-
RCNN学习笔记-ResNeXt
论文地址:https://arxiv.org/pdf/1611.05431.pdf
Abstract
我们提出了一种简单、高度模块化的图像分类网络体系结构。我们的网络是通过重复一个构建块来构建的,该构建块聚合了一组具有相同拓扑的变换。我们的简单设计产生了一个只有几个超参数可设置的同构多分支架构。这个策略暴露了一个新的维度,我们称之为“基数”(转换集的大小),它是除了深度和宽度维度之外的一个重要因素。在ImageNet-1K数据集上,我们根据经验表明,即使在保持复杂性的限制条件下,增加基数也能够提高分类精度。此外,当我们增加容量时,增加基数比更深或更宽更有效。我们的模型,命名为ResNeXt是我们加入ILSVRC的基础2016年分类任务,我们获得第二名。我们进一步研究了ImageNet-5K集合和COCO检测集合上的ResNeXt,也显示出比ResNet对应物更好的结果
1. Introduction
视觉识别研究正经历从“特征工程”到“网络工程”的转变。与传统的手工设计功能不同
2.特点介绍
普通卷积
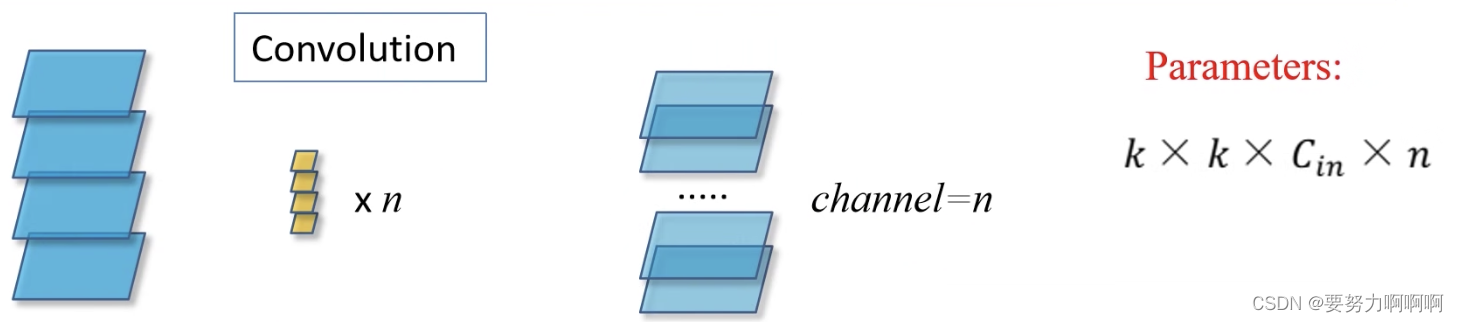
假设卷积核的大小为k✖️k,输入通道为Cin,输出通道为n。因为卷积核的通道是需要和输入通道大小保持一致。所以普通卷积的参数量为上所示。组卷积

