-
3.1 Python 字符串类型常用操作及内置方法

1. Str 字符串
1.1 字符串
特征: 使用引号引起来的字符称为字符串, 字符串可以是中文, 英文, 数字, 符号等混合组成.- 1
Python 中可以使用的引号: * 1. 单引号 'x' * 2. 双引号 "x" * 3. 三单引号 '''x''' * 4. 三双引号 """x""" 三单引号, 三双引号, 的左侧没有赋值符号的时候是注释, 有赋值符号的时候是字符串, 按书写时的样式原样输出, 书写几行就是以行行显示.- 1
- 2
- 3
- 4
- 5
- 6
- 7
str1 = 'x' str2 = "x" str3 = '''x''' str4 = """x""" print(str1, str2, str3, str4, type(str1)) # x x x x- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.2 反斜杠
反斜杠在字符串中有两个作用: * 1. 换行, 使用反斜杠对字符串的内存进行换行, 把字符串分割成多行. 在每行的末尾使用, 在处于括号(), 中括号[], 花括号{}中是反斜杠是可以省略的. * 2. 转义, 反引号与某个字符组合成转义字符.- 1
- 2
- 3
- 4
1. 字符串跨行书写
编辑界面中一行无法写完一句话, 可以采用分行书写, 代码看上去也整洁. 用 \ 斜杠 续行符, 在下一行继续书写字符串, 按一个段落输出. * 在跨行书写的时候不能在续行符后加 # 号注释.- 1
- 2
- 3
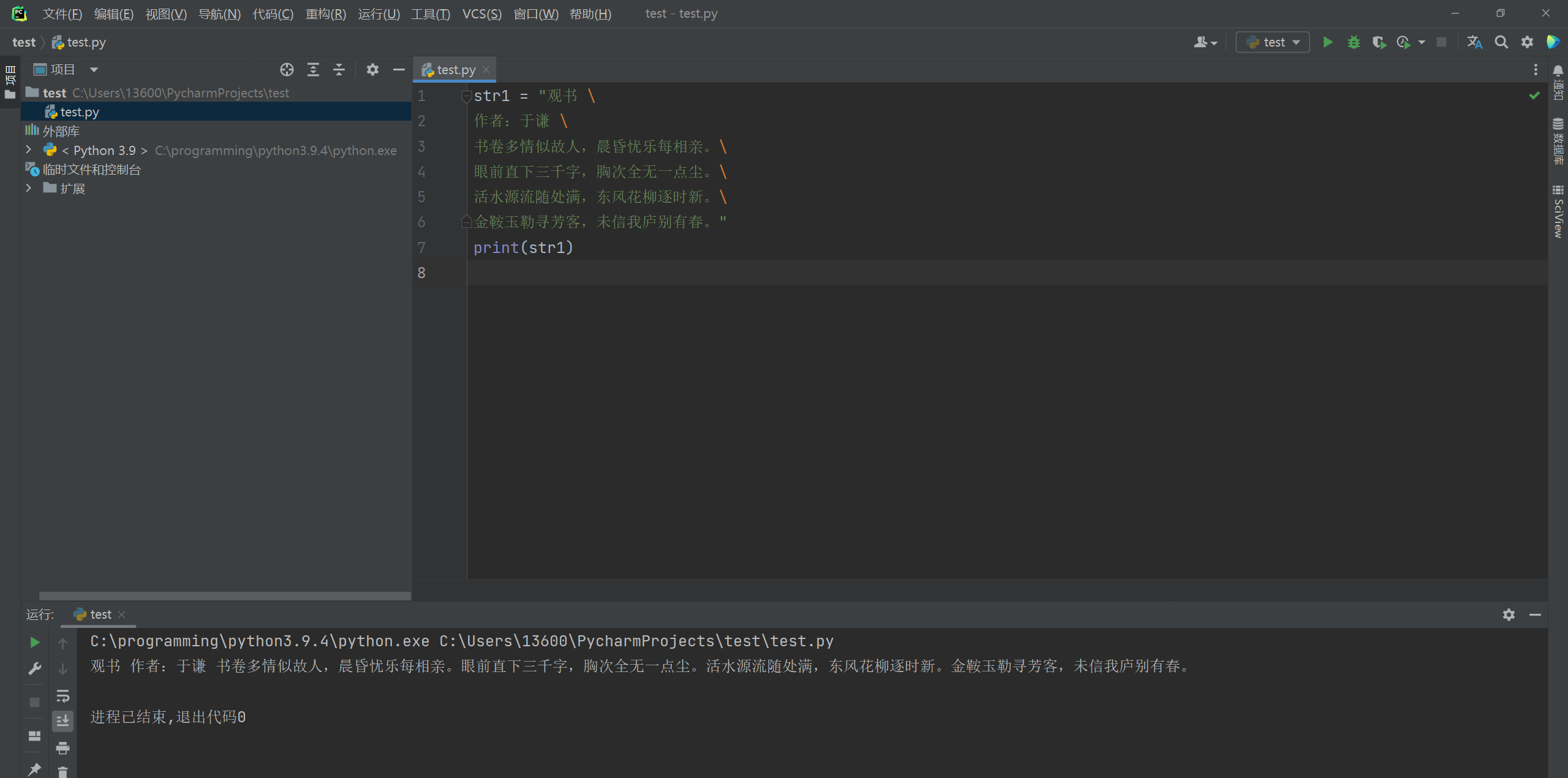
str1 = "观书 \ 作者:于谦 \ 书卷多情似故人, 晨昏忧乐每相亲。\ 眼前直下三千字, 胸次全无一点尘。\ 活水源流随处满, 东风花柳逐时新。\ 金鞍玉勒寻芳客, 未信我庐别有春。" print(str1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
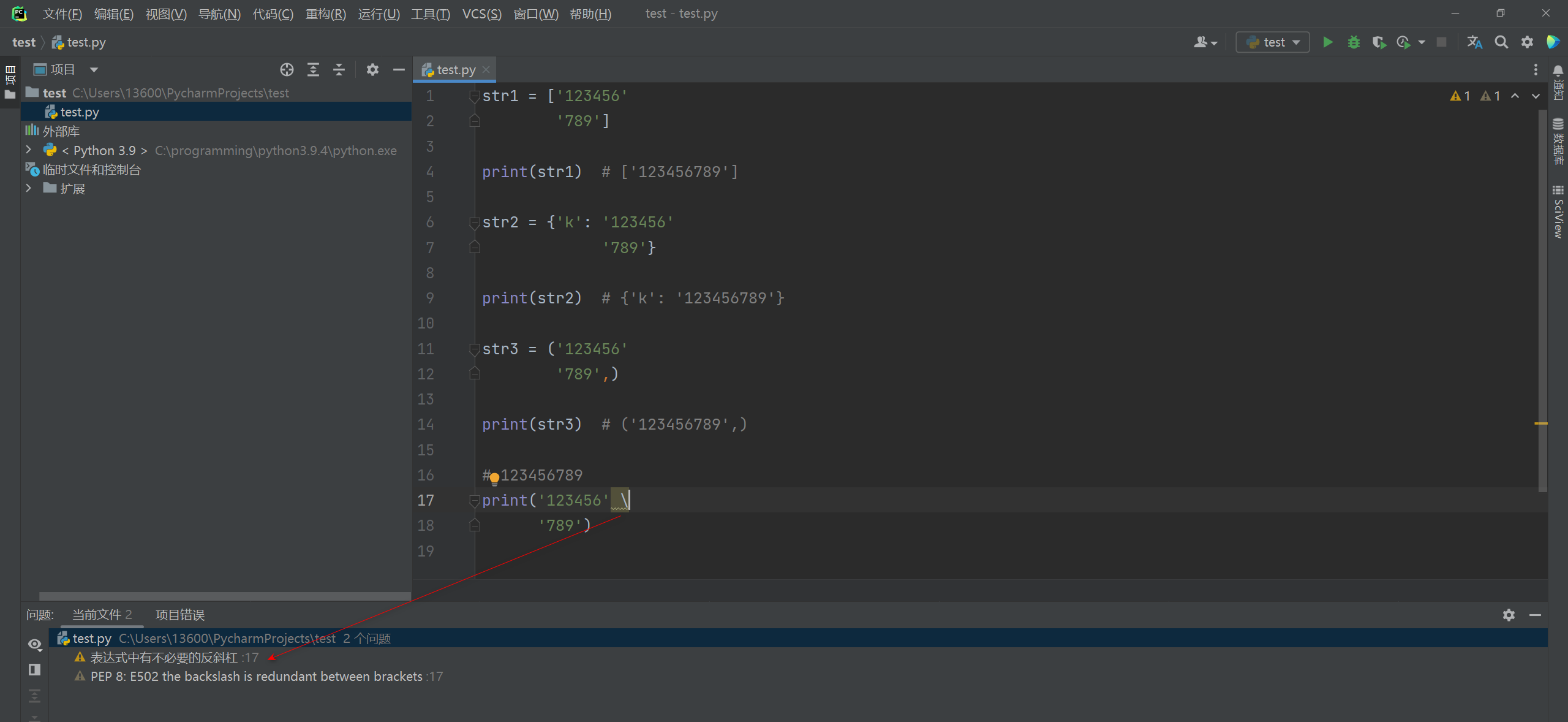
在处于括号(), 中括号[], 花括号{}中是反斜杠是可以省略的. 如果不省略会提示 PEP 8 规范问题. PEP 8: E502 the backslash is redundant between brackets.- 1
- 2
- 3
str1 = ['123456' '789'] print(str1) # ['123456789'] str2 = {'k': '123456' '789'} print(str2) # {'k': '123456789'} str3 = ('123456' '789',) print(str3) # ('123456789',) # 123456789 print('123456'\ '789')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2. 转义字符
转义字符(Escape character): 定义一些字母前加"\"来表示特殊的含义, 如: \n 表示换行.- 1
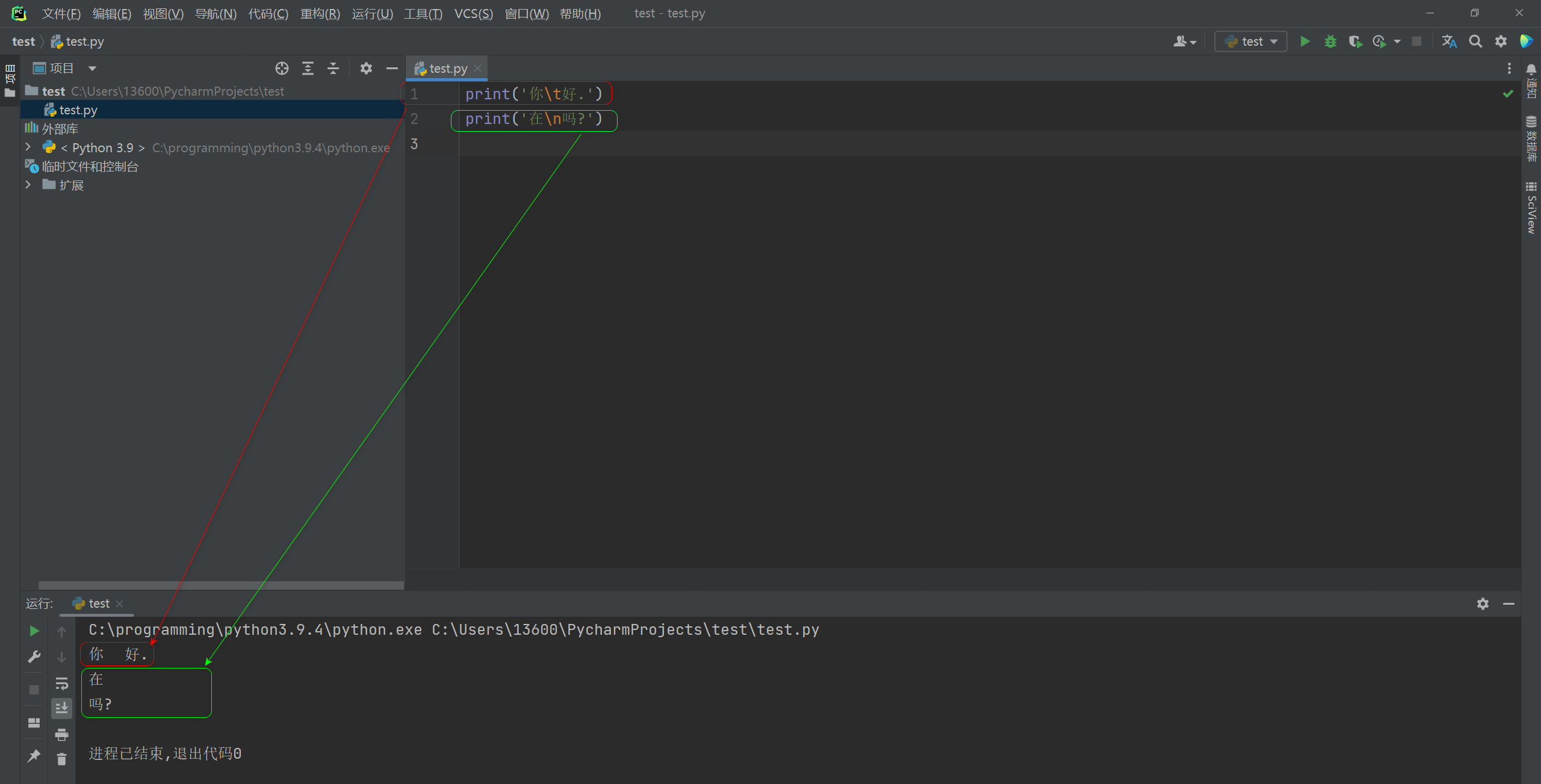
转义字符 意义 ASCII码值(十进制) \a 响铃(BEL), 不是喇叭响, 蜂鸣器响, 现在的计算机没了. 007 \b 退格(BS) , 将当前位置移到前一列 008 \f 换页(FF), 将当前位置移到下页开头 012 \n 换行(LF) , 将当前位置移到下一行开头 010 \r 回车(CR) , 将当前位置移到本行开头 013 \t 水平制表(HT) (跳到下一个TAB位置) 009 \v 垂直制表(VT) 011 \\ 代表一个反斜线字符’ 092 \’ 代表一个单引号字符 039 \" 代表一个双引号字符 034 ? 代表一个问号 063 \0 空字符(NUL) 000 \o 英文o, 以\o开头表示八进制 \x 以\x开头表示十六进制 print('你\t好.') print('在\n吗?')- 1
- 2
- 3
运行工具窗口显示: 你 好. 在 吗?- 1
- 2
- 3
- 4
1.3 打印引号
字符串以某种引号开始, 在往后再遇到自己就会中断. Pychon 解释器在解释时会报错.- 1
- 2

1. 错误示例
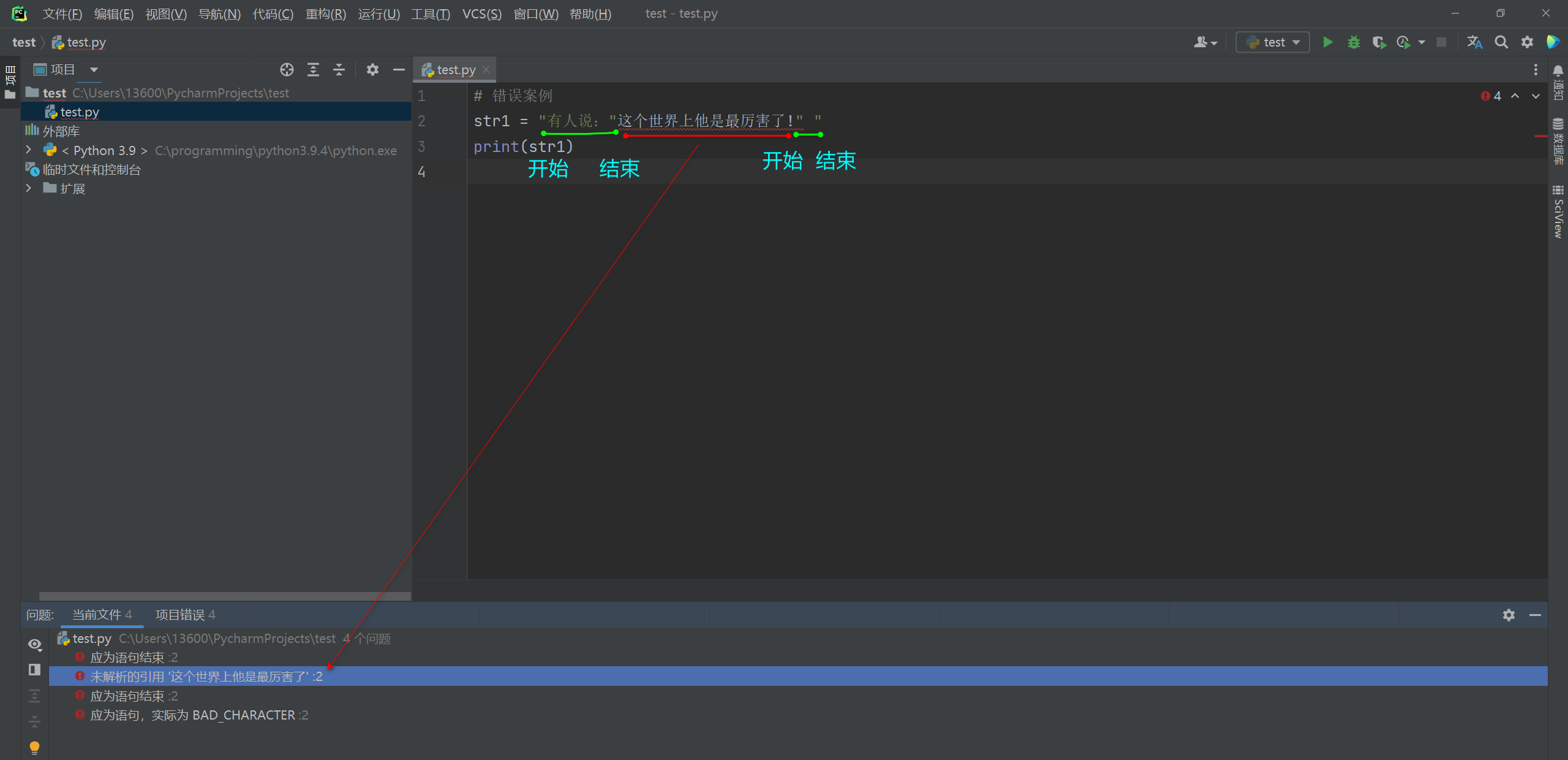
