前言#
本篇其实是承接前面两篇的,都是讲定位线上的c3p0数据库连接池,发生连接泄露的问题。
第二篇讲到,可以配置两个参数,来找出是哪里的代码借了连接后没有归还。但是,在我这边的情况是,对于没有归还的连接,借用者的堆栈确实是打印到日志了,但是我在本地模拟的时候,发现其实这些场景是有归还连接的,所以,我开始怀疑不是代码问题。
不是业务代码问题,能是啥问题呢?我们先来看看连接是怎么归还到连接池的。
连接的实际类型#
我在本地debug了下,发现获取连接时,代码如下:
com.mchange.v2.c3p0.impl.AbstractPoolBackedDataSource#getConnection()
public Connection getConnection() throws SQLException
{
// javax.sql.PooledConnection,实际类型为com.mchange.v2.c3p0.impl.NewPooledConnection
PooledConnection pc = getPoolManager().getPool().checkoutPooledConnection();
return pc.getConnection();
}
说实话,之前都没注意到jdbc api里还有javax.sql.PooledConnection这个类,这里,就是首先从c3p0连接池获取了一个com.mchange.v2.c3p0.impl.NewPooledConnection对象,然后转换为javax.sql.PooledConnection。
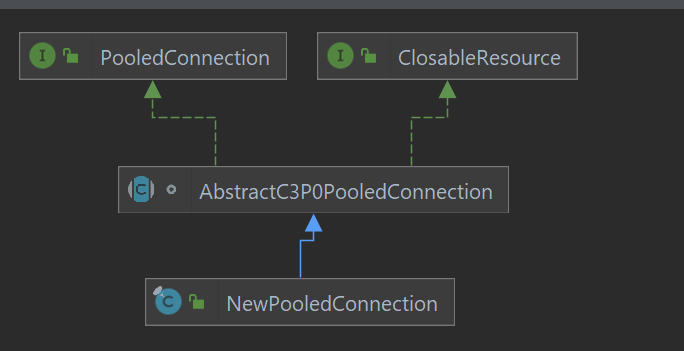
然后,调用javax.sql.PooledConnection#getConnection,会返回给实际类型为com.mchange.v2.c3p0.impl.NewProxyConnection的对象。
com.mchange.v2.c3p0.impl.NewPooledConnection#getConnection
public synchronized Connection getConnection() throws SQLException
{
if ( exposedProxy == null )
{
exposedProxy = new NewProxyConnection( physicalConnection, this );
}
return exposedProxy;
}
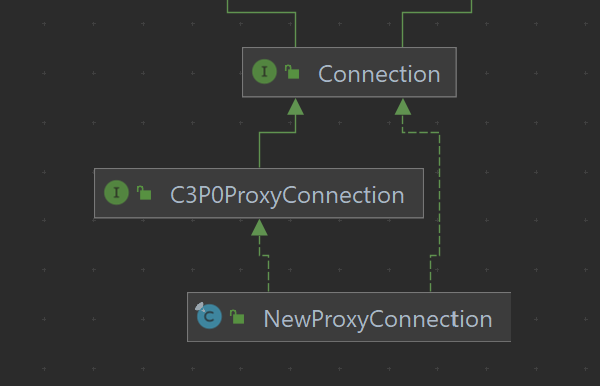
在该类中,主要包含如下几个字段:
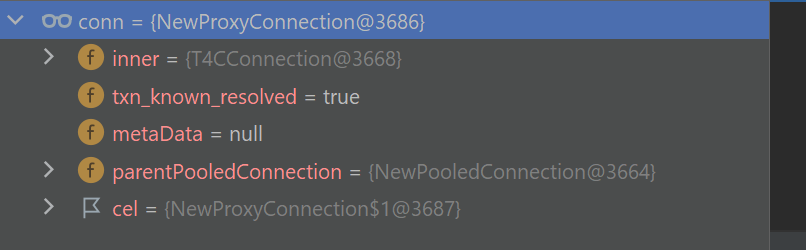
inner:实际的底层连接,如我这里,其类型为oracle.jdbc.driver.T4CConnection
parentPooledConnection:javax.sql.PooledConnection类型的池化连接
cel:类型为ConnectionEventListener,就是一个监听器
connection.close方法逻辑#
com.mchange.v2.c3p0.impl.NewProxyConnection
public synchronized void close() throws SQLException {
