-
Swin transformer v2和Swin transformer v1源码对比
swin transformer v1源码见我的博客:
swin_transformer源码详解_樱花的浪漫的博客-CSDN博客_swin transformer代码解析
在此只解析v1和v2的区别
1.q,k,v的映射
在通过x投影得到q,k,v的过程中,swin transformer v2将权重weight和偏置项bias分开进行更新,可能作者觉得普通的线性投影比较受限,而采取分开初始化的方式更能找到合适的参数。
- self.qkv = nn.Linear(dim, dim * 3, bias=False)
- # 偏置项作为可学习的参数
- if qkv_bias:
- self.q_bias = nn.Parameter(torch.zeros(dim))
- self.v_bias = nn.Parameter(torch.zeros(dim))
- else:
- self.q_bias = None
- self.v_bias = None
2.余弦注意力
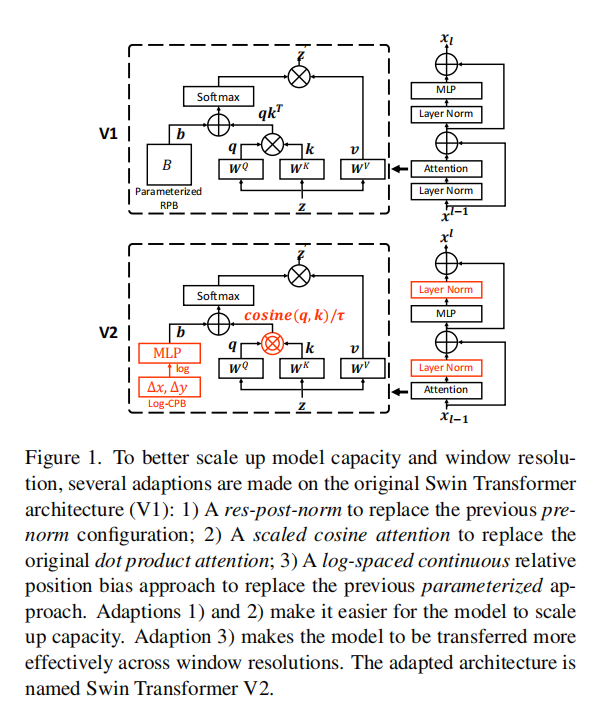
作者认为原来的标准注意力机制容易使网络陷入极端值,因此提出了一个缩放的余弦注意来取代以前的点积注意。缩放的余弦注意使得计算与块输入的振幅无关,并且注意值不太可能落入极端值。
从代码实现上,就是先除以q,k最后一个维度的范数,再做点乘操作,相当于先用最后一个维度的范数做了一个归一化。 对于缩放系数
 ,是一个可学习的参数,用10进行初始化。
,是一个可学习的参数,用10进行初始化。- self.logit_scale = nn.Parameter(torch.log(10 * torch.ones((num_heads, 1, 1))), requires_grad=True)
- attn = (F.normalize(q, dim=-1) @ F.normalize(k, dim=-1).transpose(-2, -1))
- logit_scale = torch.clamp(self.logit_scale, max=torch.log(torch.tensor(1. / 0.01).to(attn.device))).exp()
- attn = attn * logit_scale
3.相对位置编码
对于相对位置编码,v1的做法是通过创建一个可学习的2*Wh-1 * 2*Ww-1, nH维度的位置参数,按照相对位置索引将相对位置信息加入到注意力机制中。但是这种位置编码方式时在窗口大小发生改变,需要将低分辨率训练的权重转移到高分辨率的图像时,只能通过双三次插值的方法。受到了限制,于是,作者引入了一个对数间隔的连续位置偏差(Log-CPB),它通过对对数间隔的坐标输入应用一个小的元网络来生成任意坐标范围的偏差值。
代码实现来说,首先创建一个包含相对位置信息的矩阵,维度为1, 2*Wh-1, 2*Ww-1, 2。对于相对位置上的值,初始化为[-w+1,w-1]区间大小的相对位置值,在不转移窗口位置权重的情况下,将相对位置值标准化至[-8,8]区间内,根据作者的思想,作者这样限制是想要限制窗口改变时的外推比。然后,使用两层线性层和一层relu激活的全连接层生成位置参数,维度为 2*Wh-1 * 2*Ww-1,num_heads,然后根据索引,将位置参数加入到注意力机制中。
最后,为了对应于初始化中将相对位置的值标准化至[-8,8]区间,使用
16 * torch.sigmoid(relative_position_bias)将对位置参数的值进行标准化。
- self.cpb_mlp = nn.Sequential(nn.Linear(2, 512, bias=True),
- nn.ReLU(inplace=True),
- nn.Linear(512, num_heads, bias=False))
- # get relative_coords_table
- relative_coords_h = torch.arange(-(self.window_size[0] - 1), self.window_size[0], dtype=torch.float32)
- relative_coords_w = torch.arange(-(self.window_size[1] - 1), self.window_size[1], dtype=torch.float32)
- # 相对位置的矩阵[-w+1,w-1],限制在区间[-8.8]
- relative_coords_table = torch.stack(
- torch.meshgrid([relative_coords_h,
- relative_coords_w])).permute(1, 2, 0).contiguous().unsqueeze(0) # 1, 2*Wh-1, 2*Ww-1, 2
- if pretrained_window_size[0] > 0:
- relative_coords_table[:, :, :, 0] /= (pretrained_window_size[0] - 1)
- relative_coords_table[:, :, :, 1] /= (pretrained_window_size[1] - 1)
- else:
- relative_coords_table[:, :, :, 0] /= (self.window_size[0] - 1)
- relative_coords_table[:, :, :, 1] /= (self.window_size[1] - 1)
- relative_coords_table *= 8 # normalize to -8, 8
- # Log-spaced coordinates 使用了8进行规范化
- relative_coords_table = torch.sign(relative_coords_table) * torch.log2(
- torch.abs(relative_coords_table) + 1.0) / np.log2(8)
- self.register_buffer("relative_coords_table", relative_coords_table)
- # get pair-wise relative position index for each token inside the window
- coords_h = torch.arange(self.window_size[0])
- coords_w = torch.arange(self.window_size[1])
- coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
- coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
- relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
- relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
- relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
- relative_coords[:, :, 1] += self.window_size[1] - 1
- relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
- relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
- self.register_buffer("relative_position_index", relative_position_index)
- relative_position_bias_table = self.cpb_mlp(self.relative_coords_table).view(-1, self.num_heads)
- relative_position_bias = relative_position_bias_table[self.relative_position_index.view(-1)].view(
- self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
- relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
- relative_position_bias = 16 * torch.sigmoid(relative_position_bias)
- attn = attn + relative_position_bias.unsqueeze(0)
4.Post normalization
作者在实验中发现,在预归一化配置中,注意力的激活值直接进行残差连接,造成了激活值的震荡,并且主分支的振幅在更深的层次上越来越大。不同层的振幅差异较大,导致训练不稳定。
因此,作者如上图所示,作者将预归一化改为后归一化,即去除预归一化,在残差连接前先进行归一化,在进行残差连接。
- class WindowAttention(nn.Module):
- r""" Window based multi-head self attention (W-MSA) module with relative position bias.
- It supports both of shifted and non-shifted window.
- Args:
- dim (int): Number of input channels.
- window_size (tuple[int]): The height and width of the window.
- num_heads (int): Number of attention heads.
- qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
- attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
- proj_drop (float, optional): Dropout ratio of output. Default: 0.0
- pretrained_window_size (tuple[int]): The height and width of the window in pre-training.