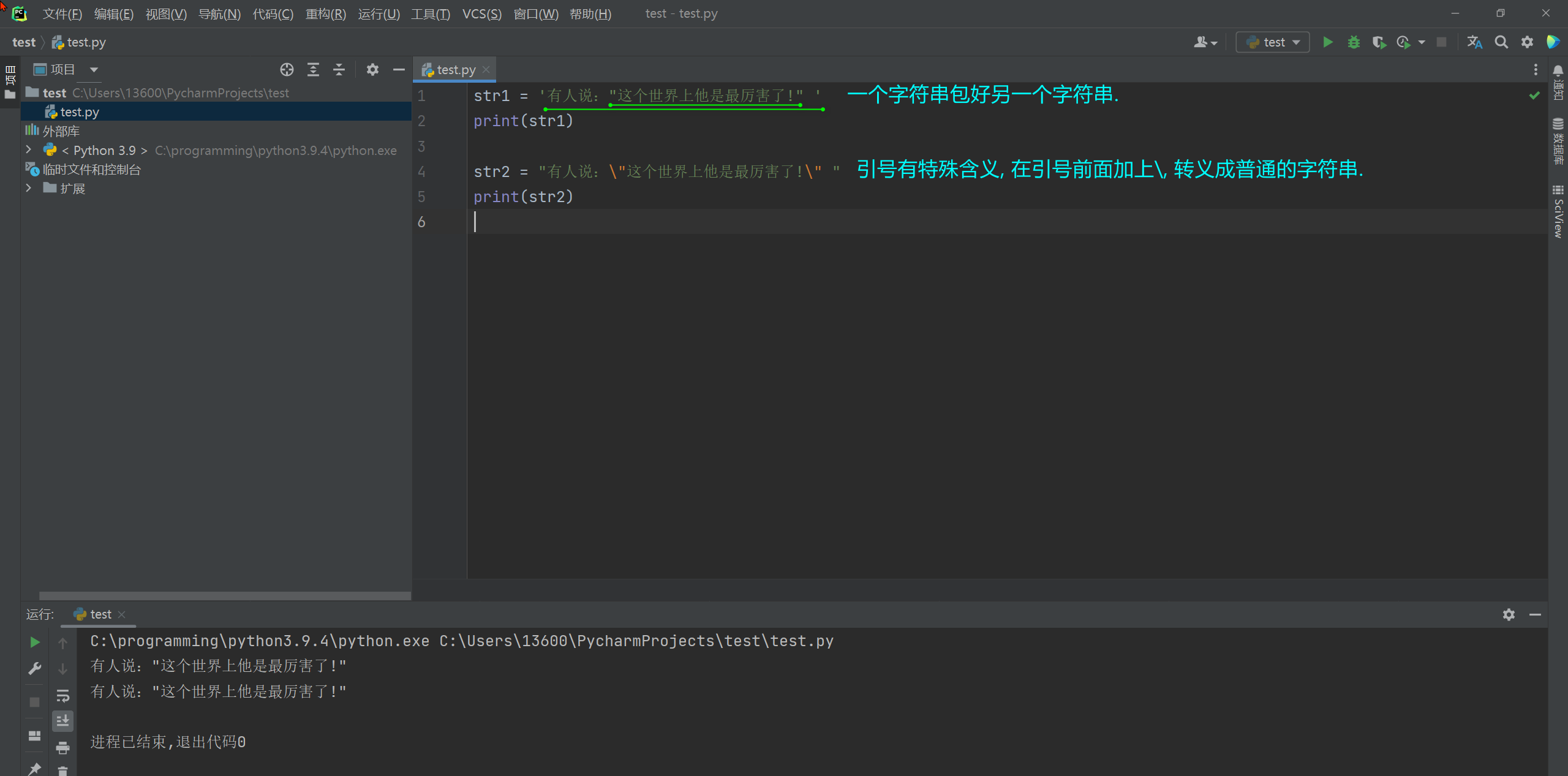
# 错误案例 str1 = "有人说:"这个世界上他是最厉害了!" " print(str1)- 1
- 2
- 3
- 4
运行工具窗口显示: File "C:\Users\13600\PycharmProjects\test\test.py", line 2 str1 = "有人说:"这个他是最厉害了!" " ^ 语法错误:无效语法 SyntaxError: invalid syntax- 1
- 2
- 3
- 4
- 5
- 6
2. 解决方法
解决方法: * 1. 在字符串中使用引号, 外层需要用不同类型的引号. * 2. 使用转义字符.- 1
- 2
- 3
str1 = '有人说:"这个世界上他是最厉害了!" ' print(str1) str2 = "有人说:\"这个世界上他是最厉害了!\" " print(str2)- 1
- 2
- 3
- 4
- 5
- 6
1.4 三引号
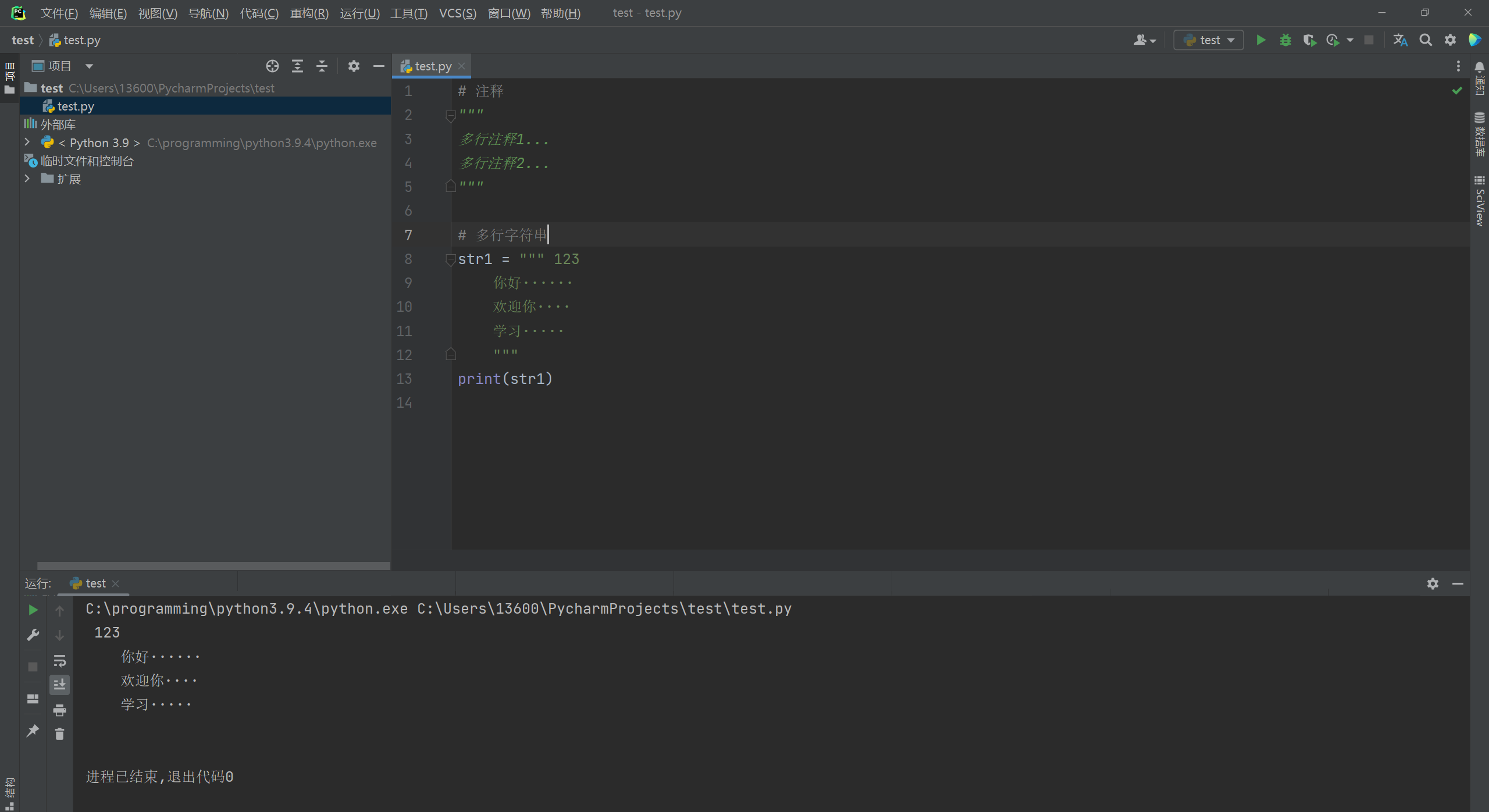
三引号引起来的字符, 当它的左边有赋值符号的时候是一个字符串对象, 否则就是注释语句.- 1
# 注释 """ 多行注释1... 多行注释2... """ # 多行语句 str1 = """ 123 你好······ 欢迎你···· 学习····· """ print(str1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
1.5 原始字符串
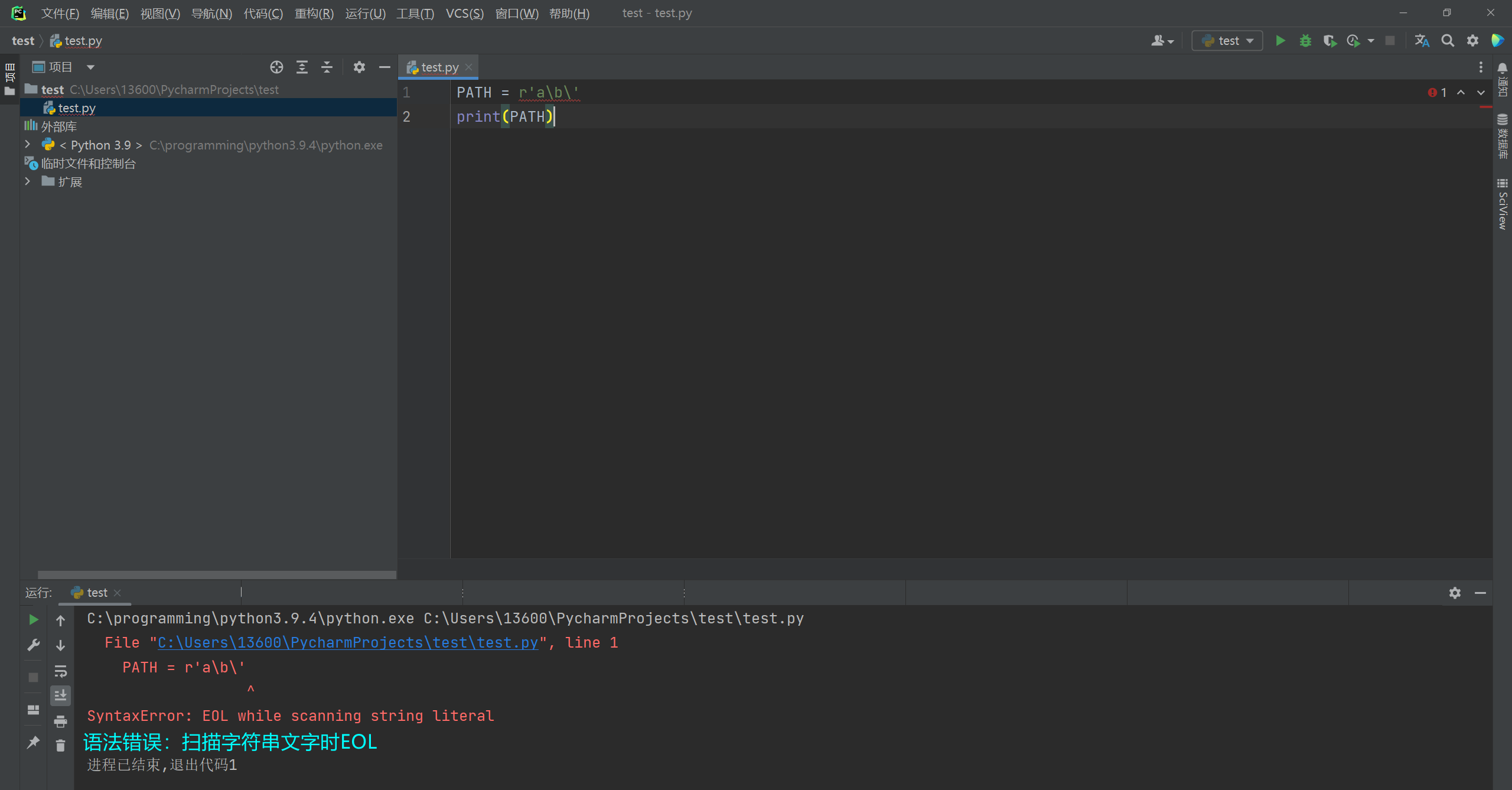
字符串中, 反斜杠'\'有着转义功能, 某个情况出现的下转义让解释器无法解析, 从而导致程序异常. 在字符串前面添加字母r, 转为原始字符串, 原始字符串让字符串原样输出. 取消掉部分部分'\'的转义功能. * 原始字符串末尾也不能带奇数个反斜杠, 因为这会引起后续引号的转义! 正确的样式: r'a\b\c' 错确的样式: r'a\b\' --> SyntaxError: EOL while scanning string literal- 1
- 2
- 3
- 4
- 5
- 6
1. 正确示例
PATH = r'a\b\c' print(PATH) # a\b\c- 1
- 2
- 3
2. 错误案例
PATH = r'a\b\' print(PATH)- 1
- 2
- 3
运行工具窗口显示: File "C:\Users\13600\PycharmProjects\test\test.py", line 1 PATH = r'a\b\' ^ # 语法错误:扫描字符串文字时EOL SyntaxError: EOL while scanning string literal- 1
- 2
- 3
- 4
- 5
- 6
2. 类型转换
Python 内置 str() 函数将括号内的数据转为字符串类型数据. 任意类型的数据都可以被转为字符串.- 1
str1 = str('abc') print(str1, type(str1)) # abc# 整型 print(str(123)) # 123 # 浮点数 print(str(123.4)) # 123.4 # 列表 print(str([1, 2, 3])) # [1, 2, 3] # 元组 print(str(('hello',))) # ('hello',) # 字典 print(str({'a': 123, 'b': 456})) # {'a': 123, 'b': 456} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3. 索引取值与切片
索引取值: 取一个元素. 字符串中每个字符占一个索引, 索引从0开始. 切片取值: 取多个元素. 取值格式: 字符串[start: stop: step] start 起始值参数: 起始位置, 从第几位开始取值. stop 上限值参数: 上限的位置, 只能获取到它的前一索引的值, 不包含它本身. step 步长参数: 从左往右正向取值, 步长是负数从右往左反向取值(start 与 stop 参数对换). 省略索引: 省略第一个参数: 默认参数为0, 从索引0开始截取. 省略第二个参数: 默认惨为列表的长度, 意味着切片直至列表的末尾. 省略第三个参数: 默认为1, 从左往右正向取值.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