// 0
if (!this.isDetached()) {
// 1
NewPooledConnection npc = this.parentPooledConnection;
this.detach();
// 2
npc.markClosedProxyConnection(this, this.txn_known_resolved);
this.inner = null;
}
}
0处,检查该对象是否已经和底层的池化连接解绑:
boolean isDetached() {
return this.parentPooledConnection == null;
}
1处,通过parentPooledConnection获取到NewPooledConnection类型的池化连接,然后和池化连接解绑:
private void detach() {
this.parentPooledConnection.removeConnectionEventListener(this.cel);
this.parentPooledConnection = null;
}
2处,调用池化连接的方法,进行清理:
void markClosedProxyConnection( NewProxyConnection npc, boolean txn_known_resolved )
{
// 2.1
List closeExceptions = new LinkedList();
// 2.2
cleanupResultSets( closeExceptions );
cleanupUncachedStatements( closeExceptions );
checkinAllCachedStatements( closeExceptions );
// 2.3
if ( closeExceptions.size() > 0 )
{
...
// 打印异常
}
reset( txn_known_resolved );
exposedProxy = null; //volatile
// 2.4
fireConnectionClosed();
}
2.1处,建个list,用来收集清理过程中的各种异常;
2.2处,清理ResultSet、Statement等
2.3处,打印异常
2.4处,通知监听者:
private void fireConnectionClosed()
{
ces.fireConnectionClosed();
}
然后进入:
ConnectionEvent evt = new ConnectionEvent(source);
for (Iterator i = mlCopy.iterator(); i.hasNext();)
{
ConnectionEventListener cl = (ConnectionEventListener) i.next();
// 1 调用listener的方法
cl.connectionClosed(evt);
}
// com.mchange.v2.c3p0.impl.C3P0PooledConnectionPool.ConnectionEventListenerImpl#connectionClosed
public void connectionClosed(final ConnectionEvent evt)
