-
计算机视觉与深度学习-图像分割-视觉识别任务01-语义分割-【北邮鲁鹏】
视觉识别任务

语义分割
语义分割定义
给每个像素分配类别标签。
不区分实例,只考虑像素类别。

语义分割思路:滑动窗口

滑动窗口缺点
重叠区域的特征反复被计算,效率很低。
所以针对该问题提出了新的解决方案–全卷积。
语义分割思路(全卷积)
让整个网络只包含卷积层,一次性输出所有像素的类别预测。

全卷积优点
不用将图片分为一个个小区域然后再对这一个个小区域进行分类,而是一次性输出像素的类别预测,减少了重叠区域重复计算,从而减少了运算量,加快了运算速度。
全卷积缺点
1 处理过程中一直保持原始分辨率,即卷积过程中一直保持图片长宽不变。对于显存的需求会非常庞大,甚至使得前向数据不能完整的保存在显存中。
针对这个问题,提出了先下采样然后上采样。
2 上采样是根据下采样得到的高级语义得到的,但是有时候高级语义效果并不好,还需要使用低级语义。
针对这个问题,提出了Unet,将下采样过程中的低级语义整合到上采样过程中,从而使得效果更好。
先下采样再上采样

下采样算法
pooling(池化)
strided convolution
上采样算法
unpooling(反池化)
nearest neighbor
对于每个池化区域,最近邻反池化会将池化后的值复制到恢复区域的每个位置,以填充恢复区域。这样,可以将特征图恢复到与池化之前相同的尺寸。

需要注意的是,最近邻反池化是一种近似的逆操作,因为池化操作中的信息丢失是不可逆的。因此,最近邻反池化只能恢复到大致相似的尺寸和分布,而无法完全还原原始特征图。bed of nails
对于每个池化区域,最近邻反池化会将池化后的值把数据放在左上角,其他位置置零,以填充恢复区域。这样,可以将特征图恢复到与池化之前相同的尺寸。

unpooling缺点
人为给定的像素值可能是噪声。
人为给定的非0像素值可能原来并不在当前位置。针对这些问题,提出了反池化操作思想–index Unpooling。
Index Unpooling
Index Unpooling的基本原理是根据池化时记录的最大值索引位置,将池化后的特征值放回到对应的恢复区域中。具体而言,对于每个最大值索引位置,Index Unpooling会将一个固定的值(例如1)放置在对应的恢复区域中,其余位置为零。通过这种方式,可以恢复出与池化之前相同尺寸的特征图。
max unpooling(反池化)
方式一(固定写死)
对于一些模型来说,上采样和下采样的结构往往是对称的,可以在下采样的Max Pooling时记录最大值的位置,在unpooling的时候把数据还原到最大值的位置,其余位置置零。
转置卷积(Transpose Convolution)
方式二(自动学习)
回顾
3 × 3 3 \times 3 3×3卷积,步长(stride)1,零填充(pad)1