str1 = '0123456789' # 取单个值. print(str1[0]) # 0 # 一共取9个值, 取索引0-8的值 print(str1[0:9]) # 012345678 # 超出也只能取全部的值. print(str1[0:30]) # 0123456789 # 省略第二个索引相当于使用列表的长度, 意味着切片直至列表的末尾. print(str1[0:]) # 0123456789 # 省略第一个索引相当于使用索引0. print(str1[:9]) # 012345678 # 倒序切片 # 负索引-1的值不会显示, -1是终止位不被包含. print(str1[-10:-1]) # 012345678 # 第一位到倒数第二位. print(str1[0:-1]) # 012345678 # 超出也只能从0取-1之间的值 等通于 [0:-1]. print(str1[-30:-1]) # 012345678 # 利用索引 倒退写法, 步长是倒退-1. print(str1[-1:-11:-1]) # 9876543210 # 倒取全部, 第一个 第二个 省略值互换. print(str1[::-1]) # 9876543210- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
4. 遍历字符串
for 循环语句可以依次获取字符串中的单个字符.- 1
str1 = '0123456789' # 遍历每个字符 for i in str1: print(i, end='--')- 1
- 2
- 3
- 4
- 5
运行工具窗口提示: 0--1--2--3--4--5--6--7--8--9--- 1
- 2
5. 统计长度
Python 内置 len() 函数统计序列类型的元素个数.- 1
str1 = '0123456789' print(len(str1)) # 10- 1
- 2
6. 拼接与复制
符号 作用 示例 + 加号 拼接字符串. ‘a’ + ‘b’ = ‘ab’ * 乘号 复制字符串. ‘a’ * 3 = ‘aaa’ Python 属于强类型语言, 不能类型的数据是无法互相操作的. Python 中为了方便程序员的使用: 使用+号, 让字符串与整型将加时, 使其不再表示加法, 而是拼接字符串. 使用*号, 让字符串与整型将乘时, 使其不再表示乘法, 而是重复n次.- 1
- 2
- 3
- 4
6.1 字符串的拼接
str1 = 'abc' print(str1 + 'def') # abcdef str1 += 'def' print(str1) # abcdef- 1
- 2
- 3
- 4
- 5
- 6
- 7
6.2 字符串的复制
str1 = 'abc' print(str1 * 2) # abcabc str1 *= 2 print(str1) # abcabc- 1
- 2
- 3
- 4
- 5
- 6
- 7
7. 字符比较大小
涉及字符串的比较, 会将字符转为 ASCII 表对应的十进制数来比较. ASCII 编码范围在 0-127, 定义了128个单字节字符. 超过这个范围则需要转为 Unicode 编码表对应的十进制数来比较. Unicode 编码范围在 0-65535, 定义了65536个单字节字符.- 1
- 2
- 3
- 4
- 5
ASCII值 控制字符 ASCII值 控制字符 ASCII值 控制字符 ASCII值 控制字符 0 NUT 32 (space) 64 @ 96 、 1 SOH 33 ! 65 A 97 a 2 STX 34 " 66 B 98 b 3 ETX 35 # 67 C 99 c 4 EOT 36 $ 68 D 100 d 5 ENQ 37 % 69 E 101 e 6 ACK 38 & 70 F 102 f 7 BEL 39 , 71 G 103 g 8 BS 40 ( 72 H 104 h 9 HT 41 ) 73 I 105 i 10 LF 42 * 74 J 106 j 11 VT 43 + 75 K 107 k 12 FF 44 , 76 L 108 l 13 CR 45 - 77 M 109 m 14 SO 46 . 