{
doCheckinResource( evt );
}
然后如下方法被调用:
private void doCheckinResource(ConnectionEvent evt)
{
// rp: com.mchange.v2.resourcepool.BasicResourcePool
rp.checkinResource( evt.getSource() );
}
这里rp就是资源池,这里就会向资源池归还连接。
内部的实现如下:
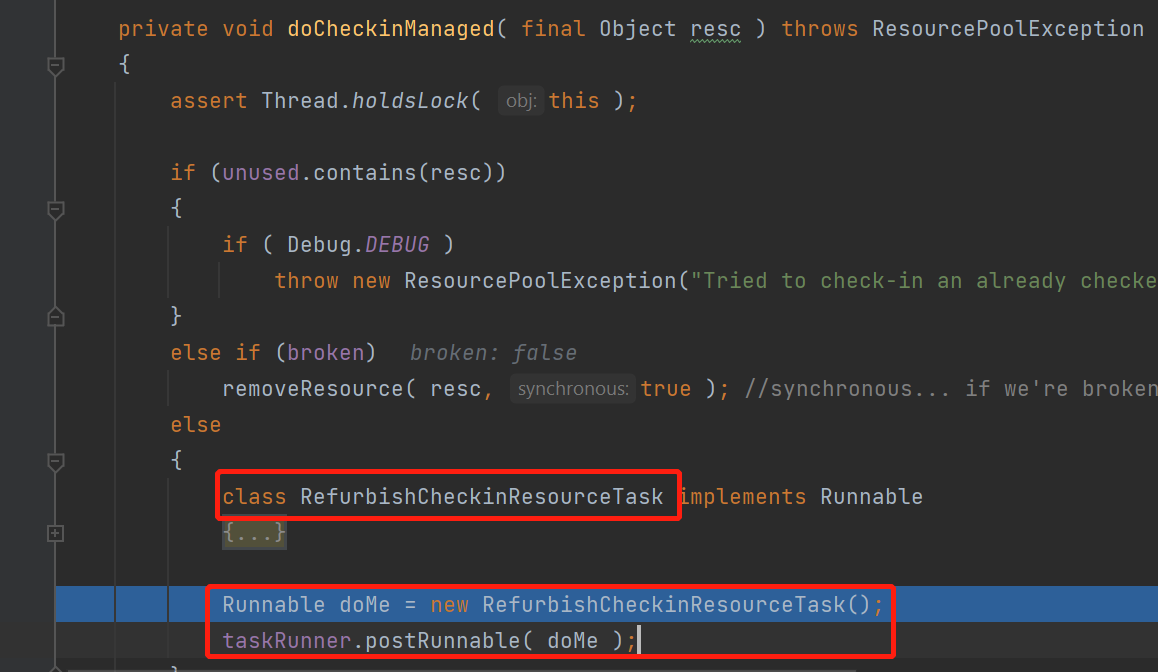
这里是定义了一个内部类RefurbishCheckinResourceTask,内部类实现了Runnable,然后new了一个实例,丢给了taskRunner,进行异步归还。
这个task的逻辑:
class RefurbishCheckinResourceTask implements Runnable
{
public void run()
{
// 1 检查资源是否ok
boolean resc_okay = attemptRefurbishResourceOnCheckin( resc );
synchronized( BasicResourcePool.this )
{
PunchCard card = (PunchCard) managed.get( resc );
// 2 如果资源ok,归还到unused空闲链表,更新卡片
if ( resc_okay && card != null)
{
// 2.1 归还到unused空闲链表
unused.add(0, resc );
// 2.2 更新卡片的归还时间为当前时间、借出时间为-1,表示未借出
card.last_checkin_time = System.currentTimeMillis();
card.checkout_time = -1;
}
else
{
if (card != null)
card.checkout_time = -1;
// 连接是坏的,那就把这个连接毁灭
removeResource( resc );
ensureMinResources();
}
BasicResourcePool.this.notifyAll();
}
}
}
这里归还连接,可以看到,是new了一个runnable,丢给线程池去异步执行,但是,异步执行,不是很稳啊,比如,如果此时线程池里的线程,都卡住了,没法处理task,怎么办呢?
线上日志出现APPARENT DEADLOCK字样#
问题描述#
如果你去搜索引擎查APPARENT DEADLOCK,会搜到很多,说明这些年,大家还是被这个问题困扰了挺久
我们这边,每次出现这个连接泄露问题时,貌似都伴随着这个日志,这个日志大概长下面这样:
06-08 17:00:30,119[Timer-5][][c.ThreadPoolAsynchronousRunner:608][WARN]-com.mchange.v2.async.ThreadPoolAsynchronousRunner$DeadlockDetector@3cf46c2 -- APPARENT DEADLOCK!!! Creating emergency threads for unassigned pending tasks!
