-
【ML】第六章 决策树
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】

🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
喜欢SVM、决策树是通用的机器学习算法,可以执行分类和回归任务,甚至是多输出任务。它们是强大的算法,能够拟合复杂的数据集。例如,在第 2 章中,您在加利福尼亚住房数据集上训练了一个
DecisionTreeRegressor模型,完美拟合(实际上,过度拟合)。决策树也是随机森林(参见第 7 章)的基本组成部分,是当今可用的最强大的机器学习算法之一。
在本章中,我们将首先讨论如何使用决策树进行训练、可视化和预测。然后我们将介绍 Scikit-Learn 使用的 CART 训练算法,我们将讨论如何对树进行正则化并将它们用于回归任务。最后,我们将讨论决策树的一些局限性。
训练和可视化决策树
至了解决策树,让我们构建一个并看看它是如何进行预测的。以下代码
DecisionTreeClassifier在 iris 数据集上训练 a(参见第 4 章):- from sklearn.datasets import load_iris
- from sklearn.tree import DecisionTreeClassifier
- iris = load_iris()
- X = iris.data[:, 2:] # petal length and width
- y = iris.target
- tree_clf = DecisionTreeClassifier(max_depth=2)
- tree_clf.fit(X, y)
export_graphviz()您可以通过首先使用该方法输出一个名为iris_tree.dot的图形定义文件来可视化经过训练的决策树:- from sklearn.tree import export_graphviz
- export_graphviz(
- tree_clf,
- out_file=image_path("iris_tree.dot"),
- feature_names=iris.feature_names[2:],
- class_names=iris.target_names,
- rounded=True,
- filled=True
- )
然后,您可以使用
dotGraphviz 包中的命令行工具将此.dot文件转换为各种格式,例如 PDF 或 PNG。1此命令行将.dot文件转换为.png图像文件:$ dot -Tpng iris_tree.dot -o iris_tree.png您的第一个决策树如图 6-1 所示。

图 6-1。虹膜决策树
做出预测
让我们看看图 6-1中的树是如何做出预测的。假设你找到一朵鸢尾花,你想对它进行分类。你从根节点开始(深度 0,在顶部):该节点询问花朵的花瓣长度是否小于 2.45 厘米。如果是,则向下移动到根的左子节点(深度 1,左)。在在这种情况下,它是一个叶子节点(即它没有任何子节点),所以它不会问任何问题:只需查看该节点的预测类,决策树就会预测您的花是Iris setosa (
class=setosa)。现在假设你找到了另一朵花,这次花瓣长度大于 2.45 厘米。你必须向下移动到根的右子节点(深度1,右),它不是叶子节点,所以节点又问了一个问题:花瓣宽度是否小于1.75厘米?如果是,那么你的花很可能是杂色鸢尾花(深度 2,左)。如果不是,它很可能是Iris virginica(深度 2,右)。真的就是这么简单。
笔记
决策树的众多品质之一是它们只需要很少的数据准备。事实上,它们根本不需要特征缩放或居中。
一个节点的
samples属性计算它适用于多少训练实例。例如,100 个训练实例的花瓣长度大于 2.45 厘米(深度 1,右),在这 100 个训练实例中,54 个的花瓣宽度小于 1.75 厘米(深度 2,左)。节点的value属性告诉您该节点适用于每个类的训练实例数:例如,右下角的节点适用于 0 Iris setosa、1 Iris versicolor和 45 Iris virginica。最后,节点的gini属性度量它的杂质gini=0:如果一个节点适用的所有训练实例都属于同一类,则该节点是“纯的”(例如,由于深度为 1 的左节点仅适用于Iris setosa训练实例,因此它是纯的,其gini得分为 0。公式 6-1显示了训练算法如何计算第i个节点的gini得分G i 。深度为 2 的左节点的分数等于 1 – (0/54) 2 – (49/54) 2 – (5/54) 2 ≈ 0.168。gini公式 6-1。基尼杂质

