-
回归与聚类算法系列②:线性回归
目录
🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法,初步涉猎Python人工智能开发。
🦅主页:@逐梦苍穹
📕回归与聚类算法系列①:概念简述
🍔写在前面:本文当中所涉及到的正规方程和梯度下降的数学原理推导,后面写文章补上,同时也会在本文更新对应的跳转链接。
1、定义与公式
线性回归(Linear Regression)是一种用于建立输入特征(也称为自变量)与输出变量(也称为因变量)之间线性关系的统计学和机器学习方法。它的主要目标是找到一条最佳拟合直线(或平面,如果有多个特征)来描述这种关系,以便进行预测、分析和理解。
特点:只有一个自变量的情况称为单变量回归,大于一个自变量情况的叫做多元回归
通用公式为:

(其中的w和x也可以理解为:
 ,
, )
)线性回归性能评估->均方误差公式:

2、应用场景
线性回归是一种经典的机器学习方法,广泛应用于各种领域和场景中。以下是一些常见的线性回归应用场景:
- 房地产估价: 用于预测房屋价格,考虑特征如房屋大小、卧室数量、地理位置等。
- 金融预测: 用于预测股票价格、货币汇率、利率等金融市场的变化。
- 销售预测: 用于预测产品销售量,考虑特征如广告开支、促销活动等。
- 医学研究: 用于分析疾病和生命科学数据,以预测患者的健康状况或疾病风险。
- 社会科学: 用于分析社会经济数据,如收入与教育水平的关系、犯罪率的预测等。
- 环境科学: 用于预测气候变化、天气模式以及环境污染等因素。
- 运输与物流: 用于预测货物运输成本、运输时间等。
- 市场分析: 用于分析市场份额、产品定价策略和竞争对手的影响。
- 人力资源管理: 用于分析员工薪资、绩效评估和员工满意度。
- 教育研究: 用于预测学生的学术成绩,以了解教育政策和教学方法的效果。
- 质量控制: 用于监测生产过程,预测产品缺陷率并进行质量改进。
- 工程和物理学: 用于建立物理系统的数学模型,如电子电路、材料强度等。
- 客户满意度分析: 用于了解客户满意度与不同因素之间的关系,以改进产品和服务。
- 电信行业: 用于预测网络流量、用户需求和服务质量。
总之,线性回归是一个灵活的工具,适用于许多不同领域的数据分析和预测问题。它的优点包括简单易懂、易于解释和计算效率高,但也需要注意在某些情况下,线性关系假设可能不适用,因此需要谨慎使用和进一步验证。
3、特征与目标的关系分析
线性回归当中的关系有两种,一种是线性关系,另一种是非线性关系。
在这里我们只能画一个平面更好去理解,所以都用单个特征举例子。


注释:如果在单特征与目标值的关系呈直线关系,或者两个特征与目标值呈现平面的关系
更高维度的我们不用自己去想,记住这种关系即可

线性回归的损失函数
线性回归是一种基于最小二乘法的监督学习模型,用于预测数值型结果。它假设目标值与输入特征之间存在线性关系,并通过最小化预测值与实际值之间的均方误差来寻找最优解。
在线性回归中,通常使用均方误差(MSE)作为损失函数。
均方误差是实际值与预测值差的平方的平均值。
线性回归的目标是找到一组参数,使得这个损失函数的值最小。
为什么需要损失函数
线性回归需要损失函数的主要原因是它是一个监督学习问题,而损失函数的作用是衡量模型的预测值与实际观测值之间的差距,从而帮助我们评估模型的性能并找到最佳模型参数。
以下是损失函数在线性回归中的作用:
- 评估模型性能: 损失函数允许我们量化模型的性能。它测量模型的预测值与真实观测值之间的差异。一个好的模型应该使损失函数的值尽可能小,即预测值应该与真实值尽可能接近。通过损失函数,我们可以确定模型在训练数据上的表现如何。
- 建立优化目标: 损失函数定义了线性回归模型的优化目标。线性回归的目标是找到一组模型参数(
 ),使损失函数最小化。因此,优化模型的过程就是通过调整参数来最小化损失函数。
),使损失函数最小化。因此,优化模型的过程就是通过调整参数来最小化损失函数。 - 指导参数更新: 在梯度下降等优化算法中,损失函数的梯度告诉我们如何更新模型的参数。通过计算损失函数对参数的偏导数,我们可以确定参数应该朝哪个方向进行调整,以减小损失函数的值。这就是梯度下降算法中参数更新的基础。
- 提供反馈: 损失函数还为我们提供了有关模型预测的误差信息。如果损失函数的值较大,说明模型的预测与实际值相差较远,这可能表明模型需要进一步改进或数据中可能存在问题。通过分析损失函数,我们可以了解模型的哪些方面需要改进。
总之,损失函数在线性回归中起着至关重要的作用,它不仅用于评估模型性能,还用于定义模型的优化目标和指导参数更新的过程。
通过选择合适的损失函数,我们可以让模型学习到与实际观测值尽可能匹配的关系,从而实现线性回归的预测和解释目标。
最常见的线性回归损失函数是均方误差(MSE),但根据问题的性质,也可以选择其他损失函数。
损失函数
总损失的定义:

说明:
y_i为第i个训练样本的真实值
h(x_i)为第i个训练样本特征值组合预测函数
h_w(x)表示线性回归模型的预测结果,其中 w 是模型的权重参数(包括截距项和自变量的系数)
又称最小二乘法
⭐如何减少损失
线性回归的目标是通过调整模型的参数,使损失函数(通常是均方误差,MSE)最小化。为了减少损失,可以采取以下方法:
- 梯度下降法: 这是最常用的方法之一。梯度下降法通过计算损失函数关于模型参数的梯度(偏导数),然后按照梯度的反方向逐步更新参数,以减小损失函数的值。学习率是控制每次参数更新步长的超参数。梯度下降通常需要多次迭代,直到损失收敛到最小值或接近最小值。
- 正规方程法: 这是一种封闭解方法,可以直接求解出最佳参数值,而不需要迭代。正规方程法通过将损失函数关于参数的梯度设为零,然后求解参数的矩阵方程来找到最佳参数值。这种方法适用于小型数据集。
- 随机梯度下降法: 这是梯度下降法的一种变种,每次更新参数时只使用一个随机样本,而不是使用全部样本。这可以加速训练过程,特别是在大型数据集上。
- 批量梯度下降法: 与随机梯度下降相反,批量梯度下降每次更新参数时使用整个训练数据集。虽然这可能更稳定,但在大型数据集上可能需要更多时间和计算资源。
- 学习率调整: 学习率是梯度下降中的关键超参数。合适的学习率可以加快收敛速度,但过大的学习率可能导致不稳定的收敛,而过小的学习率可能需要更多的迭代才能收敛。可以尝试不同的学习率来找到最佳值。
- 特征工程: 仔细选择和处理自变量(特征)可以改善模型的性能。有时,添加、删除或变换特征可以降低损失函数,使模型更好地拟合数据。
- 复杂度调整: 在某些情况下,减小模型的复杂度,例如减少自变量的数量或使用正则化技术,可以减小过拟合风险,从而降低损失。
- 检查异常值: 异常值(outliers)可能会对模型的性能产生不利影响。检测并处理异常值是减少损失的一种重要方式。
通过以上方法,可以逐步减少线性回归模型的损失,使其更好地拟合数据,提高预测性能。选择合适的方法和调整参数需要根据具体问题和数据集进行调试和优化。
4、优化算法
如何去求模型当中的W,使得损失最小?(目的是找到最小损失对应的W值)
线性回归经常使用的两种优化算法:正规方程和梯度下降
正规方程
公式:
 (这个公式后续出文章详细推导)
(这个公式后续出文章详细推导)理解:X为特征值矩阵,y为目标值矩阵。直接求到最好的结果
缺点:当特征过多过复杂时,求解速度太慢并且得不到结果