06-08 17:00:30,121[Timer-5][][c.ThreadPoolAsynchronousRunner:624][WARN]-com.mchange.v2.async.ThreadPoolAsynchronousRunner$DeadlockDetector@3cf46c2 -- APPARENT DEADLOCK!!! Complete Status:
Managed Threads: 3
Active Threads: 3
Active Tasks:
com.mchange.v2.resourcepool.BasicResourcePool$AcquireTask@b451b27 (com.mchange.v2.async.ThreadPoolAsynchronousRunner$PoolThread-#0)
com.mchange.v2.resourcepool.BasicResourcePool$AcquireTask@65f9a338 (com.mchange.v2.async.ThreadPoolAsynchronousRunner$PoolThread-#1)
com.mchange.v2.resourcepool.BasicResourcePool$AcquireTask@684ae5d5 (com.mchange.v2.async.ThreadPoolAsynchronousRunner$PoolThread-#2)
Pending Tasks:
com.mchange.v2.resourcepool.BasicResourcePool$AcquireTask@d373871
com.mchange.v2.resourcepool.BasicResourcePool$AcquireTask@245a897e
com.mchange.v2.resourcepool.BasicResourcePool$DestroyResourceTask@33f8c1d7
com.mchange.v2.resourcepool.BasicResourcePool$AcquireTask@107e24e9
Pool thread stack traces:
Thread[com.mchange.v2.async.ThreadPoolAsynchronousRunner$PoolThread-#0,5,main]
java.net.SocketInputStream.socketRead0(Native Method)
java.net.SocketInputStream.read(SocketInputStream.java:152)
java.net.SocketInputStream.read(SocketInputStream.java:122)
oracle.net.ns.Packet.receive(Packet.java:300)
oracle.net.ns.DataPacket.receive(DataPacket.java:106)
oracle.net.ns.NetInputStream.getNextPacket(NetInputStream.java:315)
oracle.net.ns.NetInputStream.read(NetInputStream.java:260)
oracle.net.ns.NetInputStream.read(NetInputStream.java:185)
oracle.net.ns.NetInputStream.read(NetInputStream.java:102)
oracle.jdbc.driver.T4CSocketInputStreamWrapper.readNextPacket(T4CSocketInputStreamWrapper.java:124)
oracle.jdbc.driver.T4CSocketInputStreamWrapper.read(T4CSocketInputStreamWrapper.java:80)
oracle.jdbc.driver.T4CMAREngine.unmarshalUB1(T4CMAREngine.java:1137)
oracle.jdbc.driver.T4CTTIfun.receive(T4CTTIfun.java:290)
oracle.jdbc.driver.T4CTTIfun.doRPC(T4CTTIfun.java:192)
oracle.jdbc.driver.T4CTTIoauthenticate.doOSESSKEY(T4CTTIoauthenticate.java:404)
oracle.jdbc.driver.T4CConnection.logon(T4CConnection.java:385)
oracle.jdbc.driver.PhysicalConnection.<init>(PhysicalConnection.java:546)
oracle.jdbc.driver.T4CConnection.<init>(T4CConnection.java:236)
oracle.jdbc.driver.T4CDriverExtension.getConnection(T4CDriverExtension.java:32)
oracle.jdbc.driver.OracleDriver.connect(OracleDriver.java:521)
com.mchange.v2.c3p0.DriverManagerDataSource.getConnection(DriverManagerDataSource.java:134)
com.mchange.v2.c3p0.WrapperConnectionPoolDataSource.getPooledConnection(WrapperConnectionPoolDataSource.java:182)
com.mchange.v2.c3p0.WrapperConnectionPoolDataSource.getPooledConnection(WrapperConnectionPoolDataSource.java:171)
com.mchange.v2.c3p0.impl.C3P0PooledConnectionPool$1PooledConnectionResourcePoolManager.acquireResource(C3P0PooledConnectionPool.java:137)
com.mchange.v2.resourcepool.BasicResourcePool.doAcquire(BasicResourcePool.java:1014)
com.mchange.v2.resourcepool.BasicResourcePool.access$800(BasicResourcePool.java:32)
