":"嗯你好,鸡你太美,我们不能吸海洛因,但是可以白嫖黑马的Java课", "analyzer": "ik_smart" } # 创建索引库和映射 PUT /test { "mappings": { "properties": { "info": { "type": "text", "analyzer": "ik_smart" }, "email": { "type": "keyword", "index": false }, "name": { "type": "object", "properties": { "firstName": { "type": "keyword" }, "lastName": { "type": "keyword" } } } } } } # 查询 GET /test # 新增字段 PUT /test/_mapping { "properties": { "age": { "type": "integer" } } } # 删除索引库 DELETE /test # 往test索引库中添加一个文档 POST /test/_doc/1 { "info":"往test索引库中添加一个文档", "email":"ghp@qq.com", "name":{ "firstName":"你", "lastName":"好" } } # 查询文档 GET /test/_doc/1 # 删除文档 DELETE /test/_doc/1 # 全量修改文档 PUT /test/_doc/2 { "info":"进行全量修改", "age":"18" } # 增量修改 POST /test/_update/1 { "doc":{ "info":"增量修改" } } # 根据id查询文档 GET /hotel/_doc/1 # 查询索引库中所有的文档 POST hotel/_search { "query": { "match_all": {} } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
聚合:聚合操作包括求最大/小/平均值 ↩︎
-
-
相关阅读:
【推荐系统 02】DeepFM、YoutubeDNN、DSSM
如何使用Docker部署Apache+Superset数据平台并远程访问?
Linux编程:获取GMT(UTC)与Local时间,及其线程安全
MapReduce(二)
网站图片如何批量下载教程
JS:给数字添加千分位符(每3位数用逗号隔开)
几种研发管理流程
研发效能|Kubernetes核心技术剖析和DevOps落地经验
中间件安全:Apache 目录穿透.(CVE-2021-41773)
做项目管理有且有必要了解并学习的重要知识--PMP项目管理
- 原文地址:https://blog.csdn.net/qq_66345100/article/details/133107206