在这个等式中:
-
p i , k是第i个节点中训练实例中k类实例的比率。
图 6-2显示了此决策树的决策边界。粗竖线表示根节点的决策边界(深度 0):花瓣长度 = 2.45 cm。由于左侧区域是纯的(仅Iris setosa),因此无法进一步分割。但是,右侧区域是不纯的,因此深度为 1 的右侧节点将其拆分为花瓣宽度 = 1.75 厘米(由虚线表示)。由于
max_depth设置为 2,决策树就停在那里。如果设置max_depth为 3,则两个深度为 2 的节点将各自添加另一个决策边界(由虚线表示)。
图 6-2。决策树决策边界
估计类别概率
一个决策树还可以估计实例属于特定类k的概率。首先它遍历树找到这个实例的叶子节点,然后它返回这个节点中第k类的训练实例的比率。例如,假设你发现了一朵花瓣长 5 厘米、宽 1.5 厘米的花。对应的叶节点是深度为 2 的左节点,因此决策树应输出以下概率:Iris setosa (0/54)为 0%, Iris versicolor (49/54) 为 90.7%, Iris virginica为 9.3% (5/54)。如果你要求它预测类别,它应该输出Iris versicolor(第 1 类),因为它的概率最高。让我们检查一下:
- >>> tree_clf.predict_proba([[5, 1.5]])
- array([[0. , 0.90740741, 0.09259259]])
- >>> tree_clf.predict([[5, 1.5]])
- array([1])
完美的!请注意,估计的概率在图 6-2的右下角矩形中的其他任何地方都是相同的——例如,如果花瓣长 6 厘米,宽 1.5 厘米(尽管很明显它很可能是鸢尾花)在这种情况下是弗吉尼亚州)。
CART 训练算法
Scikit-学习使用分类和回归树(CART) 算法来训练决策树(也称为“生长”树)。该算法首先使用单个特征k和阈值t k(例如,“花瓣长度 ≤ 2.45 cm”)将训练集分成两个子集。它如何选择k和t k?它搜索产生最纯子集(按其大小加权)的对 ( k , t k )。公式 6-2给出了算法试图最小化的成本函数。
公式 6-2。分类的 CART 成本函数

一旦 CART 算法成功地将训练集一分为二,它就会使用相同的逻辑分割子集,然后递归地分割子集,依此类推。一旦达到最大深度(由
max_depth超参数定义),或者如果它找不到可以减少杂质的分割,它就会停止递归。其他一些超参数(稍后描述)控制其他停止条件(min_samples_split、min_samples_leaf、min_weight_fraction_leaf和max_leaf_nodes)。警告
作为可以看到,CART 算法是一种贪心算法:它贪婪地在顶层搜索最优分割,然后在每个后续级别重复该过程。它不检查分裂是否会导致可能的最低杂质降低几个级别。贪心算法通常会产生一个相当好的解决方案,但不能保证是最优的。
不幸的是,已知找到最优树是一个NP-Complete问题:2它需要O (exp( m )) 时间,即使对于小型训练集也难以解决。这就是为什么我们必须满足于一个“相当好的”解决方案。
计算复杂度
做出预测需要从根到叶子遍历决策树。决策树通常是近似平衡的,因此遍历决策树需要经过大约O (log 2 ( m )) 个节点。3由于每个节点只需要检查一个特征的值,因此整体预测复杂度为O (log 2 ( m )),与特征数量无关。所以预测非常快,即使在处理大型训练集时也是如此。
max_features训练算法在每个节点的所有样本上比较所有特征(如果设置了则更少)。比较每个节点上所有样本的所有特征导致训练复杂度为O ( n × m log 2 ( m ))。对于小型训练集(少于几千个实例),Scikit-Learn可以通过对数据(集合)进行预排序来加快训练速度presort=True,但这样做会大大减慢较大训练集的训练速度。基尼杂质还是熵?