com.mchange.v2.resourcepool.BasicResourcePool$AcquireTask.run(BasicResourcePool.java:1810)
com.mchange.v2.async.ThreadPoolAsynchronousRunner$PoolThread.run(ThreadPoolAsynchronousRunner.java:547)
线程池中的task类型#
我们有提到,有很多事情都是丢给线程池异步执行的,比如main线程初始化连接时,main并不会自己去创建连接,而是new几个task,丢给线程池并行执行,然后main线程在那边等待。
主要有这么几种task:
-
com.mchange.v2.resourcepool.BasicResourcePool.AcquireTask
获取数据库连接,和底层db driver打交道,如mysql、oracle的driver
-
com/mchange/v2/resourcepool/BasicResourcePool.java:959
这个方法内,定义了一个内部class,这个
DestroyResourceTask就是用来销毁底层连接private void destroyResource(final Object resc, boolean synchronous) { class DestroyResourceTask implements Runnable { -
com.mchange.v2.resourcepool.BasicResourcePool#doCheckinManaged中的内部类:
class RefurbishCheckinResourceTask implements Runnable
这个类很重要,前面已经讲到了,归还连接的时候,就会生成这个task异步执行
-
com.mchange.v2.resourcepool.BasicResourcePool.AsyncTestIdleResourceTask#AsyncTestIdleResourceTask
这个类,主要是测试那些空闲时间太长的资源,看看是不是还ok,不ok的话,会及时销毁
-
com.mchange.v2.resourcepool.BasicResourcePool.RemoveTask
连接池缩容的时候需要,比如现在有20个连接,我们配置的min为10,那么多出的10个连接会被销毁
这里面,有好几个都是要和db通信的,如AcquireTask、DestroyResourceTask、AsyncTestIdleResourceTask,通信就有可能超时,长时间超时就可能阻塞当前的线程,接下来,我们就看看这些线程有没有被阻塞的可能。
线程池是如何执行task的#
线程池的创建如下:
private ThreadPoolAsynchronousRunner( int num_threads,
boolean daemon,
int max_individual_task_time,
int deadlock_detector_interval,
int interrupt_delay_after_apparent_deadlock,
Timer myTimer,
boolean should_cancel_timer )
{
this.num_threads = num_threads;
this.daemon = daemon;
this.max_individual_task_time = max_individual_task_time;
this.deadlock_detector_interval = deadlock_detector_interval;
this.interrupt_delay_after_apparent_deadlock = interrupt_delay_after_apparent_deadlock;
this.myTimer = myTimer;
this.should_cancel_timer = should_cancel_timer;
// 创建线程池
recreateThreadsAndTasks();
myTimer.schedule( deadlockDetector, deadlock_detector_interval, deadlock_detector_interval );
}
private void recreateThreadsAndTasks()
{
// 如果线程池已经存在,则先销毁
if ( this.managed != null)
{
Date aboutNow = new Date();
for (Iterator ii = managed.iterator(); ii.hasNext(); )
{
PoolThread pt = (PoolThread) ii.next();
pt.gentleStop();
stoppedThreadsToStopDates.put( pt, aboutNow );
ensureReplacedThreadsProcessing();
}
}
// 创建线程池
this.managed = new HashSet();
this.available = new HashSet();
this.pendingTasks = new LinkedList();
for (int i = 0; i < num_threads; ++i)
{
// 线程type为com.mchange.v2.async.ThreadPoolAsynchronousRunner.PoolThread
Thread t = new PoolThread(i, daemon);
managed.add( t );
available.add( t );
t.start();
}
}
线程的执行逻辑:
// 1
boolean should_stop;
LinkedList pendingTasks;
while (true)
{
Runnable myTask;
synchronized ( ThreadPoolAsynchronousRunner.this )
{
while ( !should_stop && pendingTasks.size() == 0 )
ThreadPoolAsynchronousRunner.this.wait( POLL_FOR_STOP_INTERVAL );
// 2
if (should_stop)
break thread_loop;
// 3
myTask = (Runnable) pendingTasks.remove(0);
currentTask = myTask;
}
try
{ // 4
if (max_individual_task_time > 0)
setMaxIndividualTaskTimeEnforcer();
// 5
myTask.run();
}
...
