-
[spark]transformation算子
1.sample算子
1)说明
sample算子:对rdd中的数据进行抽样。一个非常重要的作用就是开看rdd中数据的分布,进行各种调优与优化。
数据倾斜:数据分布的不均匀,shuffle会将相同key的数据汇总到一台机器上,就会导致某些task执行的特别慢。
找到哪些发生数据倾斜的key:sample算子+reduceByKey就可以知道哪一个key出现次数最多,出现次数最多的key往往就是发生数据倾斜的key,找到这个key后就可以进行数据倾斜优化。
如果用reduceByKey显然能统计出key的次数,但是该方法本很还是会造成数据倾斜,所以不采用这种方式。
2)用法

参数 :
withReplacement:是否可替换,确定抽样方法。true为可放回抽同样,false为不可放回抽样。fraction(小数):确定抽样比例,范围(0,1)
seed:种子数

2.map、mapPartition、mapPartitionWithIndex
1)map(f:T=>U)
对rdd中每个元素调用一次f函数,效率低。该函数是有一个参数,有一个返回值的函数。

输出:

说明:map和foreach都是窄依赖,所以task是并行执行的,分区是按照Range进行分区的,并且有的task执行的快,有的task执行的慢,所以输出顺序不确定。
2)mapPartitions(f:Iterator[T]=>Iterator[U])
该函数是对该rdd被分成的每一个partition调用一次f函数,效率比map高。
迭代器:可遍历的东西就是迭代器,比如集合。

输出:3 5 7 2 8 6 4
说明: partition=>parititon.map(_*7)是参数和返回值都是迭代器的函数
3)mapPartitionsWithIndex(f:(Int,Iterator[T])=>Iterator[U])
该函数也是对该rdd被分成的每一个partition调用一次f函数,该函数的参数是:(index,迭代器)即分区号和迭代器,返回值是迭代器。该算子和mapPartition的区别是:多了一个index,该index代表的就是当前被操作的paritition的编号,一个rdd被分为多个partition,每个partition都有一个编号,编号从0开始,假如有N个分区,编号的取值范围就是[0,N-1],通过该index可以清楚的看到每一个分区中数据的分布。

输出

说明:
mapPartitionsWithIndex算子和foreach算子都是窄依赖,即task是并行执行的。
分区是按照Range进行分区的,有的task执行的快有的task执行的慢,所以每次输出顺序不一样。

3.union(窄依赖)
union(other:RDD[T]):RDD[T]
hive中:union去重且排序,union all不去重不排序
spark的union相当于hive的union all
union只是将两个rdd的分区进行了拼接,它是一个窄依赖
4.distinct(宽依赖)

作用:将所有分区内的元素收集到一块进行去重,再将去重后的数据进行分区,参数指的是分多少个分区。
 输出
输出[0]List(1, 3, 7, 9, 5)
5.intersection(宽依赖)

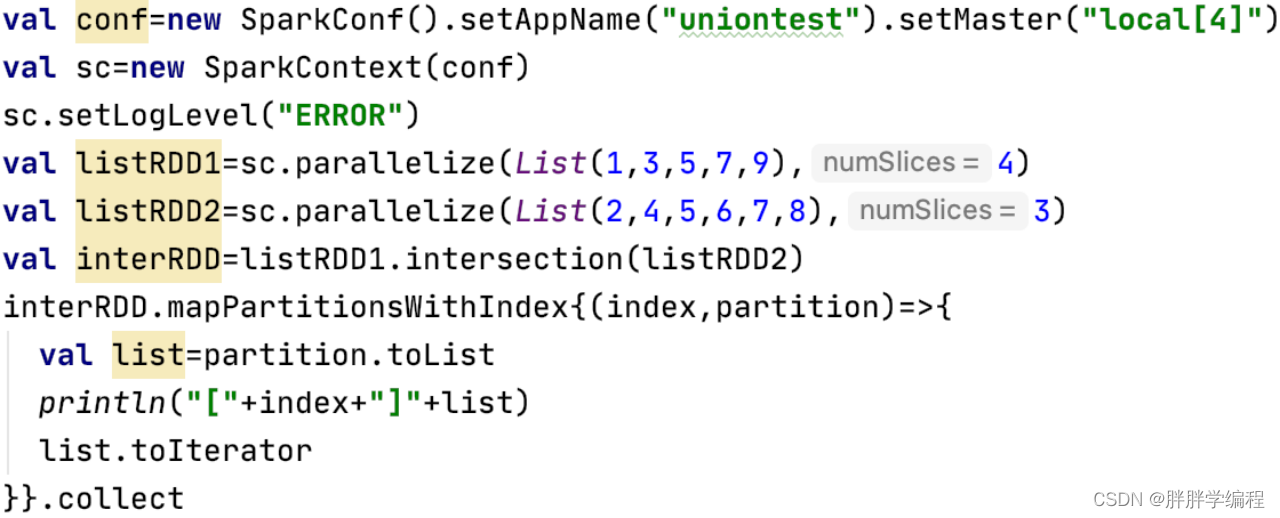

6.groupByKey(宽依赖)、groupBy(宽依赖)
1)groupByKey(numPartitions:Int):RDD[K,Iterable[V]]
作用:按照key将数据进行分组,groupByKey操作的RDD的数据类型是k-v类型的。
参数numPartitions:指结果RDD的分区个数,也可以不写参数,默认是和父RDD一样的分区数,返回值是一个元组,第一个值是key的值,第二个值是该key进行分组的value组成的迭代器。
reduceByKey是有本地预聚合操作的,而这个groupByKey是没有本地预聚合操作的。所以不能groupByKey就不要用它,可以用reduceByKey或aggregateByKey替代。
2)groupBy(f:T=>K):RDD[(K,Iterable[T])]
内部调用的是groupByKey,最好用reduceByKey或aggregateByKey代替。
和groupByKey不同的是它操作的不是k-v类型,它的参数是一个函数f,这个函数的返回值K会作为分组的key,value是f函数中的参数T,groupBy按照这个key进行分组。groupBy的返回值和groupByKey一毛一样。

