-
【生成式网络】入门篇(五):Pix2Pix 的 代码和结果记录
原理参考 https://zhuanlan.zhihu.com/p/464673225
代码参考自 https://github.com/LibreCV/blog/blob/master/_notebooks/2021-02-13-Pix2Pix%20explained%20with%20code.ipynbimport os # os.chdir(os.path.dirname(__file__)) import torch import torch.nn as nn from torch.utils.data import DataLoader, Dataset import torch.nn.functional as F import torchvision from torchvision import transforms from torchvision import datasets from torchvision import models from torch.utils.tensorboard import SummaryWriter import numpy as np from PIL import Image import argparse from glob import glob import random import itertools sample_dir = 'samples_pix2pix' if not os.path.exists(sample_dir): os.makedirs(sample_dir, exist_ok=True) writer = SummaryWriter(sample_dir) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') np.random.seed(0) torch.manual_seed(0) class DownSampleConv(nn.Module): def __init__(self, in_channels, out_channels, kernel=4, strides=2, padding=1, activation=True, batchnorm=True): """ Paper details: - C64-C128-C256-C512-C512-C512-C512-C512 - All convolutions are 4×4 spatial filters applied with stride 2 - Convolutions in the encoder downsample by a factor of 2 """ super().__init__() self.activation = activation self.batchnorm = batchnorm self.conv = nn.Conv2d(in_channels, out_channels, kernel, strides, padding) if batchnorm: self.bn = nn.BatchNorm2d(out_channels) if activation: self.act = nn.LeakyReLU(0.2) def forward(self, x): x = self.conv(x) if self.batchnorm: x = self.bn(x) if self.activation: x = self.act(x) return x class UpSampleConv(nn.Module): def __init__( self, in_channels, out_channels, kernel=4, strides=2, padding=1, activation=True, batchnorm=True, dropout=False ): super().__init__() self.activation = activation self.batchnorm = batchnorm self.dropout = dropout self.deconv = nn.ConvTranspose2d(in_channels, out_channels, kernel, strides, padding) if batchnorm: self.bn = nn.BatchNorm2d(out_channels) if activation: self.act = nn.ReLU(True) if dropout: self.drop = nn.Dropout2d(0.5) def forward(self, x): x = self.deconv(x) if self.batchnorm: x = self.bn(x) if self.dropout: x = self.drop(x) return x class Generator(nn.Module): def __init__(self, in_channels, out_channels): """ Paper details: - Encoder: C64-C128-C256-C512-C512-C512-C512-C512 - All convolutions are 4×4 spatial filters applied with stride 2 - Convolutions in the encoder downsample by a factor of 2 - Decoder: CD512-CD1024-CD1024-C1024-C1024-C512 -C256-C128 """ super().