-
应用层处理 tcp 粘/拆包问题
背景
很多TCP相关的八股文中都有粘包和拆包的概念,但理解TCP基本原理之后就明白了 TCP 是个字节流协议,根本没有粘/拆包这个问题,所以通常指的其实是应用层要如何从一堆数据[也就是字节数组]中,反序列化出自己的数据结构。
底层原理
应用层读取 TCP 流数据,归根结底由 read() 系统调用[无论是阻塞的还是非阻塞的], 把数据从 os 的 socket 缓冲区中以字节数组的形式读出来。
应用层,也就是我们写的代码或者类库,面对拿到的字节数组,需要思考如何处理,而这不属于tcp的范畴。
想要把字节数组转为自己定义的数据结构[也就是反序列化], 那么需要考虑:如何确定一个应用层协议数据体的大小?
例如收到的字节数组是 200Byte, 而应用层对应的数据[或者说对象,结构体等]大小不确定,就没办法反序列化。解决方案
如何界定应用层的数据体大小,进一步反序列化,通常有3种方式:
-
固定大小的数据体。 例如规定是 128Byte, 那么在收到字节数组之后,每次取128Byte,进行解析就搞定了。
优点:实现起来最简单 缺点:规定太大了需要填充,太小了要切分,不符合现实情况。 -
特殊字符分割。 例如规定,数据体的末尾是 # 。 那么在收到字节数组之后,每次把数据都取出来[放到自己开辟的一个缓冲区里],然后扫描找 # , 找到后进行解析 0 ~ index 的 Byte 数据就可以了,然后要记录缓冲区里面的位置,等待下一次读取寻找 #。 redis 协议和 http 协议的请求头部分就是这么干的,分别用 # 和 换行进行分割。
-
指定数据体的长度。 一般需要结合前两种方式。例如结根据二种方式,可以解析出http 请求头部分,然后请求头中有个字段叫 content-length , 用来告诉服务器紧跟在请求头后面的请求体的具体字节大小,那么服务端应用层就能根据这个大小读取对应的字节数进行解析了。
一些 tips
- 现实应用中,一般是第三种方案比较多。
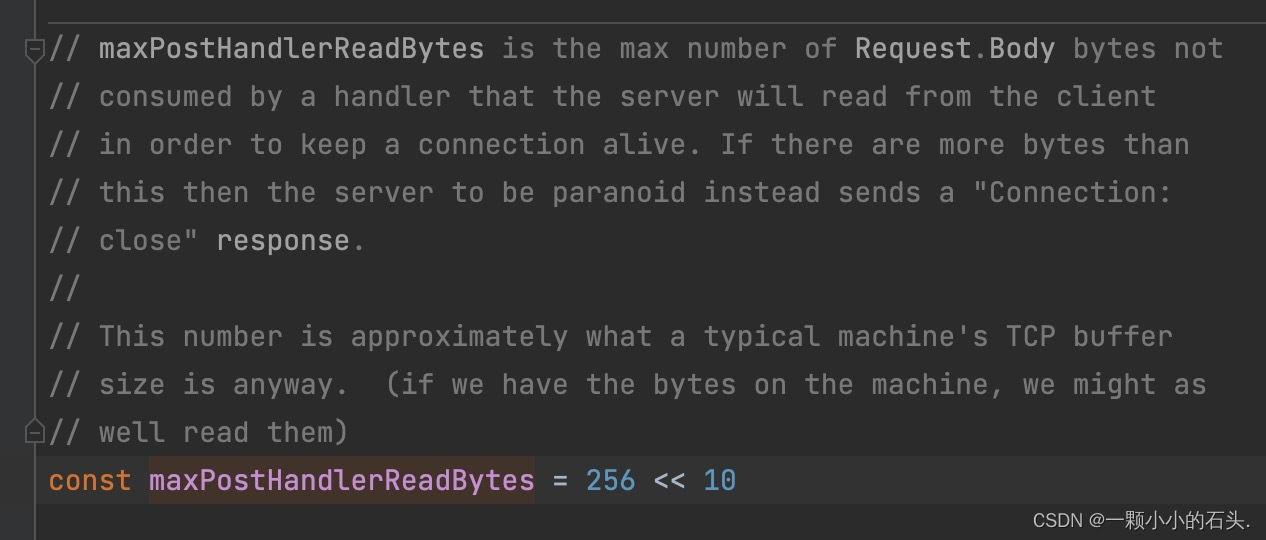
- 应用层通过 read() 从tcp流中读数据之后,需要自己找个地方缓冲起来。这个缓冲区要能自己扩容,例如采用方案2时,第一次读了100Byte没读到分割,那么要读第二次,第三次,直到读取到。但也要防止客户端恶意攻击,一直填充非分割字符数据,导致缓冲区OOM,所以要有个最大大小限制,超过了就说明客户端是恶意的或者数据量过大,进行异常处理。例如golang自带的http包中规定的这个最大值是 256MB, 超过之后就主动断开链接了。
https://www.zhihu.com/question/20210025/answer/1982654161
-
-
相关阅读:
SpringBoot查询数据时报空指针异常
网络编程开发及实战(下)
【云原生 | 从零开始学Kubernetes】二十七、配置管理中心Secret和rbac授权
最新|全新风格原创YOLOv7、YOLOv5和YOLOX网络结构解析图
GEE中核函数在不同缩放级别下的区别
IDEA 2021.2.2设置自动热部署
Docker Compose 一键快速部署 RocketMQ
pg数据库实现 根据两个表某一个字段一样,去更新另一个字段的sql 语句
深度分析React源码中的合成事件
与BBA争夺市场,阿维塔「智能电动」首战目标怎么定?
- 原文地址:https://blog.csdn.net/qq_37186947/article/details/127661868