}
1处,在线程中定义了一个标志,如果这个标志为true,线程检测到,会停止执行;
2处,检测标志;
3处,从任务列表摘取任务;
4处,如果max_individual_task_time大于0,可以启动一个max_individual_task_time秒后中断当前线程的timer
private void setMaxIndividualTaskTimeEnforcer()
{
this.maxIndividualTaskTimeEnforcer = new MaxIndividualTaskTimeEnforcer( this );
myTimer.schedule( maxIndividualTaskTimeEnforcer, max_individual_task_time );
}
5处,执行任务。
但是,我们说,5处是执行任务,从我们日志(前面的APPARENT DEADLOCK日志的堆栈)就能发现,5处执行任务时,貌似卡死了,等待db返回数据,结果好像db一直不返回。
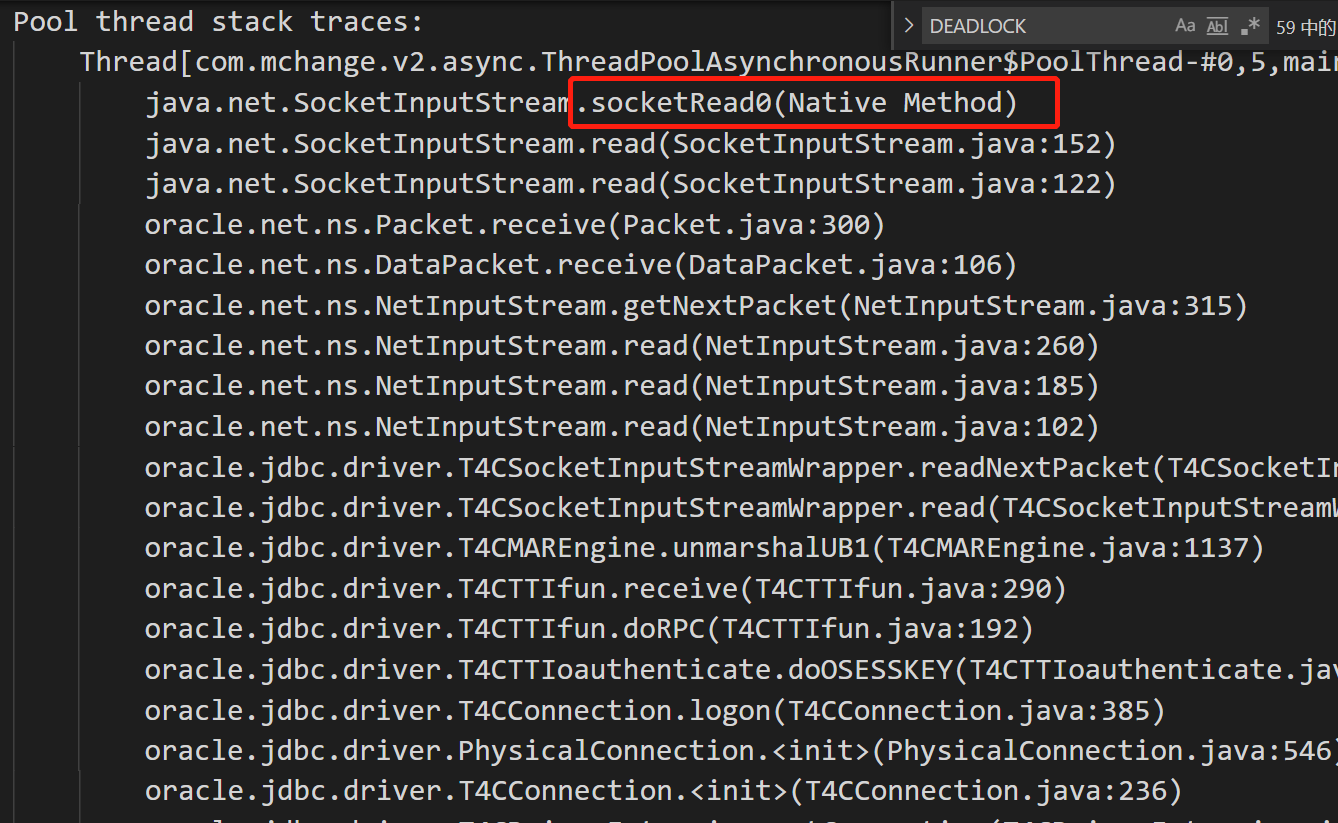
这里一旦长时间卡住,就会导致线程池没法继续运行其他task,包括:归还连接到连接池的task、获取新连接的task等。无法执行归还连接的task,就会导致连接池中连接耗尽,看起来就像是发生了连接泄露一样。
那么,作为一个那时候的流行框架,作者是怎么解决这个问题呢?