78 N 110 n 15 SI 47 / 79 O 111 o 16 DLE 48 0 80 P 112 p 17 DCI 49 1 81 Q 113 q 18 DC2 50 2 82 R 114 r 19 DC3 51 3 83 S 115 s 20 DC4 52 4 84 T 116 t 21 NAK 53 5 85 U 117 u 22 SYN 54 6 86 V 118 v 23 TB 55 7 87 W 119 w 24 CAN 56 8 88 X 120 x 25 EM 57 9 89 Y 121 y 26 SUB 58 : 90 Z 122 z 27 ESC 59 ; 91 [ 123 { 28 FS 60 < 92 / 124 | 29 GS 61 = 93 ] 125 } 30 RS 62 > 94 ^ 126 ` 31 US 63 ? 95 _ 127 DEL 常用字符的ASCII码: 字符 | 十进制 0-9 : 30-39 A-Z : 65-90 a-z : 95-122- 1
- 2
- 3
- 4
- 5
# 两个字符串按左往右的顺序一位一位的依次做比较, 比较出一次结果就直接返回. str1 = 'ABC' str2 = 'ABD' print(str1 > str2) # False print(str1 < str2) # True- 1
- 2
- 3
- 4
- 5
- 6
- 7

str1 = 'a' str2 = 'b' print(str1 > str2) # False # 输入的字符串作为值 赋值 给变量 input_str = input('输入字符串>>>:') # 输入字符串>>>:(a) # 值相等 print(str1 == input_str) # True # id相等 print(str1 is input_str) #True- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
8. 成员运算
in 判断某个个体是否在某个群体当中, 返回布尔值. not in 判断某个个体是否不在某个群体当中, 返回布尔值.- 1
- 2
str1 = '0123456789' print('0' in str1) # True print('0' not in str1) # False- 1
- 2
- 3
- 4
- 5
9. 字符串常用方法
* 方法: 是让对象调用的函数. * 字符串的方法不会修改原值, 操作之后会得到一个新值, 如果要保留可以将值赋值给变量.- 1
- 2
9.1 字符串拼接
.join(可迭代对象) 方法适用于列表中的字符串元素相加, 拼接的列表中存在不是字符串的元素会报错.- 1
str1 = 'abc' str2 = 'def' list1 = [str1, str2] # 以 空字符串 做为拼接符 print(''.join(list1)) # abcdef # 以 - 做为拼接符 print('-'.join(list1)) # abc-def- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
9.2 格式化输出
.format() 方法, Python官方推荐的使用的格式化输入. .format() 方法使用{}占位, .format() 方法可以接送任意类型参数, 参数不能是变量. 使用方式一: {}默认按传递的参数依次获取值. 使用方式二:{}中写索引, 可以对参数进行多次调用. 索引是来源于format()的参数. 使用方式三: {}中写上变量名, .format()以关键字参数 变量名 = xxx 传参. * {} 内不可是的位置参数不能是变量.- 1
- 2
- 3
- 4
- 5
- 6
# 使用方式一 print('今天星期{}, 天气{}, 温度{}℃!'.format('一', '晴', 28)) # 使用方式二 print('现在时间是: {0}点{0}分{0}秒.' '距离下班时间还有{1}个小时{1}分{1}秒!'.format(13, 1)) # 使用方式三 print('{name}独断万古!'.format(name='荒天帝')) name = '王腾' print('吾儿{name}有大帝之姿!'.format(name=name)) """ # 错误使用方法 name ='王腾' print('吾儿{name}有大帝之姿!'.format(name)) """- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
运行工具窗口提示: 今天星期一, 天气晴, 温度28℃! 现在时间是: 13点13分13秒.距离下班时间还有1个小时1分1秒! 荒天帝独断万古! 吾儿王腾有大帝之姿!- 1
- 2
- 3
- 4
- 5
9.3 切分字符串