经过默认情况下,使用 Gini 杂质度量,但您可以通过将超参数设置为 来选择熵杂质度量。熵的概念起源于热力学,作为分子无序的量度:当分子静止且有序时,熵接近于零。熵后来传播到各种各样的领域,包括
criterion"entropy"香农的信息论,它测量一条消息的平均信息内容:4当所有消息都相同时,熵为零。在机器学习中,熵经常被用作杂质度量:当一个集合只包含一个类的实例时,它的熵为零。公式 6-3显示了第i个节点的熵的定义。例如,图 6-1中深度为 2 的左侧节点的熵等于 –(49/54) log 2 (49/54) – (5/54) log 2 (5/54) ≈ 0.445。公式 6-3。熵

那么,你应该使用基尼杂质还是熵?事实是,大多数时候它并没有太大的区别:它们导致相似的树。Gini 杂质的计算速度稍快,因此它是一个很好的默认值。然而,当它们不同时,基尼杂质倾向于将最常见的类隔离在它自己的树分支中,而熵倾向于产生稍微更平衡的树。5
正则化超参数
决定树对训练数据的假设很少(与线性模型相反,线性模型假设数据是线性的,例如)。如果不受约束,树结构将自行适应训练数据,非常紧密地拟合它——实际上,很可能是过拟合。这样的模型通常被称为非参数模型,不是因为它没有任何参数(它通常有很多),而是因为在训练之前没有确定参数的数量,因此模型结构可以自由地紧贴数据。相比之下,参数模型,例如线性模型,具有预定数量的参数,因此其自由度受到限制,降低了过拟合的风险(但增加了欠拟合的风险)。
为避免过度拟合训练数据,您需要在训练期间限制决策树的自由度。如您所知,这称为正则化。正则化超参数取决于所使用的算法,但通常您至少可以限制决策树的最大深度。在Scikit-Learn,这是由
max_depth超参数控制的(默认值为None,表示无限制)。减少max_depth将正则化模型,从而降低过度拟合的风险。该类
DecisionTreeClassifier还有一些其他参数同样限制了决策树的形状:(min_samples_split一个节点在分裂之前必须拥有min_samples_leaf的最小样本数),(一个叶节点必须拥有的最小样本数),min_weight_fraction_leaf(与min_samples_leaf但表示为加权实例总数的一部分)、max_leaf_nodes(叶节点的最大数量)和max_features(在每个节点处被评估用于分裂的最大特征数量)。增加min_*超参数或减少max_*超参数将使模型正规化。笔记
其他算法首先不受限制地训练决策树,然后修剪(删除)不必要的节点。如果其提供的纯度改进在统计上不显着,则认为其子节点都是叶节点的节点是不必要的。使用标准统计检验,例如χ2检验( 卡方检验)估计改善纯粹是偶然结果的概率(称为原假设)。如果这个概率(称为p 值)高于给定阈值(通常为 5%,由超参数控制),则认为该节点是不必要的,并删除其子节点。修剪继续进行,直到所有不必要的节点都被修剪完。
图 6-3显示了两个在卫星数据集上训练的决策树(在第 5 章中介绍)。左侧的决策树使用默认超参数(即没有限制)进行训练,右侧使用
min_samples_leaf=4. 很明显左边的模型是过拟合的,右边的模型可能会泛化得更好。
图 6-3。正则化使用
min_samples_leaf回归
