-
分类判别式模型——逻辑斯特回归曲线
逻辑斯特回归
Discriminative Model
——判别式模型
Function set
σ ( z ) = 1 1 + e x p ( − z ) P w , b ( C 1 ∣ x ) = σ ( z ) z = w ∗ x + b = ∑ i w i x i + b \sigma(z)=\frac{1}{1+exp(-z)}\\ P_{w,b}(C_1|x)=\sigma(z)\\ z=w*x+b=\sum_iw_ix_i+b σ(z)=1+exp(−z)1Pw,b(C1∣x)=σ(z)z=w∗x+b=i∑wixi+b
因此我们的Function Set:
f w , b ( x ) = P w , b ( C 1 ∣ x ) = σ ( z ) f_{w,b}(x)=P_{w,b}(C_1|x)=\sigma(z) fw,b(x)=Pw,b(C1∣x)=σ(z)

因为z经过了逻辑斯特回归曲线,因此输出在0-1之间
Goodness of a Function

给定一组w和b
L ( w , b ) = f w , b ( x 1 ) f w , b ( x 2 ) ( 1 − f w , b ( x 3 ) ) . . . f w , b ( x N ) L(w,b)=f_{w,b}(x^1)f_{w,b}(x^2)(1-f_{w,b}(x^3))...f_{w,b}(x^N) L(w,b)=fw,b(x1)fw,b(x2)(1−fw,b(x3))...fw,b(xN)
然后找到 w ∗ 和 b ∗ w^*和b^* w∗和b∗使得 a r g max w , b L ( w , b ) arg\max_{w,b}L(w,b) argmaxw,bL(w,b)
数学上等价于 a r g min w , b − ln L ( w , b ) arg\min_{w,b}-\ln L(w,b) argminw,b−lnL(w,b)
− ln L ( w , b ) = − l n f w , b ( x 1 ) − l n f w , b ( x 2 ) − l n ( 1 − f w , b ( x 3 ) ) . . . -\ln L(w,b)=-lnf_{w,b}(x^1)-lnf_{w,b}(x^2)-ln(1-f_{w,b}(x^3))... −lnL(w,b)=−lnfw,b(x1)−lnfw,b(x2)−ln(1−fw,b(x3))...
——当我们将类别用不同的y值做tag时后面的项数都可以写成如下


最后得到的和项——其实是伯努利分布的交叉熵
交叉熵的含义是,代表两个分布有多接近
如果两个分布一模一样,则交叉熵=0
——因此,本质上,我们是希望找到一个分布,能够与训练集上的分布尽可能的接近
——即 p ( x ) = f w , b ( x n ) p(x)=f_{w,b}(x^n) p(x)=fw,b(xn) 和 y ^ n \hat{y}^n y^n 的分布尽可能接近
——而这一步,在数学上的表示是,我们希望最小化两个分布之间的交叉熵
Find the best Function
− ln L ( w , b ) = ∑ n − [ y ^ n ln f w , b ( x n ) + ( 1 − y ^ n ) ln ( l − f w , b ( x n ) ) ] -\ln L(w,b)=\sum_n-[\hat{y}^n\ln f_{w,b}(x^n)+(1-\hat{y}^n)\ln (l-f_{w,b}(x^n))] −lnL(w,b)=n∑−[y^nlnfw,b(xn)+(1−y^n)ln(l−fw,b(xn))]
如果找到最优的w和b,用梯度下降法
——求左式子微分