梯度下降


这两个公式用于更新斜率w:
- w:表示斜率,即自变量 x 对因变量的影响。
- α:学习率,需要手动指定(超参数),控制参数更新的步长。α旁边的整体表示方向,沿着这个函数下降的方向找,最后就能找到山谷的最低点,然后更新W值
 :损失函数,通常是均方误差(MSE)或其他用于衡量模型拟合质量的函数。
:损失函数,通常是均方误差(MSE)或其他用于衡量模型拟合质量的函数。 :这是损失函数关于
:这是损失函数关于 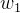 的偏导数,它告诉我们损失函数在 方向上的变化率。
的偏导数,它告诉我们损失函数在 方向上的变化率。
更新公式的含义是:通过计算损失函数关于斜率的梯度(偏导数),然后将其乘以学习率,最后从当前的斜率中减去这个值,以使损失函数逐渐减小。这个过程会一直重复,直到达到收敛条件。
这两个公式描述了梯度下降算法的核心原理:
通过不断计算损失函数关于模型参数的梯度,然后使用学习率控制更新步长,逐渐调整模型参数,以减小损失函数的值,从而找到最佳模型参数。
这是一种迭代的优化方法,通常用于训练线性回归等机器学习模型。
面对训练数据规模十分庞大的任务 ,能够找到较好的结果


所以有了梯度下降这样一个优化算法,回归就有了"自动学习"的能力
优化动态图

偏导
在机器学习和优化问题中,需要求偏导数的主要原因是为了找到损失函数或目标函数相对于模型参数的变化率。这对于梯度下降等优化算法至关重要。以下是为什么需要求偏导数的一些关键原因:
- 寻找最优解: 机器学习模型的训练和优化过程的核心目标通常是找到最小化损失函数或最大化目标函数的参数。偏导数告诉我们在参数空间中,损失函数或目标函数朝哪个方向变化最快。通过沿着梯度的反方向更新参数,可以逐步逼近最优解。
- 梯度下降优化: 梯度下降是一种常用的优化算法,它使用损失函数关于参数的梯度来指导参数的更新。梯度是一个向量,其中每个分量对应一个参数,表示了在该参数方向上的变化率。通过梯度下降,可以沿着梯度的反方向调整参数,以减小损失函数的值。
- 局部最优解: 机器学习问题通常是高维的,存在许多局部最优解。偏导数告诉我们当前位置附近的最陡峭下降方向,帮助我们避免陷入局部最优解并找到全局最优解。
- 学习速度: 学习率(learning rate)是梯度下降中的一个重要超参数,它决定了每次参数更新的步长。偏导数告诉我们在每个参数方向上的梯度大小,从而帮助选择合适的学习率,避免更新步长过大或过小。
- 正则化: 在一些情况下,需要对模型参数进行正则化,以防止过拟合。正则化项的导数也需要计算,并与损失函数的导数相结合,以影响参数更新。
总之,求偏导数是优化问题和机器学习中的关键步骤,它提供了关于参数变化的重要信息,指导模型的参数更新,帮助找到最优解,提高模型性能。梯度下降等优化算法的核心思想就是利用偏导数来更新参数,从而不断优化模型。
正规方程和梯度下降比较