决策树还能够执行回归任务。让我们使用 Scikit-Learn 的类构建回归树
DecisionTreeRegressor,在嘈杂的二次数据集上对其进行训练max_depth=2:- from sklearn.tree import DecisionTreeRegressor
- tree_reg = DecisionTreeRegressor(max_depth=2)
- tree_reg.fit(X, y)
生成的树如图 6-4 所示。

图 6-4。回归决策树
这棵树看起来与您之前构建的分类树非常相似。主要区别在于,它不是预测每个节点中的类,而是预测一个值。例如,假设您要对x 1 = 0.6 的新实例进行预测。您从根开始遍历树,最终到达预测的叶节点
value=0.111。该预测是与该叶节点关联的 110 个训练实例的平均目标值,它导致这 110 个实例的均方误差等于 0.015。该模型的预测显示在图 6-5的左侧。如果设置
max_depth=3,您将获得右侧表示的预测。请注意,每个区域的预测值始终是该区域中实例的平均目标值。该算法以使大多数训练实例尽可能接近该预测值的方式分割每个区域。
图 6-5。两个决策树回归模型的预测
CART 算法的工作方式与之前的基本相同,只是它不再尝试以最小化杂质的方式拆分训练集,而是尝试以最小化 MSE 的方式拆分训练集。公式 6-4显示了算法试图最小化的成本函数。
公式 6-4。回归的 CART 成本函数

就像分类任务一样,决策树在处理回归任务时容易过拟合。没有任何正则化(即使用默认超参数),您将得到图 6-6左侧的预测。这些预测显然非常严重地过度拟合了训练集。只需设置
min_samples_leaf=10即可得到一个更合理的模型,如图 6-6右侧所示。
图 6-6。正则化决策树回归器
不稳定
希望到目前为止,您已经确信决策树有很多用途:它们易于理解和解释、易于使用、用途广泛且功能强大。但是,它们确实有一些限制。首先,您可能已经注意到,决策树喜欢正交决策边界(所有拆分都垂直于轴),这使他们对训练集旋转敏感。例如,图 6-7显示了一个简单的线性可分数据集:在左侧,决策树可以轻松将其拆分,而在右侧,数据集旋转 45° 后,决策边界看起来不必要地复杂化。尽管两个决策树都完美地拟合了训练集,但很可能右边的模型不能很好地泛化。限制这个问题的一种方法是使用主成分分析(参见第 8 章),这通常可以更好地定位训练数据。

图 6-7。对训练集旋转的敏感性
更一般地说,决策树的主要问题是它们对训练数据的微小变化非常敏感。例如,如果您只是从虹膜训练集(花瓣长 4.8 厘米,宽 1.8 厘米的那一个)中删除最宽的花斑鸢尾花并训练一个新的决策树,您可能会得到如图 6-8 所示的模型。如您所见,它看起来与之前的决策树非常不同(图 6-2)。实际上,由于Scikit-Learn 使用的训练算法是随机的,6即使在相同的训练数据上,你也可能得到非常
random_state不同的模型(除非你设置了超参数)。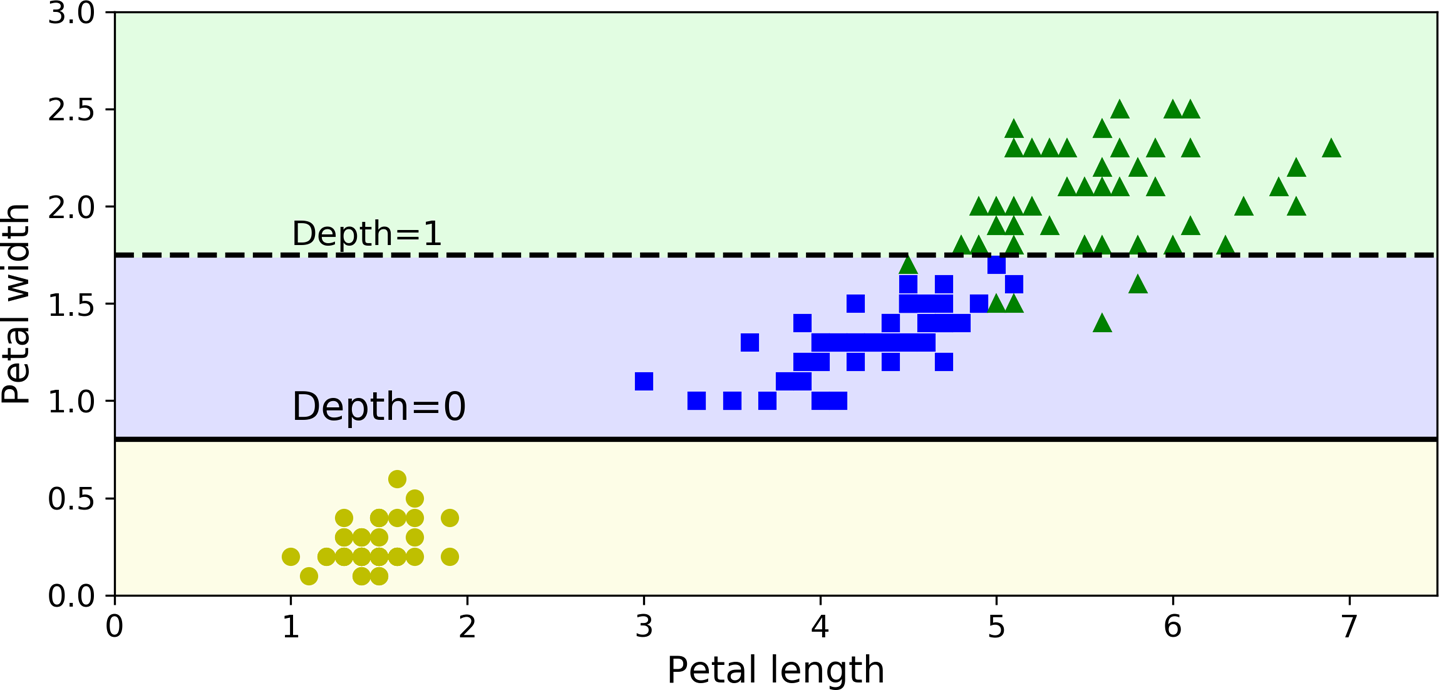
图 6-8。对训练集细节的敏感性
正如我们将在下一章中看到的那样,随机森林可以通过对许多树的平均预测来限制这种不稳定性。
练习
-
在具有一百万个实例的训练集上训练(无限制)的决策树的近似深度是多少?