——求右式子微分

——得到整条式子的微分

与线性回归比较

——你会发现逻辑斯特回归曲线和线性回归的梯度下降
求微分的式子一模一样
逻辑斯特曲线为什么不能用square Error

无论最后预测距离目标有多远,你的微分都是非常的平坦

——因此,用Square error是不容易训练得很好的
判别模型 v.s. 生成模型
P ( C 1 ∣ x ) = σ ( w ∗ x + b ) ∙ P ( C 1 ∣ x ) : 直接找 w 和 b P(C_1|x)=\sigma(w*x+b)\\ \bullet P(C_1|x):直接找w和b\\ P(C1∣x)=σ(w∗x+b)∙P(C1∣x):直接找w和b
∙ σ ( w ∗ x + b ) : 找 μ 1 , μ 2 , Σ − 1 然后 w T = ( μ 1 − μ 2 ) T Σ − 1 b = − 1 2 ( μ 1 ) T ( Σ ) − 1 μ 1 + 1 2 ( μ 2 ) T ( Σ ) − 1 μ 2 + ln N 1 N 2 \bullet\sigma(w*x+b):找\mu^1,\mu^2,\Sigma^{-1}\\ 然后w^T=(\mu^1-\mu^2)^T\Sigma^{-1}\\ b=-\frac{1}{2}(\mu^1)^T(\Sigma)^{-1}\mu^1 +\frac{1}{2}(\mu^2)^T(\Sigma)^{-1}\mu^2+\ln\frac{N_1}{N_2} ∙σ(w∗x+b):找μ1,μ2,Σ−1然后wT=(μ1−μ2)TΣ−1b=−21(μ1)T(Σ)−1μ1+21(μ2)T(Σ)−1μ2+lnN2N1
——那么这两个模型找出来的w和b会是同一组吗?
——结果不会是一样的
表示的事情是
- 同一组函数集合里Function set,在不同模型下挑选出来的函数时不一样的
- 因为,这两个模型的假设是不一样的
- 在逻辑斯特回归上,我们没有对训练集数据上的分布有任何的假设,我们就是单纯地去寻找w和b使得损失函数最小
- 但在生成模型上,我们是有对训练集的分布存在假设的,我们假设它是高斯分布,或者假设它是伯努利分布
——哪一组找出来的w和b效果更好呢?

——某一些文献表示,一般来说,判别式的模型往往比生成式的模型表现得更好一点
——在朴素贝叶斯中,会忽略维度之间的关联性,认为每个维度之间是独立
生成模型的优势
生成模型的假设本质上是对信息的脑补
这种脑部在以下几个方面,可能会使得生成模型的效果比判别模型更好
-
数据集过少
生成模型受数据集大小的影响很小,判别模型受数据集大小的影响较大
-
生成模型的鲁棒性更好,能够更好地抗噪声
因为生成模型是存在假设的,它有时候甚至会忽略掉你的噪声数据
-
可以从不同的来源估计先验和与类别相关的概率
多类别分类

—— e z 1 ∑ j = 1 3 e z 1 \frac{e^{z_1}}{\sum_{j=1}^3e^{z_1}} ∑j=13ez1ez1本质上是在Normalized(规范化)
而且有
1 > y i > 0 ∑ i y i = 1 1>y_i>0\\ \sum_iy_i=1\\ 1>yi>0i∑yi=1y i = P ( C i ∣ x ) = f w , b ( x i ) y_i=P(C_i|x)=f_{w,b}(x_i) yi=P(Ci∣x)=fw,b(xi)
——然后继续迭代修改 w 1 , w 2 , w 3 w^1,w^2,w^3 w1,w2,w3
为什么是取e
事实上你也可以取别的
或者Google maximum entropy
总流程

