-
Meta Learning 元学习
来源:火炉课堂 | 元学习(meta-learning)到底是什么鬼?bilibili
文章目录
1. 元学习概述
Meta 的含义
当 meta 作为一个单词讲,表示“自身”、“本身”。当 meta 作为前缀,组成 meta-X 时,表示 “beyond-X”、“after-X” 或者 “X about X”。比如 Metadata 表示描述其他数据的数据。Meta 的中文翻译是“元”。Meta-learning(元学习)表示 “beyond learning”、“above learning” 或 “learning about learning”,目前最常见的对 meta-learning 的解释是 “learning to learn”(去学习如何学习)。
从 Machine Learning 到 Meta-Learning
传统机器学习、深度学习、元学习之间的区别:
- Machine Learning:model learning
- Deep Learning:joint feature and model learning
- Meta-Learning: joint feature, model and algorithm learning
传统的 Machine learning 使用手工设计的特征来学习模型,通过优化算法来学习模型的参数。手工特征比如用户性别、年龄等,常见机器学习模型包括决策树、SVM、KNN 等。
Deep learning 在传统 Machine learning 的基础上,不再使用手工设计的特征,而是用模型来学习特征。通过端到端的训练,可以同时学习到好的特征和模型(此时特征本身就是模型)。但深度学习的网络架构本身也是手工设计的,包括用什么算法(CNN还是RNN),网络有几层,学习率如何设置等。
深度学习手工设计的算法就是 Meta-learning 要进一步解决的问题。Meta-learning 首先要根据数据和任务去学习一个最优的算法,再用该算法在数据上得到最优的特征和模型。Meta-learning 就是将网络选择、参数选择、特征提取等一系列过程自动化,通过端到端的方式去学习。
在深度学习中,我们手工选择一个算法 F F F,通过优化参数 θ \theta θ 最终得到模型 f θ f_{\theta} fθ。传统机器学习 / 深度学习的目标是从 data 上学习一个最好的模型 f f f,而算法 F F F 本身需要进行手工选择。

Single-Task Meta-Learning(单任务元学习)
根据 Meta-learning 中 learning to learn 的思想,我们需要先去学习 F F F,然后再进行常规的深度学习。此时,学习目标就转变为了从 task 中学习一个最好的算法 F F F。元学习算法 A ( ⋅ ) A(·) A(⋅) 根据训练数据和 task,获取一个最优的算法 F ω F_{\omega} Fω, ω \omega ω 是算法中可学习的超参数(包括网络层数、学习率等), ω \omega ω 通常叫做 meta-knowledge。得到了最适合当前 task 的算法 F ω F_{\omega} Fω 后,再次基于数据训练得到一个最优的模型 f θ f_{\theta} fθ。

Multi-Task Meta-Learning(多任务元学习)
当有多组 task 时,元学习算法 A ( ⋅ ) A(·) A(⋅) 会找到一个对多种 task 都有效的算法 F ω F_{\omega} Fω。此时算法 F ω F_{\omega} Fω 具有“分类的能力”,用算法 F ω F_{\omega} Fω 去学习 new task 就会高效地获得针对 new task 的模型 f θ f_{\theta} fθ。