.split('字符') 方法指定一个字符为分割点进行切分, 被切分的的字符串会以列表类型存放. 指定切割的字符不会保留, 不写默认指定为空字符, 指定的字符必须存在字符串中. 切割方向: 从左往右 .split('指定字符', maxsplit =_) 从右往左 .rsplit('指定字符', maxsplit =_) ''.join() 将列表多个字符串元素拼接成字符串. 引号内指定一个拼接符号, 引号内默认不写则不使用分隔符. split 切分, join还原.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
str1 = 'abc and acg adf' # 默认按空格切分 print(str1.split()) # ['abc', 'and', 'acg', 'adf'] # 指定 | 作为分隔 , |不保留 str1 = '1 | 2 | 3| 4 | 5' print(str1.split('|')) # ['1 ', ' 2 ', ' 3', ' 4 ', ' 5'] # 从左往右最大切分一次 print(str1.split('|', maxsplit=1)) # ['1 ', ' 2 | 3| 4 | 5'] # 从左往右最大切分两次 print(str1.split('|', maxsplit=2)) # ['1 ', ' 2 ', ' 3| 4 | 5'] # 从右往左, 最大切分一次 print(str1.rsplit('|', maxsplit=1)) # ['1 | 2 | 3| 4 ', ' 5'] # 从右往左, 最大切分两次 print(str1.rsplit('|', maxsplit=2)) # ['1 | 2 | 3', ' 4 ', ' 5'] list1 = ['1 ', ' 2 ', ' 3', ' 4 ', ' 5'] # 以空字符串拼接 print(''.join(list1)) # 12345 # 以|拼接 print('|'.join(list1)) # 1|2|3|4|5- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
9.4 移除字符
.strip() 方法移除指定的首尾字符. .lstrip() 方法移除首部, 指定的的字符. .rstrip() 方法移除尾部, 指定的的字符. 不写都默认移除空字符. 需要移除的字符用引号引起来, 中间的无法移除. 注意点: aipoo移除'aoa' aoa 中的字符每个字符依次去 aipoo 前后匹配, 如果存在则移除.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
str1 = ' 01234 56789 ' # 默认移除首尾空字符 print(str1.strip()) # 01234 56789 str2 = '###123 456@@@' # 移除首尾 # print(str2.strip('#')) # 123 456@@@ # 移除首尾 @ print(str2.strip('@')) # ###123 456 # 移除首尾 # str3 = '###123 4566###' print(str3.lstrip('#')) # 123 4566### # 移除尾 print(str3.rstrip('#')) # ###123 4566 # 指定多个字符串移除 print('aipoo'.strip('aoa')) # ip- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
9.5 大小写转换
将纯字母字符转为 大写或者小写 其他的字符原样输出. .upper() 方法将字符串中的字母全转为大写. .lower() 方法将字符串中的字母全转为小写.- 1
- 2
- 3
str1 = 'AbCdEfG' # 全转大写 print(str1.upper()) # ABCDEFG # 全转小写 print(str1.lower()) # abcdefg- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
设计一个程序, 将输入的字母 与 验证码 全转为大写或小写 在做比较.- 1
