-
梦开始的地方 —— C语言结构体详解
结构体
1. 结构体声明
结构体是一组元素的的集合,结构体成员列表可以是不同类型的变量。
定义结构体格式
通过struct关键字就可以定义一个结构体
struct stu { //成员列表 }变量列表; //变量列表可写可不写- 1
- 2
- 3
- 4
- 5
来通过结构体来描述一个学生
struct Student { char name[20];//姓名 char sex[10];//性别 int age; //年龄 }s1,s2;- 1
- 2
- 3
- 4
- 5
- 6
匿名结构体声明
struct { int num; char str[20]; }s; struct { int num; char str[10]; }*p;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
那么如果写出这样的代码
p = &s;- 1
编译器就报出进警告,它会认为上面两个声明不是一个类型,所以这种匿名结构体就、不建议使用。
2. 结构体的自引用
在结构体成员变量中是否可以包含自己本身呢?
struct Node { int val; struct Node* next;//正确写法 };- 1
- 2
- 3
- 4
还有一种错误的写法
这种结构体自引用的写法明显是错误的,因为如果要计算结构体大小的时候。Node里包含Node,就会无先递归下去,这样的话结构体的大小是不方便计算的。
struct Node { int val; struct Node next; };- 1
- 2
- 3
- 4
我们知道
typedef可以给类型重命名,那么就可以写出下面的写法#includetypedef struct Node { int val; struct Node* next; }Node; int main() { Node node; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
对应的错误写法就是,匿名结构体
typedef struct { int val; Node* next; }Node; //或者是 typedef struct Node { int val; Node* next; }Node;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
上面两个都是错误写法
3. 结构体初始化和访问
可以把一个结构体想象成一张图纸,通过这张图纸可以盖很多房子
#includestruct Student { char name[20];//姓名 char sex[10];//性别 int age; //年龄 }s1, s2; int main() { struct Student s = { "张三","男",18 }; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
struct 表示这个是一个结构体
struct Studnet 表示这是一个 Student类型的变量
可以看到结构体右花括号后面的s1和s2。它们两个其实也是两个结构体变量值不过它们两是全局的结构体变量没有初始化。
#includestruct Student { char name[20];//姓名 char sex[10];//性别 int age; //年龄 }s1, s2; //等价于 struct Student s1; struct Student s2; int main() { return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
也可以在定义的时候给它们初始化,或者在main函数里初始化。
struct Student { char name[20];//姓名 char sex[10];//性别 int age; //年龄 }s1 = { "李四","男",19 }, s2 = {"王五","男",20};- 1
- 2
- 3
- 4
- 5
- 6
结构体嵌套定义
struct Stu { char name[20]; int id; }; typedef struct Node { int val; struct Node* next; struct Stu s; }Node;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4. 结构体成员访问
结构体成员变量通过点
.操作符来访问结构体成员#includestruct Student { char name[20];//姓名 char sex[10];//性别 int age; //年龄 }; int main() { struct Student s = { "张三","男",18}; printf("%s %s %d", s.name, s.sex, s.age); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
运行结果
张三 男 18- 1
结构体指针访问
有的时候我们拿到的是一个结构体指针,那么怎么通过结构体指针访问结构体成员变量呢?
#includestruct Student { char name[20];//姓名 char sex[10];//性别 int age; //年龄 }; int main() { struct Student s = { "张三","男",18}; struct Student* sp = &s; printf("%s %s %d\n",(*sp).name,(*sp).sex,(*sp).age); printf("%s %s %d\n",sp->name,sp->sex,sp->age); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
struct Student* 类型的结构体指针变量sp里存放的是 结构体变量s的地址,通过解引用就能拿到s对象再通过点操作符就能访问结构体成员变量
->和前面那种方法没啥区别嵌套结构体使用
#includestruct Stu { char name[20]; int id; }; typedef struct Node { int val; struct Node* next; struct Stu s; }Node; int main() { Node node = { 100,NULL,{"张三",1} }; printf("%d %s %d\n", node.val, node.s.name, node.s.id); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
5. 结构体传参
有的时候结构体需要作为形参传递给函数进行使用,那么结构体传参需要注意什么呢?
来看一段代码
#includestruct Student { char name[20];//姓名 char sex[10];//性别 int age; //年龄 }; void prt1(struct Student s) { printf("%s %s %d\n", s.name, s.sex, s.age); } void prt2(struct Student* sp) { printf("%s %s %d\n", sp->name, sp->sex, sp->age); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
以上两个方法都能打印学生结构体,那么它们有什么区别呢?
我们知道函数的传参传的是形参,形参是实参的一份临时拷贝。显然prt1函数传参的时候传递过去的是整个结构体变量。也就是拷贝了整个结构体变量作为形参。
而函数传参的时候,参数是要压栈,要是一个结构体所占的内存比较大,如果是传递变量开销就会比较大,导致整个程序的性能下降。
如果传递的是指针,也就是传结构体的地址。指针的大小无非就是4个字节或者8个字节。相比于直接传值开销就小太多了。所以结构体传参更建议传地址(指针)
来看一段代码
#includeint Add(int x, int y) { int z = 0; z = x + y; return z; } int main() { int a = 10; int b = 20; int ret = Add(a, b); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