线程卡死场景的检测#
其实这个就是要讲的com.mchange.v2.async.ThreadPoolAsynchronousRunner.DeadlockDetector,也就是那个会打印死锁日志的线程。
TimerTask deadlockDetector = new DeadlockDetector();
class DeadlockDetector extends TimerTask
这个task会定时执行,因为它是一个java.util.TimerTask。
// com.mchange.v2.async.ThreadPoolAsynchronousRunner#ThreadPoolAsynchronousRunner
// 在构造函数中,就会使用timer开启对这个timerTask的周期调度
myTimer.schedule( deadlockDetector, deadlock_detector_interval, deadlock_detector_interval );
默认情况下,没做额外配置的话,这个deadlock_detector_interval一般是10s,也就是10s执行一次,后面再讲怎么修改这个值。
这个task,每次被调度的时候,都干些啥呢?
我先简单说一下,主要就是检测线程池里的线程是不是出了问题,比如,被没有超时时间的阻塞调用给卡死了,hang住了。我们想想,线程卡死了之后,现象是啥?线程是要处理任务的,如果它卡死了,那么待处理的任务列表就会一直不变。(按理说,也可能越积越多,但是,作者的检测思路就是,上一次调度时候的待处理任务链表,和本次调度时,待处理任务链表,一模一样,就认为发生了死锁。)
如果按照作者的算法,发生了线程全部hang死(也就是他说的死锁),此时,会进行以下动作:
-
将这些线程的
boolean should_stop;标志设为true,如果这些线程没完全hang死,还能动的话,看到这个标志,就会自行结束 -
把这些线程存到一个map,key是线程,value是当前时间
Date aboutNow = new Date(); for (Iterator ii = managed.iterator(); ii.hasNext(); ) { PoolThread pt = (PoolThread) ii.next(); // 设置boolean should_stop;为true pt.gentleStop(); // 存放到待结束线程的map stoppedThreadsToStopDates.put( pt, aboutNow ); // ensureReplacedThreadsProcessing(); } -
上面的
ensureReplacedThreadsProcessing启动一个timerTask。private void ensureReplacedThreadsProcessing() { this.replacedThreadInterruptor = new ReplacedThreadInterruptor(); int replacedThreadProcessDelay = interrupt_delay_after_apparent_deadlock / 4; myTimer.schedule( replacedThreadInterruptor, replacedThreadProcessDelay, replacedThreadProcessDelay ); } -
这个timerTask每
interrupt_delay_after_apparent_deadlock/4执行一次,这个interrupt_delay_after_apparent_deadlock就是个时间值,默认是60s,也就是说,默认15s执行一次timerTask,这个timerTask的职责是:com.mchange.v2.async.ThreadPoolAsynchronousRunner.ReplacedThreadInterruptor class ReplacedThreadInterruptor extends TimerTask { public void run() { synchronized (ThreadPoolAsynchronousRunner.this) { processReplacedThreads(); } } }检测那个线程map里的每个线程,如果当前最新的时间 - 线程停止时(也就是打上should_stop标记)的时间,大于60s(
interrupt_delay_after_apparent_deadlock默认值),就调用这些线程的interrupt方法,大家知道,java.lang.Thread#interrupt可以让线程从阻塞操作中醒过来,也就相当于让线程强制结束运行。 -
重建几个新的线程:
this.managed = new HashSet(); this.available = new HashSet(); this.pendingTasks = new LinkedList(); for (int i = 0; i < num_threads; ++i) { Thread t = new PoolThread(i, daemon); managed.add( t ); available.add( t ); t.start(); } -
我们这个场景,是由于线程hang死,那么,可能积压了非常多的任务要执行,所以,这里要临时创建一些线程来负责这些任务:
// 这里的current就是指向积压的任务 current = (LinkedList) pendingTasks.clone();
这里会紧急创建10个线程出来,然后将这些积压的任务全部丢给这个新创建的线程池来执行。
- 执行完上述操作后,线程池中已经全都是新的线程,60s后,老的线程被interrupt,走向其生命尽头
按照上述分析,每次执行完这个TimerTask的逻辑后,老的线程会马上打上should_stop标记,60s(interrupt_delay_after_apparent_deadlock)后会被强制interrupe。
会新创建n个线程来执行后续任务。至于积压的任务,会临时创建紧急线程池来执行。
看起来,大的逻辑倒是没啥大问题,至于有没有一些细节上的多线程问题,这个不能确定。
一些疑问#
按理说,在日志中出现了APPARENT DEADLOCK字样后,如果执行没问题的话,新的线程就建立起来了,后续的请求,再需要获取连接,就会在新的线程中执行,如果这时候后台db是ok的,那么就可以获取到新的连接来执行sql了。
但我们这边显示,后续还是不断地报错,是不是说明新的线程中执行任务(如获取连接那些),马上又hang住了呢?