-
一个节点的 Gini 杂质通常低于还是高于其父节点的?它通常是更低/更大,还是总是更低/更大?
-
如果决策树过度拟合训练集,尝试减少是一个好主意
max_depth吗? -
如果决策树对训练集的拟合不足,尝试缩放输入特征是否是个好主意?
-
如果在包含 100 万个实例的训练集上训练一个决策树需要一个小时,那么在包含 1000 万个实例的训练集上训练另一个决策树大约需要多少时间?
-
如果您的训练集包含 100,000 个实例,设置会
presort=True加快训练速度吗? -
按照以下步骤为卫星数据集训练和微调决策树:
-
用于
make_moons(n_samples=10000, noise=0.4)生成卫星数据集。 -
用于
train_test_split()将数据集拆分为训练集和测试集。 -
使用带有交叉验证的网格搜索(在
GridSearchCV类的帮助下)为 a 找到好的超参数值DecisionTreeClassifier。提示:尝试不同的值max_leaf_nodes。 -
使用这些超参数在完整的训练集上训练它,并测量你的模型在测试集上的表现。你应该得到大约 85% 到 87% 的准确率。
-
-
按照以下步骤种植森林:
-
继续上一个练习,生成 1,000 个训练集子集,每个子集包含 100 个随机选择的实例。提示:您可以为此使用 Scikit-Learn 的
ShuffleSplit课程。 -
使用上一个练习中找到的最佳超参数值在每个子集上训练一个决策树。在测试集上评估这 1000 棵决策树。由于它们是在较小的集合上进行训练的,因此这些决策树的性能可能会比第一个决策树差,仅达到 80% 左右的准确率。
-
现在魔法来了。对于每个测试集实例,生成 1000 棵决策树的预测,并只保留最频繁的预测(您可以使用 SciPy 的
mode()函数)。这个方法为您提供对测试集的多数投票预测。 -
在测试集上评估这些预测:您应该获得比第一个模型略高的准确度(大约高 0.5% 到 1.5%)。恭喜,您已经训练了一个随机森林分类器!
-
附录 A中提供了这些练习的解决方案。
1Graphviz 是一个开源图形可视化软件包,可从Graphviz获得。
2P 是可以在多项式时间内解决的问题的集合。NP 是一组问题,其解决方案可以在多项式时间内得到验证。NP-Hard 问题是任何 NP 问题都可以在多项式时间内归约到的问题。NP-Complete 问题既是 NP 又是 NP-Hard。一个主要的开放式数学问题是 P = NP 是否。如果 P ≠ NP(这似乎很可能),那么对于任何 NP 完全问题(可能在量子计算机上除外)都不会找到多项式算法。
3log 2是二进制对数。它等于 log 2 ( m ) = log( m ) / log(2)。
4熵的减少通常称为信息增益。
5有关更多详细信息,请参阅 Sebastian Raschka 的有趣分析。
6它随机选择一组特征来评估每个节点。
-
相关阅读:
Netty入门——组件(Channel)一
Failed to connect to github.com port 443:connection timed out
数据库系统助力企业降本增效的技术要点|Meetup 回顾与预告
分享一些好用的 react 组件库
OD1 敏捷背后的思路
4年北漂之路,从软件测试外包到外企的一点小心得
本地电脑搭建Plex私人影音云盘教程,内网穿透实现远程访问
统计学习方法 感知机
Flink CEP 超时事件处理:使用侧输出流和 Scala Lambda 版本编程
顺序表的C语言实现(静态/动态)
- 原文地址:https://blog.csdn.net/sikh_0529/article/details/126964140