Single-Task Meta-Learning 和 Multi-Task Meta-Learning 处理的实际上是不同的问题。- Single-Task Meta-Learning 的目标是学到 最适合当前 task 的算法 F ω F_{\omega} Fω。
- Multi-Task Meta-Learning 的目标是学到 适合所有 task 的算法 F ω F_{\omega} Fω,并且能够处理新的 task。
另外注意 Multi-task meta-learning 和 Multi-task learning 的区别,Multi-task learning 是机器学习中的一个传统范式,其目标只是能够处理多种 task,但并不要求能够处理新的 task。
2. 元学习过程
模型 f θ f_{\theta} fθ 学习流程:
传统 Machine Learning 学习模型参数 θ \theta θ 的基本流程:
- 随机初始化模型
- 定义 loss function,根据输入 data 的预测结果和标签计算 loss
- 通过 gradient descent 对模型进行优化
Machine Learning 希望模型 f θ f_{\theta} fθ 能够在已见 data 上的效果好,以后也能在未见 data 上的表现好。而 Meta-Learning 学习算法参数 ω \omega ω 的过程不是在 data 层面进行优化,而是在 task 层面进行优化。Meta-Learning 希望算法在已见 task 上的效果好,以后也能在未见 task 上的效果好。
算法 F ω F_{\omega} Fω 学习流程:
根据训练数据(Task 1, Task 2, … Task n)和元学习算法 A ( ⋅ ) A(·) A(⋅) 可以得到一个初始化的算法 F ω F_{\omega} Fω,用算法 F ω F_{\omega} Fω 在每个 task 的 Testing samples 上去做 evaluation,评估 F ω F_{\omega} Fω 好坏。注意不能在 Training samples 上去评估 F ω F_{\omega} Fω 的好坏,因为 F ω F_{\omega} Fω 就是从 Training samples 得来的,否则相当于用训练数据去评估模型,结果肯定是好的。
通过 Testing samples,可以算出每个 task 上的 loss: l 1 l^1 l1, l 2 l^2 l2, … l n l^n ln,将所有 loss 求和就得到了最终的 Total loss。Total loss 就反应了当前 F ω F_{\omega} Fω 好不好,如果 F ω F_{\omega} Fω 不好,那么通过 F ω F_{\omega} Fω 得到的模型 f θ f_{\theta} fθ 一般来说也不会好。
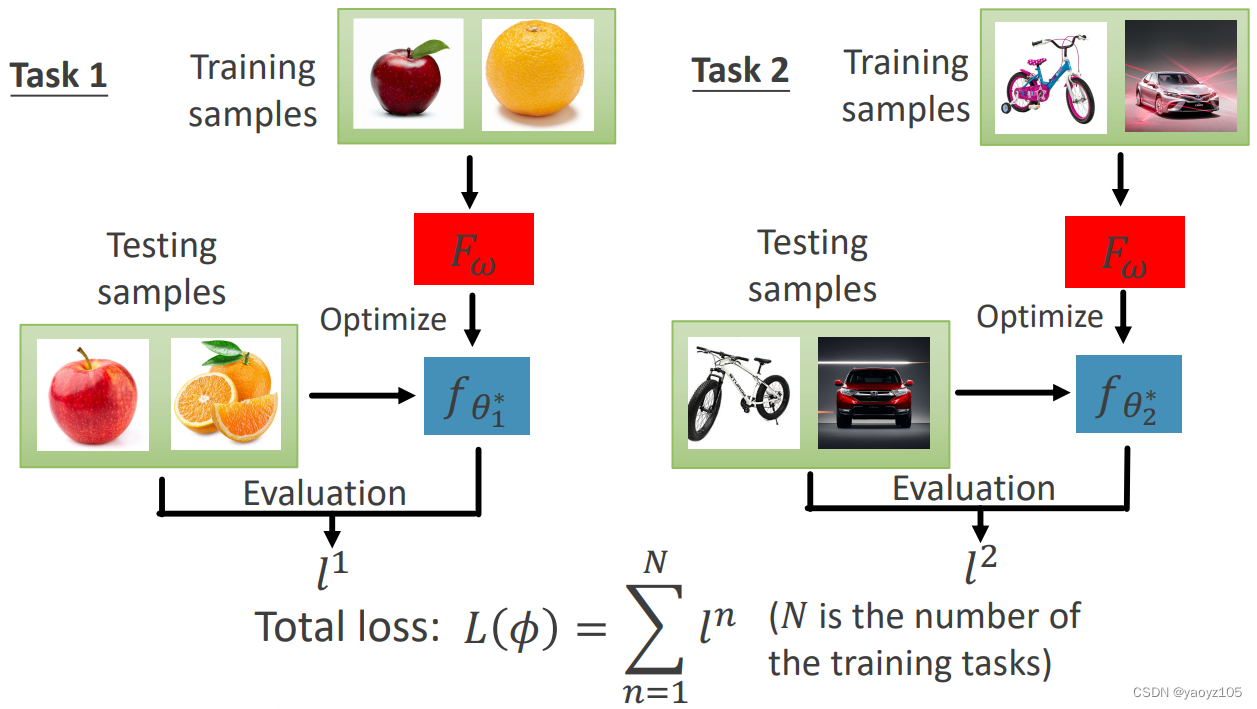
注意,Machine Learning 的 loss 是在 training examples 上去做,而 Meta-Learning 的 loss 是在 task 的 testing examples 上去做。但是,实践中的 Meta-Learning 并不是将测试数据用于训练,而是像 Machine Learning 一样将训练集划分为训练和验证两部分,其中用于训练的部分叫做 Support set(支撑集),用于验证的部分叫做 Query set(查询集)。其中 Support set 用于优化模型参数 θ \theta θ,Query set 用于优化算法参数 ω \omega ω。类似地,对于测试数据也同样分为 Support set 和 Query set,其中 Support set 的标签在测试过程中是可见的,而 Query set 的标签是未知的。