- """
- def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.,
- pretrained_window_size=[0, 0]):
- super().__init__()
- self.dim = dim
- self.window_size = window_size # Wh, Ww
- self.pretrained_window_size = pretrained_window_size
- self.num_heads = num_heads
- # 余弦注意力的缩放值
- self.logit_scale = nn.Parameter(torch.log(10 * torch.ones((num_heads, 1, 1))), requires_grad=True)
- # mlp to generate continuous relative position bias 可学习的位置编码
- self.cpb_mlp = nn.Sequential(nn.Linear(2, 512, bias=True),
- nn.ReLU(inplace=True),
- nn.Linear(512, num_heads, bias=False))
- # get relative_coords_table
- relative_coords_h = torch.arange(-(self.window_size[0] - 1), self.window_size[0], dtype=torch.float32)
- relative_coords_w = torch.arange(-(self.window_size[1] - 1), self.window_size[1], dtype=torch.float32)
- # 相对位置的矩阵[-w+1,w-1],限制在区间[-8.8]
- relative_coords_table = torch.stack(
- torch.meshgrid([relative_coords_h,
- relative_coords_w])).permute(1, 2, 0).contiguous().unsqueeze(0) # 1, 2*Wh-1, 2*Ww-1, 2
- if pretrained_window_size[0] > 0:
- relative_coords_table[:, :, :, 0] /= (pretrained_window_size[0] - 1)
- relative_coords_table[:, :, :, 1] /= (pretrained_window_size[1] - 1)
- else:
- relative_coords_table[:, :, :, 0] /= (self.window_size[0] - 1)
- relative_coords_table[:, :, :, 1] /= (self.window_size[1] - 1)
- relative_coords_table *= 8 # normalize to -8, 8
- # Log-spaced coordinates 使用了8进行规范化
- relative_coords_table = torch.sign(relative_coords_table) * torch.log2(
- torch.abs(relative_coords_table) + 1.0) / np.log2(8)
- self.register_buffer("relative_coords_table", relative_coords_table)
- # get pair-wise relative position index for each token inside the window
- coords_h = torch.arange(self.window_size[0])
- coords_w = torch.arange(self.window_size[1])
- coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
- coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
- relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
- relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
- relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
- relative_coords[:, :, 1] += self.window_size[1] - 1
- relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
- relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
- self.register_buffer("relative_position_index", relative_position_index)
- self.qkv = nn.Linear(dim, dim * 3, bias=False)
- # 偏置项作为可学习的参数
- if qkv_bias:
- self.q_bias = nn.Parameter(torch.zeros(dim))
- self.v_bias = nn.Parameter(torch.zeros(dim))
- else:
- self.q_bias = None
- self.v_bias = None
- self.attn_drop = nn.Dropout(attn_drop)
- self.proj = nn.Linear(dim, dim)
- self.proj_drop = nn.Dropout(proj_drop)
- self.softmax = nn.Softmax(dim=-1)
- def forward(self, x, mask=None):
- """
- Args:
- x: input features with shape of (num_windows*B, N, C)
- mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
- """
- B_, N, C = x.shape
- qkv_bias = None
- if self.q_bias is not None:
- qkv_bias = torch.cat((self.q_bias, torch.zeros_like(self.v_bias, requires_grad=False), self.v_bias))
- qkv = F.linear(input=x, weight=self.qkv.weight, bias=qkv_bias)
- qkv = qkv.reshape(B_, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
- q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
- # cosine attention
- attn = (F.normalize(q, dim=-1) @ F.normalize(k, dim=-1).transpose(-2, -1))
- logit_scale = torch.clamp(self.logit_scale, max=torch.log(torch.tensor(1. / 0.01).to(attn.device))).exp()
- attn = attn * logit_scale
- relative_position_bias_table = self.cpb_mlp(self.relative_coords_table).view(-1, self.num_heads)
- relative_position_bias = relative_position_bias_table[self.relative_position_index.view(-1)].view(
- self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
- relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
- relative_position_bias = 16 * torch.sigmoid(relative_position_bias)
- attn = attn + relative_position_bias.unsqueeze(0)
- if mask is not None:
- nW = mask.shape[0]
- attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
- attn = attn.view(-1, self.num_heads, N, N)
- attn = self.softmax(attn)
- else:
- attn = self.softmax(attn)
- attn = self.attn_drop(attn)
- x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
- x = self.proj(x)
- x = self.proj_drop(x)
- return x
- class SwinTransformerBlock(nn.Module):
- r""" Swin Transformer Block.