特点
正规方程
梯度下降
原理
解析求解,直接计算参数
迭代优化,通过梯度调整参数
计算复杂度
O(n^2) 到 O(n^3)
O(k * n * iter)
内存需求
较大(需要整个特征矩阵)
相对较小(一小批次数据)
稳定性
对条件数敏感
通常较稳定
适用性
适用于小到中型数据集
适用于各种规模的数据集
全局最优解
直接找到全局最优解
收敛到局部最优解
选择:
小规模数据:
LinearRegression(不能解决拟合问题)
岭回归
大规模数据:SGDRegressor
5、优化方法GD、SGD、SAG
梯度下降(Gradient Descent,GD)、随机梯度下降(Stochastic Gradient Descent,SGD)和随机平均梯度(Stochastic Average Gradient,SAG)都是优化算法,用于找到损失函数的最小值,通常在机器学习和深度学习中用于训练模型。
梯度下降(Gradient Descent),原始的梯度下降法需要计算所有样本的值才能够得出梯度,计算量大,所以后面才有会一系列的改进。
以下是关于这些优化方法的详细信息:
- 梯度下降 (Gradient Descent,GD):
- 原理: GD是一种迭代优化算法,通过计算损失函数关于参数的梯度(导数),然后以梯度的反方向更新参数,以减小损失函数的值。
- 优点: 理论上可以收敛到全局最优解(如果学习率足够小且损失函数是凸的)。
- 缺点: 对于大规模数据集,计算整个数据集的梯度可能很昂贵。此外,GD可能陷入局部最优解,学习率的选择也很关键。
- 随机梯度下降 (Stochastic Gradient Descent,SGD):
- 原理: SGD与GD类似,但每次迭代只使用一个随机样本(或小批量样本)来计算梯度和更新参数。因此,它更快但更不稳定。
- 优点: 更快的收敛速度,对于大型数据集更具可扩展性,更容易实现。
- 缺点: 随机性可能导致震荡和不稳定的收敛,学习率需要精细调整。不容易收敛到全局最优解。SGD需要很多超参数(比如正则项参数、迭代数 等),并且SGD对于特征标准化是敏感的。
- 随机平均梯度 (Stochastic Average Gradient,SAG):
- 原理: SAG是一种改进版的SGD,它在每次迭代中仅使用一个样本,并且维护了一个平均梯度,以减小随机性。
- 优点: 在具有平滑损失函数的情况下,SAG通常比SGD更稳定,且不需要精细调整学习率。收敛速度通常比SGD慢但快于GD。
- 缺点: 需要维护平均梯度,可能对内存要求较高。
随机平均梯度法(Stochasitc Average Gradient),由于收敛的速度太慢,有人提出SAG等基于梯度下降的算法
Scikit-learn:SGDRegressor、岭回归、逻辑回归等当中都会有SAG优化
这些优化方法在不同情况下表现出不同的性能。通常,SGD和SAG更适合大规模数据集,因为它们的计算成本较低。在深度学习中,通常使用各种变种,如Mini-batch SGD,Adam,RMSprop等,以更好地平衡速度和稳定性,并加速收敛。
选择合适的优化方法通常取决于问题的性质、数据集大小、计算资源和超参数的选择。在实际应用中,通常需要进行超参数调整和实验来找到最佳的优化方法。
6、⭐线性回归API
sklearn提供了两种实现的API, 可以根据选择使用:
- sklearn.linear_model.LinearRegression(fit_intercept=True)
- 通过正规方程优化
- fit_intercept:是否计算偏置
- LinearRegression.coef_:回归系数
- LinearRegression.intercept_:偏置
- sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate ='invscaling', eta0=0.01)
- SGDRegressor类实现了随机梯度下降学习,它支持不同的loss函数和正则化惩罚项来拟合线性回归模型。
- loss:损失类型
- loss="squared_loss": 普通最小二乘法
- fit_intercept:是否计算偏置
- learning_rate : string, optional
- 学习率填充
- 'constant': eta = eta0
- 'optimal': eta = 1.0 / (alpha * (t + t0)) [default]
- 'invscaling': eta = eta0 / pow(t, power_t)
- power_t=0.25:存在父类当中
- 对于一个常数值的学习率来说,可以使用learning_rate='constant',并使用eta0来指定学习率。
- SGDRegressor.coef_:回归系数
- SGDRegressor.intercept_:偏置
7、实例:波士顿房价预测
数据介绍
实例所需要的数据集,可以直接使用sklearn当中现有的。