局部变量是在内存的栈区上开辟的,栈区内存的使用习惯是先使用高地址的空间,后使用低地址的空间,栈区又是一种先进后出,后进先出的结构,且只能在一端操作
函数的传参一般是从右往左,这也是函数调用的约定。
每一次函数的调用,操作系统都会在内存的栈区上开辟一块空间,称为栈帧。
在为函数创建栈帧的时候,会有很多的寄存器去维护,这一片的可使用空间就会被初始化为随机值,这个根据不同的编译器有不同的初始化方式,这就是我们对局部变量定义的时候不进行初始化打印随机值的原因。
6. 结构体内存对齐
整形,浮点型和字符型乃至数组都能计算大小,那么结构体的大小怎么计算呢?我们知道结构体成员都是由整形、浮点型字符型等组成的。那结构体大小是不是就是结构体成员大小相加,显然没有那么简单。那么结构体大小到底是怎么计算大小的呢?
结构体的计算需要遵循结构体的对齐规则
-
第一个成员在与结构体变量偏移量为0的地址处
-
其他成员变量要对齐到对齐数的整数倍的地址处。
-
对齐数 等于,编译器默认的对齐数和该成员变量相比取较小值
比如,num变量大小是4个字节,VS中默认对齐数是8,4和8取较小值,那么4就是对齐数。变量num就得放在以对齐数4为倍数的偏移量位置。
struct Stu { char c; int num; };- 1
- 2
- 3
- 4
-
结构体总大小为最大对齐数(每个成员变量都有一个对齐数,取最大的成员变量对齐数)的整数倍
-
如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍
offsetof函数可以计算结构体成员变量相较于结构体起始位置的偏移量,需要头文件#include它有两个参数
- 结构体类型名
- 成员变量名
- 返回值是一个无符号整形
size_t offsetof( structName, memberName );- 1
#include#include struct Stu { char c; int num; }; int main() { printf("%d\n",offsetof(struct Stu,c)); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
注意:默认对齐数不是所有编译器都有,我这里是VS默认的对齐数是8,而linux平台下没有默认对齐数,当没有默认对齐数时,成员变量的大小就是该成员的对齐数
举个列子
#includestruct Stu { char c1; int num; char c2; }; int main() { printf("%d\n", sizeof(struct Stu)); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 先拿结构体成员的大小和编译器默认对齐数相比较,取较小的那一个为该成员变量的对齐数,我是VS2019环境默认对齐数是8
- 首先第一个成员变量是从结构体变量偏移量为0的位置开始存储的,它是一个字符型占一个字节
- 接着是一个整形变量num占4个字节,它和VS的默认对齐数8取较小值就是4,那么变量num 就得对齐到以4为整数倍的偏移量的位置,那就是从4开始
- 接着是字符型变量c2,占一个字节和默认对齐数取较小就是1,变量c2就得对齐到1的倍数上,显然任何偏移量都可以,他就放到了以偏移量8为起始的位置。这9就是这个结果体的大小了吗?显然不是。
- 结构体总大小为最大对齐数的整数倍,该结构体的最大对齐数就num的对齐数4个字节,而9显然不是4的倍数。
- 那么结构体就得对齐到12才刚好是4的倍数,所以该结构体的大小时12个字节

再来看一个结构体嵌套的例子
#includestruct Stu { char c1; double num; char c2; }; struct Node { char ch; struct Stu stu; double price; }; int main() { printf("%d\n", sizeof(struct Node)); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- ch是第一个成员变量,从偏移量为0的地方开始
- stu是一个结构,如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处。最大对齐数是8,那就是到了偏移量为24位置的地方
- 然后是price是对齐数是8,要从8的倍数开始对齐。从32开始就到了40.
- 嵌套结构体,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。40刚好是,所有Node结构体的大小就是40