# 1. 创建一个验证码 code = 'sAD8' # 2. 将验证码发给用户 print(f'xx验证码是:{code}') # 3. 获取用户输入的验证码 input_code = input('输入验证码>>:') # 4. 将输入的验证码 与 验证码 转为大写 做比较 if input_code.upper() == code.upper(): print('验证成功!') else: print('验证失败!')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
运行工具窗口提示: xx验证码是:sAD8 输入验证码>>:(sad8) 验证成功!- 1
- 2
- 3
- 4
9.6 大小写判断
.isupper('字符串') 判断字符串中的字母是否为全大写, 其它字符不会影响判断. .islower('字符串') 判断字符串中的字母是否为全小写, 其它字符不会影响判断. * 凡是方法描述信息带判断的, 返回的结果为布尔值.- 1
- 2
- 3
str1 = 'AbCdEfG' str2 = 'ABC' str3 = 'abc' # str1的字母是否为全大写 或全小写 print(str1.isupper(), str1.islower()) # str2的字符串是否为全大写, str3的字符串是否为全小写 print(str2.isupper(), str3.islower()) # 其他字符不受影响 str4 = 'a我' print(str4.islower())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
运行工具窗口提示: False False True True True- 1
- 2
- 3
- 4
9.7 开头结尾判断
.startswith('字符串') 判断字符串是否以某个字符串开头, 区分大小写. .endswith('字符串') 判断字符串是否以某个字符串结尾, 区分大小写.- 1
- 2
str1 = 'Hello world!' # 判断字符串是否以h开头(区分大小写) print(str1.startswith('h')) # 判断字符串是否以H开头 print(str1.startswith('H')) # 判断字符串是否以Hello开头 print(str1.startswith('Hello')) # 判断字符串是否以!结尾 print(str1.endswith('!'))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
运行工具窗口提示: False True True True- 1
- 2
- 3
- 4
- 5
9.8 字符替换
.replace() 方法将指定字符替换. 格式: .replace(old, new, count=None) old 需要替换的字符参数, 参数必须写. new 替换的字符参数, 参数必须写. count 替换的次数, 默认全部替换.- 1
- 2
- 3
- 4
- 5
- 6
str1 = 'aaaa aaaa aaaa' # 将所有a替换为b print(str1.replace('a', 'b')) # bbbb bbbb bbbb # 将所有a替换为b, 替换4次 print(str1.replace('a', 'b', 4)) # bbbb aaaa aaaa- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
9.9 纯整型字符串判断
.isdigit('字符串') 方法判断字符串是否为纯整数字字符串, 浮点型不行.- 1
str1 = '123456' str2 = '12.3' str3 = 'a123' str4 = ' 123' print(str1.isdigit()) # True print(str2.isdigit()) # False print(str3.isdigit()) # False print(str4.isdigit()) # False- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
设计一个程序, 模拟登录, 密码是6位数整型. 要求用户输入密码, 程序对输入进行类型转换, 对密码进行校验, 避免字符串转整型报错. 验证成功退出程序, 否则要求继续输入. * 设计程序的时候先写所条件为 False 的代码块, 可以提高代码的可读性.- 1
- 2
- 3
- 4
