-
SparkStreaming 消费Kafka数据的两种方式(Receiver,Direct)~
两种方式为:Receiver方式,Direct直连方式。- 1
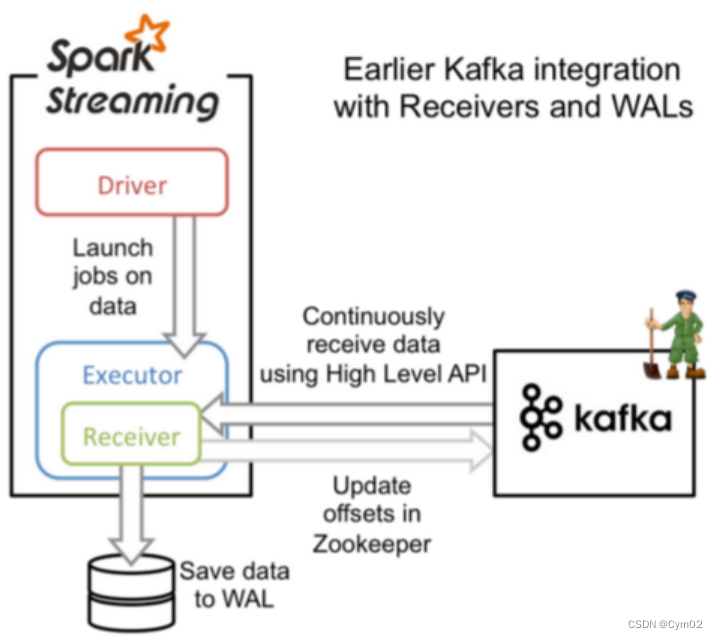
一、基于Receiver的方式
(1)receiver内存溢出问题:
使用kafka高层次的
consumer API来实现,使用receiver从kafka中获取的数据都保存在spark excutor的内存中,然后由Spark Streaming启动的job来处理数据。因此一旦数据量暴增,很容易造成内存溢出。(2)数据丢失:
并且,在默认配置下,这种方式可能会因为底层失败而造成数据丢失,如果要启用高可靠机制,确保零数据丢失,要启用
Spark Streaming的预写日志机制(Write Ahead Log,(已引入)在Spark 1.2)。该机制会同步地将接收到的Kafka数据保存到分布式文件系统(比如HDFS)上的预写日志中,以便底层节点在发生故障时也可以使用预写日志中的数据进行恢复。(3)数据重复消费:
使用 Kafka 的高阶 API来在 ZooKeeper 中保存消费过的 offset的。这是消费 Kafka 数据的传统方式。这种方式配合着 WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为 Spark和ZooKeeper之间可能是不同步的。
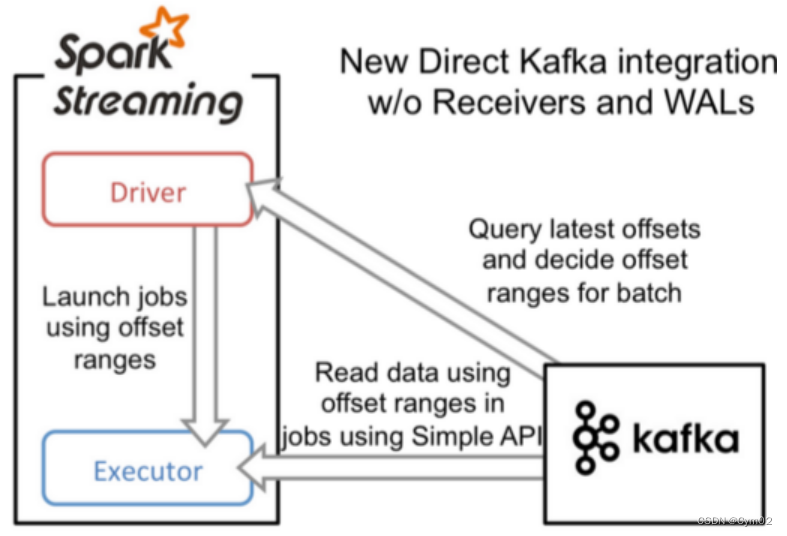
二、基于Direct的方式
这种新的不基于Receiver的直接方式,是在Spark 1.3中引入的,从而能够确保更加健壮的机制。
替代掉使用Receiver来接收数据后,这种方式会周期性地查询Kafka,来获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。
使用 kafka 的简单 api,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次。
三、对比:
Direct方法相较于Receiver方式的优势在于:
-
简化的并行:
在Receiver的方式中我们提到创建多个Receiver之后利用union来合并成一个Dstream的方式提高数据传输并行度。而在Direct方式中,Kafka中的partition与RDD中的partition是一一对应的并行读取Kafka数据,这种映射关系也更利于理解和优化。 -
高效:
在Receiver的方式中,为了达到0数据丢失需要将数据存入Write Ahead Log中,这样在Kafka和日志中就保存了两份数据,浪费!而第二种方式不存在这个问题,只要我们Kafka的数据保留时间足够长,我们都能够从Kafka进行数据恢复。 -
精确一次:
在Receiver的方式中,使用的是Kafka的高阶API接口从Zookeeper中获取offset值,这也是传统的从Kafka中读取数据的方式,但由于Spark Streaming消费的数据和Zookeeper中记录的offset不同步,这种方式偶尔会造成数据重复消费。而第二种方式,直接使用了简单的低阶Kafka API,Offsets则利用Spark Streaming的checkpoints进行记录,消除了这种不一致性。
在实际生产环境中一般都采用Direct方式。
-
相关阅读:
Docker简介以及环境搭建
RK3568技术笔记之一 RK3568总体介绍
incStrong() 和 decStrong()
C++项目:仿mudou库实现高性能高并发服务器
Linux网络基础
oracle,CLOB转XML内存不足,ORA-27163: out of memory ORA-06512: at “SYS.XMLTYPE“,
Linux /etc/passwd和/etc/shadow
瑞吉外卖项目:移动端导入用户地址簿与菜品展示功能实现
糖尿病患者,稳定控糖,饮食上需注意什么?禁忌和适宜一次说清
【华为上机真题 2022】字符串比较
- 原文地址:https://blog.csdn.net/gym02/article/details/128002225