-
电影数据读取、分析与展示(Python+Scrapy)
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1 选题背景及意义 1
1.2 国内外研究现状 1
1.2.1 爬虫技术概述 1
1.2.2 爬虫设计者面临的问题与反爬虫技术现状 3
第2章 相关理论及技术 6
2.1 robot协议对本设计的影响 6
2.2 爬虫 6
2.2.1 工作原理 6
2.2.2 工作流程 7
2.2.3 抓取策略 7
2.3 Python及Pycharm简介 8
2.4运行环境和系统结构 8
第3章 系统设计 9
3.1环境搭建 9
3.2设计思路 9
3.3 第三方类库的简介和安装 10
3.3.1 Scarpy简介及安装 10
3.3.2 Numpy简介及安装 11
3.3.3 Pandas简介及安装 12
3.3.4 JieBa简介及安装 12
3.3.5 WordCloud简介及安装 12
3.3.6 Matplotlib简介及安装 12
3.3.7 Pygal简介及安装 12
3.3.8 re简介 13
3.3.9 json简介 13
3.3.10 os简介 13
3.3.11 shutil简介 13
3.3.12 pathlib简介 13
3.3.13 random简介 14
3.3.14 math简介 14
3.3.15 PIL简介 14
3.4 Scrapy详解 14
3.4.1 架构介绍 14
3.4.2 数据流 16
第4章 影视基本数据爬取 17
4.1爬取 17
4.2数据分析 19
4.2.1评分星级 19
4.2.2性别比例 21
4.2.3位置分布 23
4.2.4时评数量 26
4.2.5主要演员 27
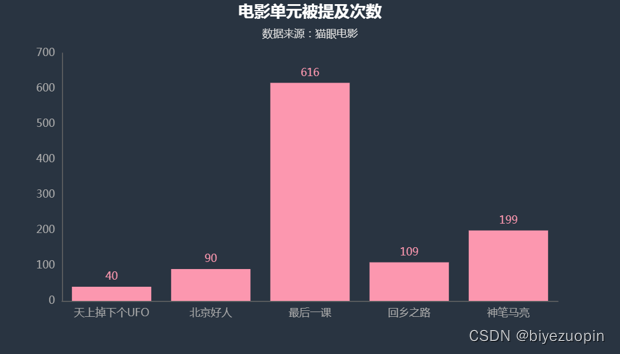
4.2.6电影单元 29
4.3词云展示 30
4.3.1整体词云 30
4.3.2热评词云 32
4.4小结 34
总 结 35
致 谢 36
参考文献 37
2.4运行环境和系统结构
运行环境:Windows操作系统下的Python3环境。
系统结构:本爬虫系统分为数据爬取模块(《我和我的家乡》以及电影详细数据)、数据分析模块(数据预处理及分析)、数据可视化模块(词云展示以及绘图展示),如图3.1所示。

图3.1系统结构
第3章 系统设计
3.1环境搭建
(1)从官网下载python3安装包,官网:
https://www.python.org/。
(2)安装python,并配置环境变量:(安装时勾选加入Path,即可自动配置好环境变量。)此电脑-属性–高级系统设置–环境变量–系统变量–path–新建–(找到自己的python位置,一般是在C盘,复制路径,粘贴进入新建,分隔号是“;”,然后一直点确认就行了。)上面是win10的操作流程,如果是win7的话,直接在点击path,下面一条上加一个;后面加c:\python3就可以了,
(3)从官网下载pycharm安装包,官网:
http://www.jetbrains.com/,安装pycharm。
(4)pycharm关联python,并配置国内镜像源:File–setting–选择Project:xxx–下拉选择Project Interpreter–然后在Proect Interpreter:栏里选择(如果没有选择的话,点show all然后添加自己python安装路径下的python.exe),接着点击右侧加号点击Manage Repositories,最后删除原有路径,添加清华镜像源(改成国内镜像源可以在安装库时避免一些错误):
https://pypi.tuna.tsinghua.edu.cn/simple。
3.2设计思路
用Python的Scrapy框架编写爬虫程序抓取了猫眼《我和我的家乡》的影片榜单信息,爬取电影的短评、评分、评价数量等数据,并结合Python的多个库(Pandas、Numpy、Matplotlib),使用Numpy系统存储和处理大型数据,中文Jieba分词工具进行爬取数据的分词文本处理,wordcloud库处理数据关键词,最终通过词云图、网页动态图展示观众情感倾向和影片评分统计等信息。流程如图3.1所示。

图3.1 流程图
该毕设使用Scrapy框架对一个网站进行系统化地爬取数据,相比较于使用requests来爬取网站,爬取效率直线提升,项目构建所需要的时间也大幅减少。对爬取下来的数据使用wordcloud进行词云展示,让读者一眼就能明白其主旨,用pygal和matplotlib绘图进行分析比较。import requests, json, time, re, datetime, pandas as pd # 获取页面内容 def get_page(url): headers = { 'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit' '/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1', 'accept': '*/*' } try: r = requests.get(url, headers=headers) r.raise_for_status() return r.text except requests.HTTPError as e: print(e) except requests.RequestException as e: print(e) except: print("出错了") # 解析接口返回数据 def parse_data(html): json_data = json.loads(html)['cmts'] comments = [] # 解析数据并存入数组 try: for item in json_data: comment = [] comment.append(item['nickName']) # 昵称 comment.append(item['cityName'] if 'cityName' in item else '') # 城市 comment.append(item['content'].strip().replace('\n', '')) # 内容 comment.append(item['score']) # 星级 comment.append(item['startTime']) comment.append(item['time']) # 日期 comment.append(item['approve']) # 赞数 comment.append(item['reply']) # 回复数 if 'gender' in item: comment.append(item['gender']) # 性别 comments.append(comment) return comments except Exception as e: print(comment) print(e) # 保存数据,写入 csv def save_data(comments): filename = 'comments.csv' dataObject = pd.DataFrame(comments) dataObject.to_csv(filename, mode='a', index=False, sep=',', header=False, encoding='utf_8_sig') # 爬虫主函数 def main(): # 当前时间 start_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') # 电影上映时间 end_time = '2020-10-01 00:00:00' while start_time > end_time: url = 'http://m.maoyan.com/mmdb/comments/movie/1328712.json?_v_=yes&offset=0&startTime=' \ + start_time.replace(' ', '%20') html = None print(url) try: html = get_page(url) except Exception as e: # 如果有异常,暂停一会再爬 time.sleep(1) html = get_page(url) time.sleep(0.5) comments = parse_data(html) start_time = comments[14][4] # 获取每页中最后一条评论时间,每页有15条评论 #print(start_time) # 最后一条评论时间减一秒,避免爬取重复数据 start_time = datetime.datetime.strptime(start_time, '%Y-%m-%d %H:%M:%S') + datetime.timedelta(seconds=-1) start_time = datetime.datetime.strftime(start_time, '%Y-%m-%d %H:%M:%S') print(start_time) save_data(comments) if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78












-
相关阅读:
(LeetCode)228. 汇总区间
无胁科技-TVD每日漏洞情报-2022-8-12
【JavaSE】面试01
JS数据类型及判断&typeof和instanceof的区别
SpringBoot如何集成MyBatis可以通过几个简单的步骤来实现
论文解读:Large Language Models as Analogical Reasoners
[附源码]JAVA毕业设计酒店管理系统(系统+LW)
详细介绍下路由器中的WAN口
【小白专用23.10.22 已验证】windows 11 安装PHP8.2 +Apache2.4
japi项目需求分析阶段
- 原文地址:https://blog.csdn.net/sheziqiong/article/details/127383860