# 1. 创建密码 pwd = 123456 # 2. 循环代码块 while True: # 2.1 获取用户输入 input_pwd = input('输入6位数的密码>>>:') # 2.2 判断字符串是否为纯整型数字 if not input_pwd.isdigit(): print('密码是纯数字!, 请重新输入!') continue # 2.3 对字符串进行类型转换 input_pwd = int(input_pwd) # 2.4 校验密码 if input_pwd != pwd: print('密码错误!, 请重新输入!') continue # 2.5 登入成功退出循环 print('登录成功!') break- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
运行工具窗口提示: 输入6位数的密码>>>:(qwe) 密码是纯数字!, 请重新输入! 输入6位数的密码>>>:(123) 密码错误!, 请重新输入! 输入6位数的密码>>>:(123456) 登录成功!- 1
- 2
- 3
- 4
- 5
- 6
- 7
9.10 纯字母判断
.isalpha() 方法判断字符串中是否为纯字母.- 1
str1 = 'asd123' str2 = 'asd' print(str1.isalpha()) # False print(str2.isalpha()) # True- 1
- 2
- 3
- 4
- 5
- 6
9.11 纯数字字母判断
.isalnum() 方法判断字符串中是否只有字母和数字.- 1
str1 = 'asd123' str2 = 'asd1.23' print(str1.isalnum()) # True print(str2.isalnum()) # False- 1
- 2
- 3
- 4
- 5
- 6
设计一个程序, 统计下列字符串中的符号, 除数字和字母都是符号, 空格也是符号.- 1
str1 = 'a1sd564ew9r/7wa/*7sd49c8aw4ea1r98""":::~!@#17*/ 29e7w+91w49d ' # 计数器 count = 0 # 遍历字符串 for i in str1: if not i.isalnum(): count += 1 print(count) # 19- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
9.12 首字母大写
.title() 方法将字符串中所有单词的首字母转为大写. .capitalize() 方法将字符串中第一个单词首字母转为大写.- 1
- 2
str1 = 'my name is kid my age is 18.' print(str1.title()) # My Name Is Kid My Age Is 18. print(str1.capitalize()) # My name is kid my age is 18.- 1
- 2
- 3
- 4
- 5
9.13 大小写互换
.swapcase() 方法将字符串中的大写字母转为小写, 将小写字母转为大写.- 1
str2 = 'AbCd' print(str2.swapcase()) # aBcD- 1
- 2
- 3
9.14 查询索引
.find() 方法从左往右查找指定字符对应的索引, 找到就返回索引的值, 如果查找的字符不存在则返回-1. .rfind() 方法从右往左查找指定字符对应的索引, 找到就返回索引的值, 如果查找的字符不存在则返回-1. .index() 方法从左往右查找指定字符对应的索引, 找到就返回索引的值, 找不到就报错. .rindex() 方法从右往左查找指定字符对应的索引, 找到就返回索引的值, 找不到就报错. * 提供的参数使一个字符串, 只对首个字符进行查询.- 1
- 2
- 3
- 4
- 5
str1 = 'My name is kid my age is 18.' print(str1.find('m')) # 5 print(str1.rfind('m')) # -1 print(str1.index('m')) # 5 print(str1.rindex('m')) # 15 # print(str1.index('2')) # 报错 substring not found 未找到子字符串- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
9.15 字符出现次数
.count() 方法统计某个字符组合在字符串中出现的次数.- 1