输出:
河北:List(1,小红)
北京:List(2,小明)
黑龙江:List(3,小灰, 4,小微)

输出:
黑龙江:List(3,小灰,黑龙江, 4,小微,黑龙江)北京:List(2,小明,北京)
河北:List(1,小红,河北)
7.join(两个rdd的分区相同时是窄依赖,不同时是宽依赖)
join操作的必须是k-v类型的RDD
1)across join交叉连接(笛卡尔积)
2)内连接

参数是一个k-v格式的RDD,返回值也是一个元组,元组的第一个值是key,第二个值是两个集合的value组成的元组。
A join B on A.id=B.id
join也可以写成inner join。获取A和B中能够关联上的数据。得到的结果一定是一定的。
3)外连接
外连接的输出数据中一张表中的数据是不确定的,可能有,可能没有。
可能有可能没有的数据类型为Option,Option只有两个值Some(有),None(没有)
a)leftOuterJoin左外连接

左表数据原样输出,右表关联上的显示,关联不上的显示null。
b)rightOuterJoin右外连接
右外连接,右表数据原样输出,左边关联上的显示,关联不上的显示为null。
c)fullOuterJoin全外连接
分别以两张表为基准表,关联上的显示,关联不上的显示为null。
4)半连接(spark不支持半连接,但Hive支持半连接)
5)例子



输出:

8.cogroup
1)

rdd1.groupByKey:将rdd1按照它的key进行分组,返回key,value组成的元组。其中value是个迭代器,是相同key对应的值组成的迭代器。
2)

cogroup这个单词的意思:在两个或多个关系中的分组
作用:就是对两个K-V键值对分别执行groupByKey操作,cogroup产生的结果都在一个分区中。
rdd1.cogroup(rdd2):将rdd1和rdd2按照他们相同的key进行分组,返回key,rdd1的value,rdd2的value组成的元组,在这个元组中._1是key,._2是(value1,value2),其中rdd1的value,rdd2的value都是迭代器,是相同key对应的值组成的迭代器。

 9.reudceByKey(宽依赖)
9.reudceByKey(宽依赖)
reduceByKey:相当于先将数据进行分组(groupByKey)操作,然后再对每一个组执行reduce操作,进行聚合。

- val rdd=sc.parallelize(List(1,2,3,4,5,6,1,2,1))
- println(rdd.reduce(_+_))//25
注:reduceByKey是一个transformation算子,reduce是一个action算子。
 10.重分区:coelesce、repartition
10.重分区:coelesce、repartitioncoalesce:使合并
注:让分区变少是不走shuffle的,让分区变多是走shuffle的。
a)coalesce(numPartition,shuffle=false)
即不走shuffle,只能合并分区,它仅仅是将rdd的分区进行简单的合并,不走shuffle。将原先的N个分区进行合并,合并之后的分区个数为numPartition指定的个数,在这种情况下,如果numPartition的个数大于原本RDD中的分区数,coalesce是不会进行任何处理的。
b)coalesce(numPartition,shuffle=true)
走shuffle,可以增大分区,新的rdd的每个分区需要上一个rdd的所有分区的数据,因此走shuffle。
也可以用repartition(numPartition)来替代coalesce(numPartition,shuffle=true)
因为

重分区在特定情况下是非常必要的,比如在etl清洗过程中,有可能过滤掉很多的脏数据,假如原先100个分区,etl之后减少了30%的数据,此时原先分区中的数据不饱和,一个分区如果对应一个集群上的block,则是128MB,此时一个块不够128M,浪费了资源,这时就可以进行重分区,减少分区个数。

输出

11.combineByKey、aggregateByKey
1)combineByKey
combine:结合,combiner集合器
combineByKey是spark中的底层聚合操作:
reudceByKey的底层:combineByKeyWithClassTag
groupByKey的底层:combineByKeyWithClassTag
aggregateByKey的:combineByKeyWithClassTag
而combineByKey是combineByKeyWithClassTag的缩写
combineByKey的作用:为聚合提供一些优化手段,实现自定义的聚合操作。

注:
C是聚合之后值的数据类型
createCombiner、mergeValue、mergeCombiners是调用combineByKey要传入的3个函数。
其中createCombiner、mergeValue是对同一个分区进行处理,mergeCombiners是对多个分区进行处理。
a)combineByKey模拟groupByKey
这种模拟只是功能上的模拟,groupByKey没有本地预聚合操作,但是combineByKey模拟出来的groupByKey是有本地聚合操作的。



b)combineByKey模拟reduceByKey


2)aggregateByKey
aggregateByKey简化了combineByKey的第一步,aggregateByKey直接提供了初始值。

a)aggregateByKey模拟groupByKey


b)aggregateByKey模拟reduceByKey


12.mapValues
将键值对的每一个value都应用一个函数,但是key不会发生变化。

输出

-
相关阅读:
企业电子招投标采购系统——功能模块&功能描述+数字化采购管理 采购招投标
TikTok在美正式推出电商业务,变现路径直接改变!
并查集 size 的优化
Flink中的时间和窗口 完整使用 (第六章)
【Spring】使用xml配置AOP
基于stm32单片机的电压报警系统Proteus仿真
flink-sql所有数据类型
二十二、商城 - 商品录入-FastDFS(10)
基于人工水母优化的BP神经网络(分类应用) - 附代码
C语言百日刷题第九天
- 原文地址:https://blog.csdn.net/qq_35896718/article/details/127525635