假设将其分为两组,第一组为k✖️k✖️2✖️n/2。在这里是假设输入通道为4,输出通道为n。如果将其分为g组,输出通道为n。那么对于每一组的参数为k✖️k✖️Cin/g✖️n/g。那么对于总的来说就是额外在乘g。组卷积和普通卷积的区别
参数变为原来的1/g,参数变小了。
3.结构图介绍
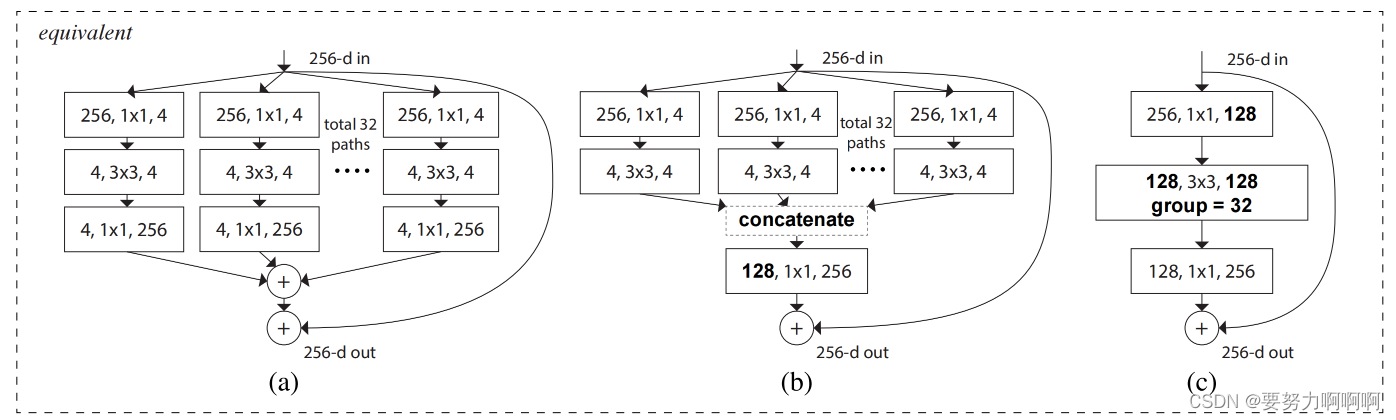
这些block模块,在数学计算上完全等价。相加是将feature上的特征点进行相加。concat是将维度进行相加。
1、Concat:张量拼接,会扩充两个张量的维度,例如2626256和2626512两个张量拼接,结果是2626768。
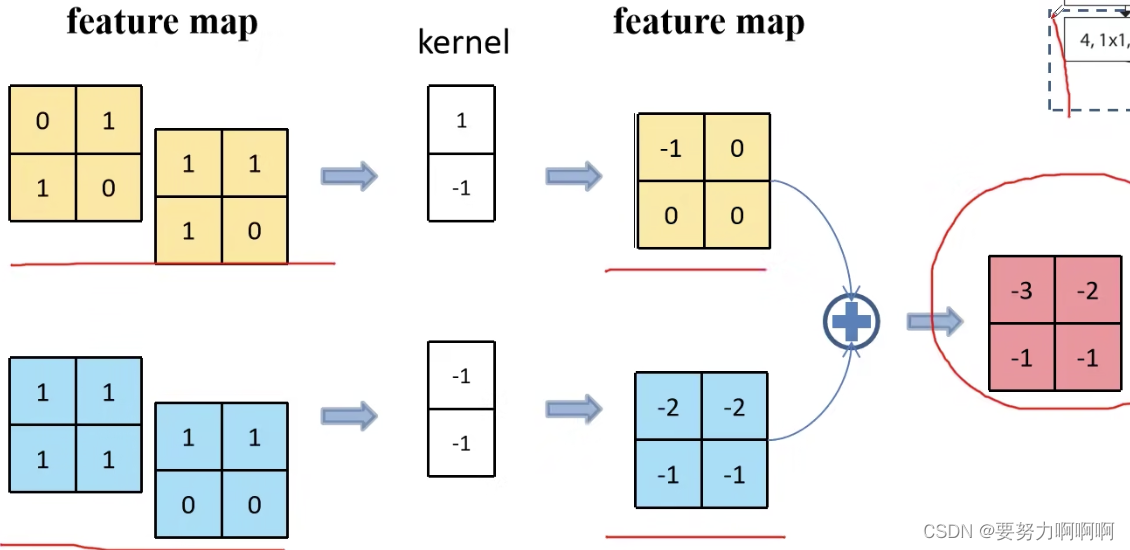
2、add:张量相加,张量直接相加,不会扩充维度。例如104104128和104104128相加,结果还是104104128。add和cfg文件中的shortcut功能一样。张量concat
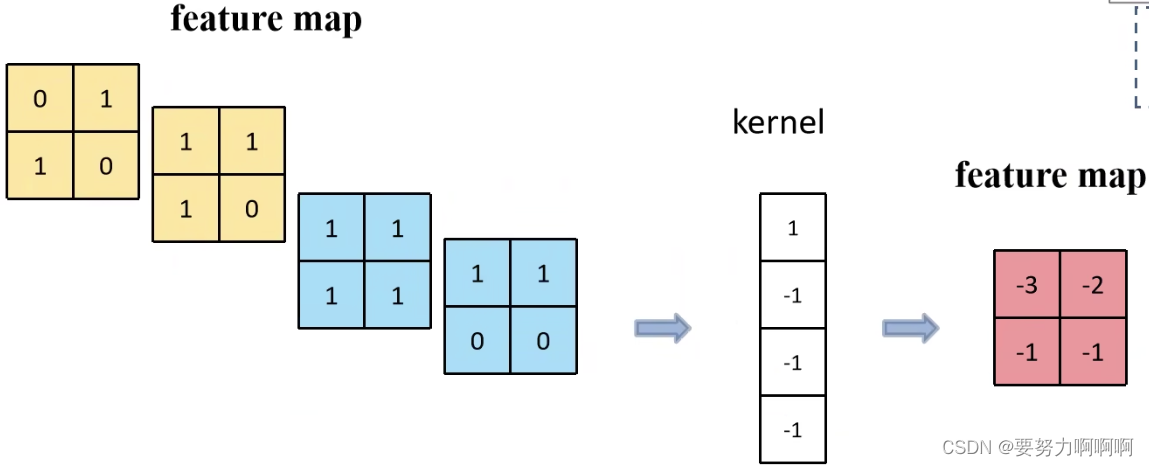
张量add
4.网络结构图
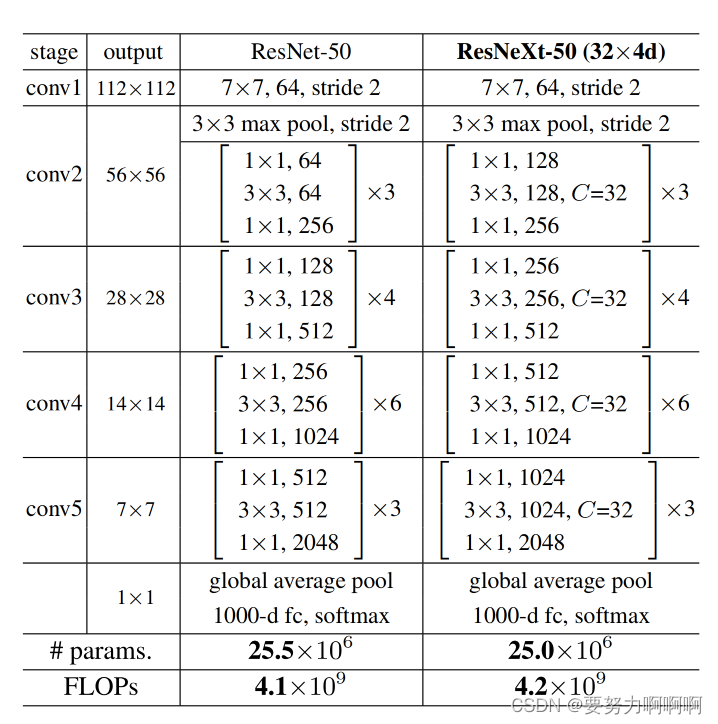
表1.(左)ResNet-50。(右)ResNeXt-50,32×4d模板(使用图3(c)中的公式)。支架内部是残余块的形状,括号外是台上堆叠块的数量。“C=32”建议分组卷积[24],具有32个组。参数数量和这两种模型之间的FLOP相似。
使用的就是上图三个结构中的最左边的。其中4d对应的是4个conv中每一个组对应的卷积核个数分别为4,8,16,32。参考文章:
1.https://zhuanlan.zhihu.com/p/460234735?utm_id=0
2.https://www.bilibili.com/video/BV1Ap4y1p71v/?spm_id_from=333.999.0.0&vd_source=50d7155404373ccb2004b778100660be -
相关阅读:
SpringMVC(第一个项目HelloWorld))
基地树洞 | 自动化小系列之番外篇
如何调试 fastlane 源码
Maven面试题
十一:以理论结合实践方式梳理前端 React 框架 ———框架架构
纯血鸿蒙APP实战开发——Canvas实现模拟时钟案例
Python Flask: 构建轻量级、灵活的Web应用
最近遇到几个小问题总结
freemarker 生成word,支持循环导出图片 WPS版本
手撸promise【二、Promise源码】【代码详细注释/测试案例完整】
- 原文地址:https://blog.csdn.net/guoguozgw/article/details/128208435