str1 = 'My name is kid my age is 18.' print(str1.count('m')) # 2 print(str1.count('my')) # 1- 1
- 2
- 3
- 4
9.16 文本对齐
.center(字符宽度, '字符') 方法指定字符与字符宽度, 让字符串居中. .ljust( 字符宽度, '字符') 方法指定字符与字符宽度, 让字符串左对齐. .rjust( 字符宽度, '字符') 方法指定字符与字符宽度, 让字符串右对齐.- 1
- 2
- 3
message = '输出' print(message.center(16, '-')) print(message.ljust(16, '-')) print(message.rjust(16, '-'))- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行工具窗口提示: -------输出------- 输出-------------- --------------输出- 1
- 2
- 3
- 4
10. 练习
name = " kiD" 1. 移除 name 变量对应的值两边的空格,并输出处理结果 print(name.strip()) 2. 判断 name 变量对应的值是否以 "ki" 开头,并输出结果 print(name.startswith('ki')) 3. 判断 name 变量对应的值是否以 "d" 结尾,并输出结果 print(name.endswith('d')) 4. 将 name 变量对应的值中的 “i” 替换为 “p”,并输出结果 print(name.replace('i', 'p')) 5. 将 name 变量对应的值根据 “i” 分割,并输出结果. print(name.split('i')) 6. 将 name 变量对应的值变大写,并输出结果 print(name.upper()) 7. 将 name 变量对应的值变小写,并输出结果 print(name.lower()) 8. 请输出 name 变量对应的值的第 2 个字符? print(name[1]) 9. 请输出 name 变量对应的值的前 3 个字符? print(name[:3]) 10. 请输出 name 变量对应的值的后 2 个字符? print(name[2:]) 11. 请输出 name 变量对应的值中 “d” 所在索引位置? print(name.index('i')) 12. 获取子序列,去掉最后一个字符.如: kid 则获取 ki. print(name[0:len(name)-1])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
文章的段落全是代码块包裹的, 留言0是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言1是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言2是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言3是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言4是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言5是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言6是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言7是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言8是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言9是为了避免文章提示质量低.
-
相关阅读:
HotSpot的算法实现
微信小程序生命周期
基于ATmega16单片机和GPS的多用途定位仪设计
JVM 虚拟机
leetcode 55. 跳跃游戏
RFID设备在自动化堆场中的管理应用
静态代理和动态代理
web前端期末大作业 html+css学生心理 7页主题网页设计
axios请求多个服务器
使用Spring Data Elasticsearch 进行索引的增、删、改、查
- 原文地址:https://blog.csdn.net/qq_46137324/article/details/127701778