__init__() # encoder/donwsample convs self.encoders = [ DownSampleConv(in_channels, 64, batchnorm=False), # bs x 64 x 128 x 128 DownSampleConv(64, 128), # bs x 128 x 64 x 64 DownSampleConv(128, 256), # bs x 256 x 32 x 32 DownSampleConv(256, 512), # bs x 512 x 16 x 16 DownSampleConv(512, 512), # bs x 512 x 8 x 8 DownSampleConv(512, 512), # bs x 512 x 4 x 4 DownSampleConv(512, 512), # bs x 512 x 2 x 2 DownSampleConv(512, 512, batchnorm=False), # bs x 512 x 1 x 1 ] # decoder/upsample convs self.decoders = [ UpSampleConv(512, 512, dropout=True), # bs x 512 x 2 x 2 UpSampleConv(1024, 512, dropout=True), # bs x 512 x 4 x 4 UpSampleConv(1024, 512, dropout=True), # bs x 512 x 8 x 8 UpSampleConv(1024, 512), # bs x 512 x 16 x 16 UpSampleConv(1024, 256), # bs x 256 x 32 x 32 UpSampleConv(512, 128), # bs x 128 x 64 x 64 UpSampleConv(256, 64), # bs x 64 x 128 x 128 ] self.decoder_channels = [512, 512, 512, 512, 256, 128, 64] self.final_conv = nn.ConvTranspose2d(64, out_channels, kernel_size=4, stride=2, padding=1) self.tanh = nn.Tanh() self.encoders = nn.ModuleList(self.encoders) self.decoders = nn.ModuleList(self.decoders) def forward(self, x): skips_cons = [] for encoder in self.encoders: x = encoder(x) skips_cons.append(x) skips_cons = list(reversed(skips_cons[:-1])) decoders = self.decoders[:-1] for decoder, skip in zip(decoders, skips_cons): x = decoder(x) # print(x.shape, skip.shape) x = torch.cat((x, skip), axis=1) x = self.decoders[-1](x) # print(x.shape) x = self.final_conv(x) return self.tanh(x) class PatchGAN(nn.Module): def __init__(self, input_channels): super().__init__() self.d1 = DownSampleConv(input_channels, 64, batchnorm=False) self.d2 = DownSampleConv(64, 128) self.d3 = DownSampleConv(128, 256) self.d4 = DownSampleConv(256, 512) self.final = nn.Conv2d(512, 1, kernel_size=1) def forward(self, x, y): x = torch.cat([x, y], axis=1) x0 = self.d1(x) x1 = self.d2(x0) x2 = self.d3(x1) x3 = self.d4(x2) xn = self.final(x3) return xn def _weights_init(m): if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d)): torch.nn.init.normal_(m.weight, 0.0, 0.02) if isinstance(m, nn.BatchNorm2d): torch.nn.init.normal_(m.weight, 0.0, 0.02) torch.nn.init.constant_(m.bias, 0) class ImageDataset(torch.utils.data.Dataset): def __init__(self, root, transforms=None, unaligned=False, mode='train'): self.transforms = transforms self.unaligned = unaligned self.files_A = sorted(glob(os.path.join(root, mode, 'A', '*.*'))) self.files_B = sorted(glob(os.path.join(root, mode, 'B', '*.*'))) def __getitem__(self, idx): img = Image.open(self.files_A[idx % len(self.files_A)]).convert('RGB') itemA = self.transforms(img) if self.unaligned: rand_idx = random.randint(0, len(self.files_B)-1) img = Image.open(self.files_B[rand_idx]).convert('RGB') itemB = self.transforms(img) else: img = Image.open(self.files_B[idx % len(self.files_B)]).convert('RGB') itemB = self.transforms(img) return { 'A' : itemA, 'B' : itemB } def __len__(self): return max(len(self.files_A), len(self.files_B)) def denorm(x): out = (x+1)/2 return out.clamp(0, 1) # Losses adv_criterion = nn.BCEWithLogitsLoss() recon_criterion = nn.L1Loss() lambda_recon = 200 n_epochs = 200 display_step = 100 batch_size = 4 lr = 0.0002 target_size = 256 input_size = 256 dataroot = 'data/cycle_gan/datasets/facades' input_nc = 3 output_nc = 3 G = Generator(input_nc, output_nc).to(device) D = PatchGAN(input_nc + output_nc).to(device) G.apply(_weights_init) D.apply(_weights_init) optimG = torch.optim.Adam(G.parameters(), lr=lr) optimD = torch.optim.Adam(D.parameters(), lr=lr) # Dataset loader transforms_data = transforms.Compose([ transforms.Resize(int(input_size*1.12), Image.BICUBIC), transforms.RandomCrop(input_size), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)) ]) dataset = ImageDataset(dataroot, transforms=transforms_data, unaligned=False) dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=1, drop_last=True) ###### Training ###### cnt = 0 log_step = 10 for epoch in range(0, n_epochs): for i, batch in enumerate(dataloader): # set model input real = batch['A'].to(device) condition = batch['B'].to(device) # discriminator fake_images = G(condition).detach() fake_logits = D(fake_images, condition) real_logits = D(real, condition) fake_loss = adv_criterion(fake_logits, torch.zeros_like(fake_logits)) real_loss = adv_criterion(real_logits, torch.ones_like(real_logits)) d_loss = (real_loss + fake_loss) / 2 optimD.zero_grad() d_loss.backward() optimD.step() # generator fake_images = G(condition) disc_logits = D(fake_images, condition) adversarial_loss = adv_criterion(disc_logits, torch.ones_like(disc_logits)) # calculate reconstruction loss recon_loss = recon_criterion(fake_images, real) g_loss = adversarial_loss + lambda_recon * recon_loss optimG.zero_grad() g_loss.backward() optimG.step() cnt += 1 if cnt % log_step == 0: print('Epoch [{}/{}], Step [{}], g_loss: {:.4f}, d_loss: {:.4f}'.\ format(epoch, n_epochs, cnt, g_loss.item(), d_loss.item())) writer.add_scalar('g_loss', g_loss.item(), global_step=cnt) writer.add_scalar('d_loss', d_loss.item(), global_step=cnt) if cnt % 100 == 0: writer.add_images('real', denorm(real), global_step=cnt) writer.add_images('condition', denorm(condition), global_step=cnt) writer.add_images('fake_images', denorm(fake_images), global_step=cnt)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
整体结构参考自Conditional GAN,把图像A作为condition出现在generator和discriminator里。
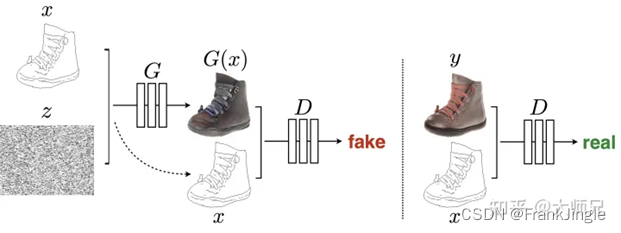
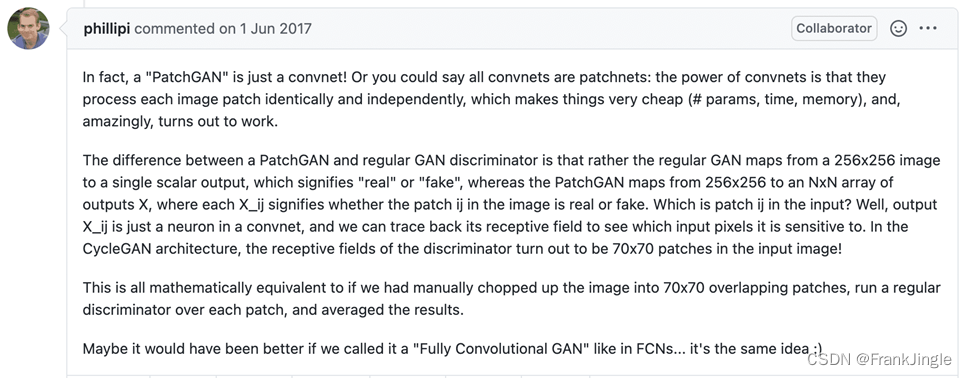
另外一个可以关注一下U-net结构的generator设计,和PatchGAN结构的 discriminator。具体解释可以看下图
实验效果如下-
real image

-
condition image
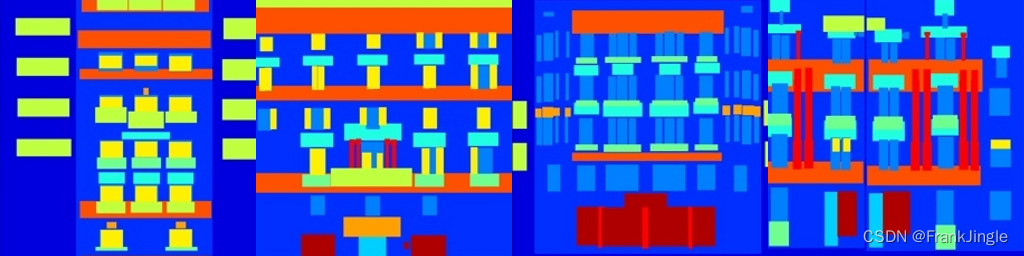
-
generated image,效果很差,可能是没有训练到位,后续再调试吧

-
相关阅读:
用户身份标识与账号体系实践
生成数字图像基本过程
基于Python开发的开心麻花影视作品分析系统(源码+可执行程序+程序配置说明书+程序使用说明书)
TI Sitara系列AM64x开发板(双核ARM Cortex-A53)软硬件规格书
ActiveReportsJS 3.1中文版|||ActiveReportsJS 3.1英文版
计算机毕业设计Java扶贫产品销售(源码+系统+mysql数据库+lw文档)
跨站脚本攻击xss攻击
ISL1208时钟芯片 Linux下 i2c 设置报警时钟。
Java中set的实现类
7.3 进程管理之暂停、归档和策略
- 原文地址:https://blog.csdn.net/fangjin_kl/article/details/128122432