需要注意
如果结构体体中存在数组,那么数组的对齐数则是该数组元素的对齐数
#include#include struct Stu { int a;//4 short arr[5]; char ch; }; int main() { short arr[5]; printf("%d\n",offsetof(struct Stu,arr)); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
输出
short arr[5]每个元素都是short所以它的对齐数是2,要对齐到2的倍数,那么偏移量就是44- 1
7. 修改默认对齐数
通过
#pragma这个预处理指令就可以修改我们的默认对齐数#include#pragma pack(1)//设置默认对齐数为1 struct Stu { char c1; int num; char c2; }; #pragma pack()//恢复默认对齐数 int main() { printf("%d\n", sizeof(struct Stu)); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
打印结果
6- 1
很显然把默认对齐数修改成功1,那么按1对齐就是连续存放的。就是6个字节
8. 为什么存在结构体内存对齐?
大部分的参考资料都是如是说的:
- 平台原因(移植原因): 不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址
处取某些特定类型的数据,否则抛出硬件异常。 - 性能原因: 数据结构(尤其是栈)应该尽可能地在自然边界上对齐。 原因在于,为了访问未对齐的内存,处理器
需要作两次内存访问;而对齐的内存访问仅需要一次访问
举个例子
有这么一个结构体
struct Stu { char c1; double num; char c2; };- 1
- 2
- 3
- 4
- 5
假设在32位机器上一次内存读取是4个字节
不考虑内存对齐
读取num成员变量需要读取3次
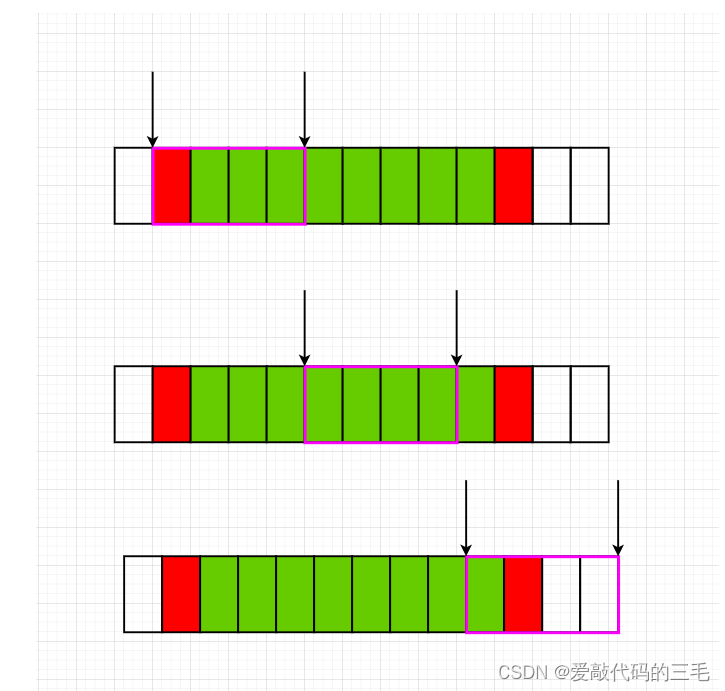
如果考虑内存对齐
那么只需要读两次

总结:内存对齐就是拿空间来换取时间的做法
9.如何设计结构体
通过结构体内存对齐发现,如果结构体设计的不合理就会存在很多空间被浪费掉。
那么如果做到,满足内存对齐,占用空间尽可能小。
那就是让占用空间小的成员尽量集中在一起
举个列子
struct Stu { char c1; int num; char c2; };- 1
- 2
- 3
- 4
- 5
这个结构体随意设计,此时结构体大小是12

把空间小的放一起,此时结构体大小就是8
struct Stu { char c1; char c2; int num; };- 1
- 2
- 3
- 4
- 5

-
相关阅读:
基于Java毕业设计云盘系统修改密码演示2021源码+系统+mysql+lw文档+部署软件
T1065 奇数求和(信息学一本通C++)
优化sql语句的一般步骤
MT8735/MTK8735安卓核心板规格参数介绍
codeforces:E2. Array and Segments (Hard version)【线段树 + 区间修改】
针对多分类问题,使用深度学习--Keras进行微调提升性能
文生图——DALL-E 3 —论文解读——第一版
prometheus 监控oracle
LA@二次型分类@正定二次型@主子式
Selenium+Pytest自动化测试框架实战
- 原文地址:https://blog.csdn.net/weixin_53946852/article/details/127829533