在元学习中,训练和测试通常称作元训练 Meta-training 和元测试 Meta-testing。在元训练过程中并不生成最终的模型 f f f,只是生成最优的算法 F F F。算法 F ω F_{\omega} Fω 的参数 ω \omega ω 称作元知识 meta-knowledge,元知识可以包括:初始参数,超参数,模型架构,损失函数等。Meta-training 可以表示为两层的优化过程:外层学习算法参数 ω \omega ω,内层学习模型参数 θ \theta θ。给出当前学到的 ω \omega ω 和 θ \theta θ,内层循环基于训练集的 support set 最小化损失函数 L t a s k L^{task} Ltask 可以得到更新后的 θ ∗ \theta^* θ∗。外层循环将 θ ∗ \theta^* θ∗ 拿到训练集的 query set 上去验证效果,如果效果不好说明当前的算法参数 ω \omega ω 不好,通过损失函数 L m e t a L^{meta} Lmeta 更新,得到新的算法参数 ω ∗ \omega^* ω∗。

Meta-testing 可以表示为(new task j j j):元测试时已经学到了最好的算法参数 ω ∗ \omega^* ω∗,此时将算法 F ω F_{\omega} Fω 拿到测试集的 support set 上训练,学习模型参数 θ \theta θ,最后学到针对测试集 support set 最优的模型参数 θ ∗ \theta^* θ∗。

3. 元学习方法论
3.1 Optimization-based Method
基于优化的方法将 meta-knowledge ω \omega ω 和优化过程联系在一起。
Learning to optimize
将优化器从手工选择(SGD,Adam…)变为可学习的 meta-knowledge:
S. Ravi and H. Larochelle, “Optimization as a Model for Few-Shot Learning,” in ICLR, 2017, pp. 1–11.
将学习率变为可学习的 meta-knowledge:
Z. Li, F. Zhou, F. Chen, and H. Li, “Meta-SGD : Learning to Learn Quickly for Few-Shot Learning,” in arXiv, 2017.
Learning to initialize
MAML 将模型初始参数变为可学习的 meta-knowledge:此时可学习参数 ω \omega ω = 模型参数 θ \theta θ。MAML 的基本思想是将模型参数 θ \theta θ 在 support set 中的每个 task 上训练一次,得到更新后的参数 θ i ′ \theta_i' θi′,然后将 θ i ′ \theta_i' θi′ 在 query set 上进行验证,如果效果好说明初始化参数 θ \theta θ 好。将所有 task 的 loss 累加起来,作为更新 θ \theta θ 的总损失函数。 因此,该方法是模型无关的方法,对任何模型都可以使用 MAML。
改进一阶 FOMAML:
A. Nichol, J. Achiam, and J. Schulman, “On first-order meta-learning algorithms,” arXiv, pp. 1–15, 2018.
Learning to weight
学习权重,比如对 loss function 中不同的样本赋予不同的权重,给很难的样本分较大的权重。
Focal loss 就是为难样本加权的 loss function,这里就是将如何加权变成可学习的 meta-knowledge。
J. Shu et al., “Meta-Weight-Net: Learning an Explicit Mapping For Sample Weighting,” in NIPS, 2019, pp. 1–12.
Learning to reward
学习 loss function
S. Bechtle, “Meta Learning via Learned Loss,” in arXiv.
Learning to augment
学习数据增强,将数据增强策略作为 meta-knowledge 去学习。
Y. Li, G. Hu, Y. Wang, T. Hospedales, N. M. Robertson, and Y. Yang, “DADA: Differentiable Automatic Data Augmentation,” in arXiv, 2020, pp. 1–16.
Dataset distillation
将训练数据集中的 support data 作为 meta-knowledge。
在前面的 bi-level 优化方法中,都是用同样的 support data 来优化模型参数 θ \theta θ。而数据蒸馏的基本思想是,算法的效果不好,不一定是算法的问题,也有可能是给的训练数据不好。因此,数据蒸馏方法希望得到一个最好的数据集来训练模型。
T. Wang, J.-Y. Zhu, A. Torralba, and A. A. Efros, “Dataset Distillation,” in CoRR, 2018, pp. 1–14.
Neural architecture search (NAS)
模型架构搜索是个很大的领域。
难点:前面的优化方法都是可微的, ω \omega ω 可以通过 gradient descent 进行更新。而模型架构是不可微的,很难通过 gradient descent 方法进行优化。
通常是利用强化学习、进化计算等方法做 NAS。
Zoph, Barret, and Quoc V. Le. “Neural architecture search with reinforcement learning.” arXiv preprint arXiv:1611.01578 (2016).
3.2 Model-based Method
基于模型的方法基于 meta-knowledge ω \omega ω 直接生成模型,而不是算法。
A. Santoro, M. Botvinick, T. Lillicrap, G. Deepmind, and W. G. Com, “Meta-Learning with Memory-Augmented Neural Networks,” in ICML, 2016, vol. 48.
T. Munkhdalai and H. Yu, “Meta Networks,” in ICML, 2017.
J. Requeima, J. Gordon, S. Nowozin, and R. E. Turner, “Conditional Neural Adaptive Processes,” in NIPS, 2019.
3.3 Metric-based Method
基于度量的方法不需要模型做预测,其只需要提特征,而下游任务本身不需要模型。最经典的例子就是 KNN,KNN 属于 lazy learning 方法,KNN 没有训练的过程。
Siamese networks
孪生网络,support 和 query 用同一个 embedding network
Matching networks
support 和 query 用不同的 embedding network
Prototypical networks
将 K shot 做均值,作为一个 prototype
Relation networks
用同一个 embedding network,在计算 relation score 时改变了方式
Graph networks
将 embedding 继续放到 GNN 里
4. 补充
AutoML 和 Meta-learning 的区别:
原始数据直接送到 AutoML,AutoML 会自动处理数据、选择合适的算法、模型架构、调参、优化,最后输出一个模型直接拿来做预测即可。AutoML 用于傻瓜式深度学习,其内部并不像 Meta-learning 全部都通过学习来选择,而是包含了一些手工设计的部分。因此 Meta-learning 可以看作是 AutoML 的特例,也可以作为 AutoML 的一种实现手段。总之,Meta-learning is about algorithm learning, rather than algorithm tuning。
-
相关阅读:
FinalIK反向动力学插件学习
云原生时代下的 12-factor 应用与实践
嵌入式实时操作系统的设计与开发 (线程操作学习)
记一次 .NET 某新能源材料检测系统 崩溃分析
【Android】MQTT
美团校招机试 - 小美的MT(20240309-T3)
小哥,你写的SQL执行太慢了!
【Mysql】Mysql的数据类型
极线的绘制(已知相机的内外参数,极线几何)
GBase 8s是如何保证数据一致性
- 原文地址:https://blog.csdn.net/qq_31347869/article/details/127038312