3 × 3 3 \times 3 3×3卷积,步长(stride)2,零填充(pad)1

一维例子

步长为1下采样

上采样
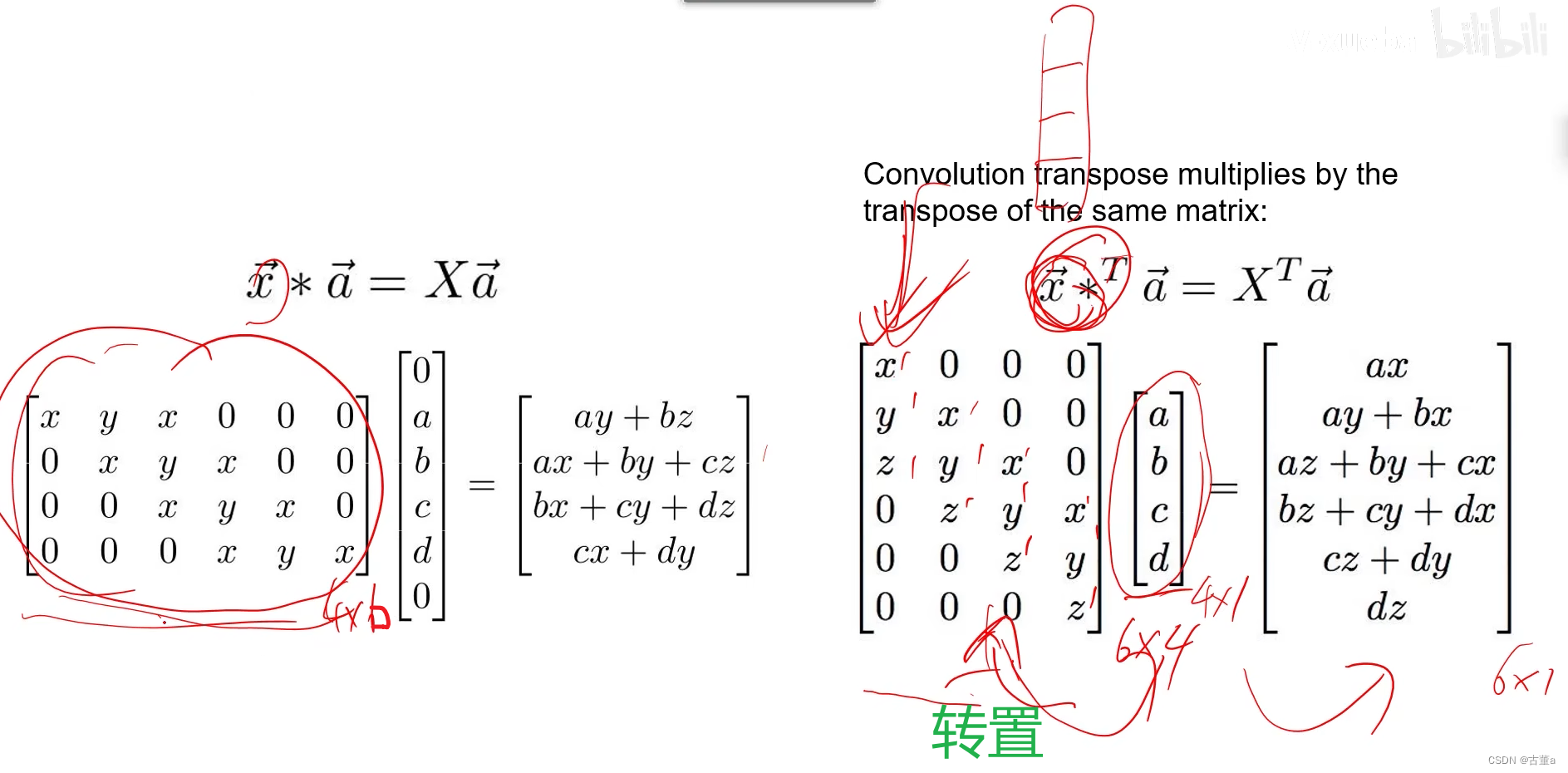
步长为2

UNET
上采样是根据下采样得到的高级语义得到的,但是有时候高级语义效果并不好,还需要使用低级语义。
针对这个问题,提出了Unet,将下采样过程中的低级语义整合到上采样过程中,从而使得效果更好。

-
相关阅读:
java112-simpledateformat进行格式化
Android基础第七天 | 字节跳动第四届青训营笔记
Java21-虚拟线程小试牛刀-meethigher
Qt实战案例(56)——利用QProcess实现应用程序重启功能
drools session理解
SpringMVC Day 10 : 拦截器
硬件工程师必备的35个资料网站
【vue-9】购物车案例
win11开机音效设置的方法
深入理解计算机系统:运行helloworld程序发生了什么?
- 原文地址:https://blog.csdn.net/m0_49683806/article/details/132995595