- Args:
- dim (int): Number of input channels.
- input_resolution (tuple[int]): Input resulotion.
- num_heads (int): Number of attention heads.
- window_size (int): Window size.
- shift_size (int): Shift size for SW-MSA.
- mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
- qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
- drop (float, optional): Dropout rate. Default: 0.0
- attn_drop (float, optional): Attention dropout rate. Default: 0.0
- drop_path (float, optional): Stochastic depth rate. Default: 0.0
- act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
- norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
- pretrained_window_size (int): Window size in pre-training.
- """
- def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
- mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,
- act_layer=nn.GELU, norm_layer=nn.LayerNorm, pretrained_window_size=0):
- super().__init__()
- self.dim = dim
- self.input_resolution = input_resolution
- self.num_heads = num_heads
- self.window_size = window_size
- self.shift_size = shift_size
- self.mlp_ratio = mlp_ratio
- if min(self.input_resolution) <= self.window_size:
- # if window size is larger than input resolution, we don't partition windows
- self.shift_size = 0
- self.window_size = min(self.input_resolution)
- assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
- self.norm1 = norm_layer(dim)
- self.attn = WindowAttention(
- dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
- qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop,
- pretrained_window_size=to_2tuple(pretrained_window_size))
- self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
- self.norm2 = norm_layer(dim)
- mlp_hidden_dim = int(dim * mlp_ratio)
- self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
- if self.shift_size > 0:
- # calculate attention mask for SW-MSA
- H, W = self.input_resolution
- img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
- h_slices = (slice(0, -self.window_size),
- slice(-self.window_size, -self.shift_size),
- slice(-self.shift_size, None))
- w_slices = (slice(0, -self.window_size),
- slice(-self.window_size, -self.shift_size),
- slice(-self.shift_size, None))
- cnt = 0
- for h in h_slices:
- for w in w_slices:
- img_mask[:, h, w, :] = cnt
- cnt += 1
- mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
- mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
- attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
- attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
- else:
- attn_mask = None
- self.register_buffer("attn_mask", attn_mask)
- def forward(self, x):
- H, W = self.input_resolution
- B, L, C = x.shape
- assert L == H * W, "input feature has wrong size"
- shortcut = x
- x = x.view(B, H, W, C)
- # cyclic shift
- if self.shift_size > 0:
- shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
- else:
- shifted_x = x
- # partition windows
- x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
- x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
- # W-MSA/SW-MSA
- attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
- # merge windows
- attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
- shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
- # reverse cyclic shift
- if self.shift_size > 0:
- x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
- else:
- x = shifted_x
- x = x.view(B, H * W, C)
- x = shortcut + self.drop_path(self.norm1(x))
- # FFN
- x = x + self.drop_path(self.norm2(self.mlp(x)))
- return x
-
相关阅读:
Can‘t pickle <class ‘__main__.Test‘>: it‘s not the same object as __main__.Test
【单片机基础】C51语言基础
前端组件封装:构建模块化、可维护和可重用的前端应用
AWS】在EC2上创建root用户,并使用root用户登录
老K,硬核“锅”气
Java---Java Web---JSP
液晶显示计算器(显示程序)
前端网站分享
SELinux
PaddleNLP UIE -- 药品说明书信息抽取(名称、规格、用法、用量)
- 原文地址:https://blog.csdn.net/qq_52053775/article/details/127794977