给定的这些特征,是专家们得出的影响房价的结果属性。
目前只需要使用这些特征。到后面量化很多特征需要我们自己去寻找
分析
回归当中的数据大小不一致,是否会导致结果影响较大。所以需要做标准化处理。同时我们对目标值也需要做标准化处理。
- 数据分割与标准化处理
- 回归预测
- 线性回归的算法效果评估
回归性能评估
均方误差(Mean Squared Error)MSE)评价机制:
(
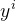 为预测值,
为预测值,  为真实值)
为真实值)⭐均方误差API
sklearn.metrics.mean_squared_error(y_true, y_pred)
均方误差回归损失
y_true:真实值
y_pred:预测值
return:浮点数结果
🔺代码
正规方程
- # -*- coding: utf-8 -*-
- # @Author:︶ㄣ释然
- # @Time: 2023/9/6 10:37
- import warnings
- from sklearn.datasets import load_boston
- from sklearn.linear_model import LinearRegression, SGDRegressor
- from sklearn.metrics import mean_squared_error
- from sklearn.model_selection import train_test_split
- from sklearn.preprocessing import StandardScaler
- '''
- sklearn.linear_model.LinearRegression(fit_intercept=True)
- 通过正规方程优化
- fit_intercept:是否计算偏置
- LinearRegression.coef_:回归系数
- LinearRegression.intercept_:偏置
- '''
- def normal_equation():
- """
- 正规方程的优化方法对波士顿房价进行预测
- :return:
- """
- # 1)获取数据
- boston = load_boston()
- # 2)划分数据集
- x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
- # 3)标准化
- transfer = StandardScaler()
- x_train = transfer.fit_transform(x_train)
- x_test = transfer.transform(x_test)
- # 4)预估器
- estimator = LinearRegression()
- estimator.fit(x_train, y_train)
- # 5)得出模型
- print("正规方程-权重系数为:\n", estimator.coef_)
- print("正规方程-偏置为:\n", estimator.intercept_)
- # 6)模型评估
- y_predict = estimator.predict(x_test)
- print("预测房价:\n", y_predict)
- error = mean_squared_error(y_test, y_predict)
- print("正规方程-均方误差为:\n", error)
- if __name__ == '__main__':
- warnings.filterwarnings("ignore")
- normal_equation()
梯度下降
- # -*- coding: utf-8 -*-
- # @Author:︶ㄣ释然
- # @Time: 2023/9/6 10:37
- import warnings
- from sklearn.datasets import load_boston
- from sklearn.linear_model import SGDRegressor
- from sklearn.metrics import mean_squared_error
- from sklearn.model_selection import train_test_split
- from sklearn.preprocessing import StandardScaler
- '''
- sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate ='invscaling', eta0=0.01)
- SGDRegressor类实现了随机梯度下降学习,它支持不同的loss函数和正则化惩罚项来拟合线性回归模型。
- loss:损失类型
- loss="squared_loss": 普通最小二乘法
- fit_intercept:是否计算偏置
- learning_rate : string, optional
- 学习率填充
- 'constant': eta = eta0
- 'optimal': eta = 1.0 / (alpha * (t + t0)) [default]
- 'invscaling': eta = eta0 / pow(t, power_t)
- power_t=0.25:存在父类当中
- 对于一个常数值的学习率来说,可以使用learning_rate='constant',并使用eta0来指定学习率。
- SGDRegressor.coef_:回归系数
- SGDRegressor.intercept_:偏置
- '''
- def gradient_descent():
- """
- 梯度下降的优化方法对波士顿房价进行预测
- """
- # 1)获取数据
- boston = load_boston()
- print("特征数量:\n", boston.data.shape)
- # 2)划分数据集
- x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
- # 3)标准化
- transfer = StandardScaler()
- x_train = transfer.fit_transform(x_train)
- x_test = transfer.transform(x_test)
- # 4)预估器
- estimator = SGDRegressor(learning_rate="constant", eta0=0.01, max_iter=10000, penalty="l1")
- estimator.fit(x_train, y_train)
- # 5)得出模型
- print("梯度下降-权重系数为:\n", estimator.coef_)
- print("梯度下降-偏置为:\n", estimator.intercept_)
- # 6)模型评估
- y_predict = estimator.predict(x_test)
- print("预测房价:\n", y_predict)
- error = mean_squared_error(y_test, y_predict)
- print("梯度下降-均方误差为:\n", error)
- if __name__ == '__main__':
- warnings.filterwarnings("ignore")
- gradient_descent()
🍁写在最后:您的三连支持,是我创作的最大动力🌹
-
相关阅读:
基于FPGA的图像缩小算法实现,包括tb测试文件和MATLAB辅助验证
Kubernetes集群部署Node Feature Discovery组件用于检测集群节点特性
HBuilderX自定义编辑器代码颜色
【Spring Boot】如何集成Redis
【计算机网络】—网络编程(socket)02
Deep learning of free boundary and Stefan problems论文阅读复现
【数据库编程-SQLite3(二)】API-增删改查基础函数-(含源码)
电源控制系统架构(PCSA)电源控制挑战
RabbitMQ、RocketMQ、Kafka常见消息队列不得不知道的事
C语言中一维指针、二维指针和三维指针
- 原文地址:https://blog.csdn.net/qq_60735796/article/details/132741930