——如何去定义target的概率分布
如果使用class1=1,class2=2,class3=3的话,会引入类与类之间距离的问题
因此我们可以做独热编码

然后去做minimize的Cross Entropy
逻辑斯特回归的限制性
逻辑斯特曲线无法解决同或问题
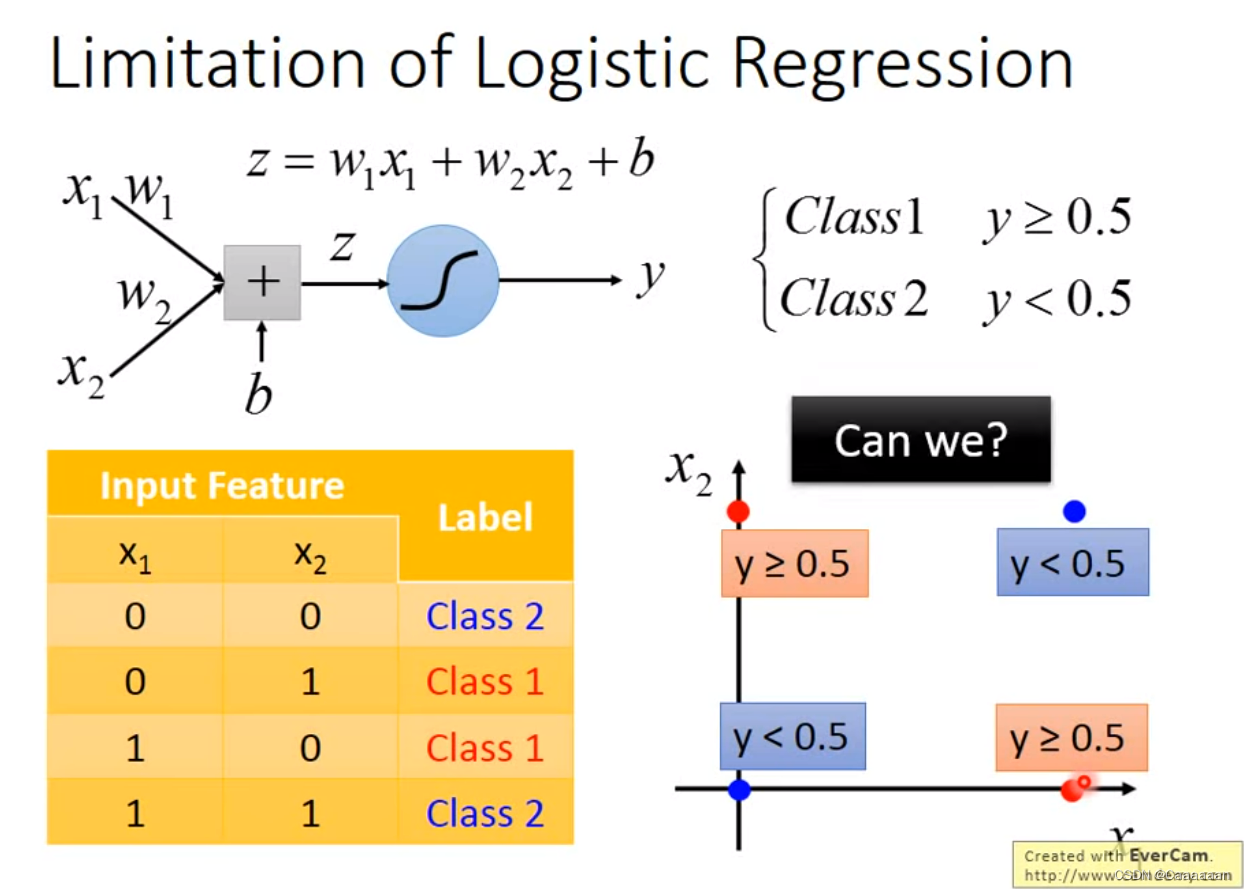
——因为逻辑斯特曲线在两个类的分类任务中,给出的分界线就是一条直线

但是同或问题,没有办法用一个直线进行分开
解决同或问题
- Feature Transformation
我们可以把特征空间映射到另一片空间上

麻烦的是,我们并不知道怎么做Feature Transformation
——怎么让机器自己去做Transformation
- Cascading logistic regression models
- 级联逻辑回归模型
把多个逻辑斯特模型拼接起来

我们讲x1和x2先经过某个逻辑斯特回归模型,得到它的维数个新替换的东西
当他们在新的Transformer下,能够将class 1和class 2分割开,最后再接一个逻辑斯特回归曲线,得到最后的bounary
每一个逻辑斯特回归的输出都可以作为下一个逻辑斯特回归模型的输入
- 我们把每一个逻辑斯特回归模型称为“Neuron”
- 把整个网络称为一个Neural Network

——敬请期待下一章
我们正式进入Deep Learning
-
相关阅读:
mysql json数据类型 相关函数
认识HTTP协议---2
Linux目录结构+文件类型
音乐播放器APP
React@16.x(25)useReducer
蓝牙资讯|苹果 AirPods Pro 2正式发布,有惊喜也有遗憾
【Docker安装部署Zookeeper+Kafka集群详细教程、部署过程中遇到问题&解决方案、测试集群是否部署成功】
TDengine 3.0 三大创新详解
前端面试题10.25
基于extended resource扩展节点资源
- 原文地址:https://blog.csdn.net/Hacker_ccc/article/details/127197580