那就是说,db有问题的话,这个机制也起不了太大作用,还是不断hang死,当然,这也说得过去,毕竟后台db有问题,连接获取困难的话,程序怎么好的了呢?
由于程序中日志很匮乏,只打开了某几个logger的INFO级别,其他logger都是ERROR,所以没法完全确定问题所在。
至于为啥logger都是ERROR,那是因为我们这个项目是老项目,打日志用的是log4j 1.2的老版本,有bug,写日志的时候会进入synchronized包裹的代码,也就是要抢锁,之前因为把级别调成INFO,导致了大问题,现在不敢贸然弄成INFO了。等后面先把log4j升级到log4j 2.x的版本,打开更多日志,也许能发现更多。
线上优化思路#
-
目前,我们线上采取了临时措施,写了个shell脚本,通过日志检测,发现这种问题时,自动重启服务,作为应急措施
-
设置oracle底层socket的SO_TIMEOUT,也就是读超时的时间设置一下,避免这么长时间的阻塞
-
设置线程池中每个task的最长执行时间:
com.mchange.v2.async.ThreadPoolAsynchronousRunner#max_individual_task_time // 在PoolThread运行task前,会检测上述字段,大于0则启动一个timerTask,指定时间后中断本线程 try { if (max_individual_task_time > 0) setMaxIndividualTaskTimeEnforcer(); myTask.run(); }private void setMaxIndividualTaskTimeEnforcer() { this.maxIndividualTaskTimeEnforcer = new MaxIndividualTaskTimeEnforcer( this ); myTimer.schedule( maxIndividualTaskTimeEnforcer, max_individual_task_time ); } class MaxIndividualTaskTimeEnforcer extends TimerTask { PoolThread pt; Thread interruptMe; public void run() { interruptMe.interrupt(); } }
这个timerTask,在max_individual_task_time时间后,interrupt当前线程,这样,也能避免线程长期被阻塞。
这个max_individual_task_time,可以通过配置项maxAdministrativeTaskTime来设置。
- 另外,设置numHelperThreads选项,可以增大这个线程池的线程数,虽然是治标不治本的方法,但可以临时紧急使用
- 也可以试试升级c3p0的版本,或者更换其他连接池,如果条件允许的话。
总结#
由于我们这边日志的缺乏、dba也没有配合查这个问题(之前没怀疑到db也是一个原因),目前还不能完全确定问题的根因。
后续,可能会升级日志框架,把更多日志打出来;也会按照上面的优化思路,调整一下参数,主要是控制任务执行时间和socket的so_timeout,避免线程hang死。
再不行,换个连接池框架吧,这玩意设计就有缺陷,就是这个异步获取连接、归还连接的问题,c3p0走向衰落也是正常。
另外,这个框架的线程搞得真是多,看着头疼。
