-
PCA主成分分析算法专题【Python机器学习系列(十五)】
PCA主成分分析算法专题【Python机器学习系列(十五)】

🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ
1. PCA简介
主成分分析算法,即Proncipal Components Analysis,简称PCA,是一种经典的线性降维算法。
主成分分析希望能通过旋转坐标系,从而筛选出在新的坐标系下包含信息较少的特征,从而达到降维的效果。对于n维特征变量,PCA使用样本集合中对应子变量上取值的方差来表示该特征的重要程度,方差越大则该特征的重要程度越高,反之越低。
假设如图所示,存在A、B两个特征,这两个特征的数据点都分布在一条直线周围。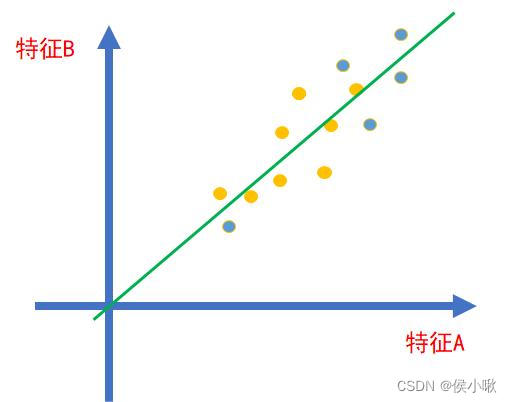
则可以将坐标系的一条轴(x轴)旋转到该直线的位置,如下图所示:

则得到了两个新特征:新特征C和新特征D。因为数据在新特征D方向上的方差很小,取值基本接近于0,所以该特征携带信息量很少,可以将该特征忽略。这样,我们放弃了特征A和特征B,但是得到了新特征C,数据的维度因此下降一,从而达到了降维的效果。(对坐标系进行旋转后的新坐标,可以通过正交变换来描述。)
所以,PCA算法的核心可以概括为:
假设n维空间中,特征数据为 x = { x 1 , x 2 , . . . , x n } x=\{x_1,x_2,...,x_n\} x={x1,x2,...,xn},即原数据有n个特征,期望在降维后保留n个特征,即去掉(n-m)个特征。
要去掉的特征的轴,即可以理解为方差最小的轴。保留的轴是方差较大的轴。
而我们要做的,就是找到需要丢弃的轴,并计算出保留的轴旋转及降维后,在新的坐标系的新坐标。最终得出维度更低的数据集。
2. python 实现 鸢尾花数据集PCA降维
读取鸢尾花数据集的代码如下:
import numpy as np from sklearn.datasets import load_iris # 加载鸢尾花数据 iris = load_iris() # 特征数据,有四个特征 data = iris.data print(data)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
数据展示如下,可以清楚地看到,原数据共有四个特征(即四列)。

将四维数据降维为二维数据
def pca(dataMat, top): # 求每个特征的均值 并去中心化处理 meanVals = np.mean(dataMat, axis=0) meanRemoved = dataMat - meanVals # 求协方差矩阵 rowvar=False表示每列表示一个特征。 covMat = np.cov(meanRemoved, rowvar=False) # 求解协方差矩阵 的 特征值、特征向量 eigVals, eigVects = np.linalg.eig(np.mat(covMat)) # 假设原来下标是[0 1 2 3],则使用np.argsort后返回的是[0 1 2 3]这组下标根据数值大小升序 排序后的结果 eigValInd = np.argsort(eigVals) # 切片取出最后 top 个特征值的下标 n_eigValInd = eigValInd[:-(top + 1):-1] # 根据下标 取出特征向量 redEigVects = eigVects[:, n_eigValInd] lowDDataMat = meanRemoved * redEigVects # 逆操作 # reconMat = (lowDDataMat * redEigVects.T) + meanVals return lowDDataMat after_pca_data = pca(data, 2) print(after_pca_data)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
降维后的数据结果如下图所示:

3. sklearn库实现 鸢尾花数据集PCA降维案例
使用sklearn库实现鸢尾花数据集PCA降维,代码如下:
from sklearn.datasets import load_iris from sklearn.preprocessing import StandardScaler from sklearn.decomposition import PCA import numpy as np # 加载鸢尾花数据 iris = load_iris() # 特征数据,有四个特征 data = iris.data # 标签数据 target = iris.target # 去中心化 meanVals = np.mean(data, axis=0) data_transformed = data - meanVals # 将四维数据降维到2维 pca = PCA(n_components=2) # 降维后的数据 after_pca_data = pca.fit_transform(data_transformed) print(after_pca_data)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
其中,参数n_components=2表示的也是降低后 结果数据的维度,而不是需要降低的维度。
数据处理结果如下,成功将数据降维为二维:

两种方法处理的结果不能说一模一样,但是基本上还是差不多的。(只在第二列数据的符号上存在一些差异,这与sklearn提供接口的底层逻辑有关。)
关于PCA接口的参数,
n_components
①可以是一个大于等于1的整数,表示保留的特征的个数,
②也可以是一个(0,1]之间的浮点数,表示方差贡献率达到的标准,选择达到标准的主成分,而结果的维度数也随之确定。
③还可以设置为’mle’(极大似然估计), 此时PCA类会用MLE算法根据特征的方差分布情况自己去选择一定数量的主成分特征来降维。
whiten: 白化。
即,对降维后的数据的每个特征进行标准化,使方差都为1。默认值是False,即不进行白化。
对于PCA降维本身而言,一般不需要白化。如果PCA降维后有后续的数据处理动作,可以考虑白化。
此外,此处代码中,在使用pca之前对数据进行了去中心化,但也不限于此,实际应用时灵活多变,也可以选择其他数据处理方式,如标准化,归一化。
本次分享就到这里,小啾感谢您的关注与支持!
🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ本专栏更多好文欢迎点击下方连接:
1.初识机器学习前导内容_你需要知道的基本概念罗列_以PY为工具 【Python机器学习系列(一)】
2.sklearn库数据标准预处理合集_【Python机器学习系列(二)】
3.K_近邻算法_分类Ionosphere电离层数据【python机器学习系列(三)】
4.python机器学习 一元线性回归 梯度下降法的实现 【Python机器学习系列(四)】
5.sklearn实现一元线性回归 【Python机器学习系列(五)】
6.多元线性回归_梯度下降法实现【Python机器学习系列(六)】
7.sklearn实现多元线性回归 【Python机器学习系列(七)】
8.sklearn实现多项式线性回归_一元/多元 【Python机器学习系列(八)】
9.逻辑回归原理梳理_以python为工具 【Python机器学习系列(九)】
10.sklearn实现逻辑回归_以python为工具【Python机器学习系列(十)】
11.决策树专题_以python为工具【Python机器学习系列(十一)】
12.文本特征提取专题_以python为工具【Python机器学习系列(十二)】
13.朴素贝叶斯分类器_以python为工具【Python机器学习系列(十三)】
14.SVM 支持向量机算法(Support Vector Machine )【Python机器学习系列(十四)】 -
相关阅读:
第一章《初学者问题大集合》第6节:IntelliJ IDEA的下载与安装
dbImageSDK 高速数字图像处理
C++ Reference: Standard C++ Library reference: C Library: cfenv: FE_INVALID
Web(3)网络扫描与window,Linux命令
浪涌防护器件要选对,布局布线更重要!|深圳比创达电子EMC(上)
【项目部署】使用Jenkins一键打包部署SpringBoot应用
Word文档怎么翻译成中文?学会这几种方法你也能翻译文档
qml 无法修改listview表头控件文本
C、指针基础2
【神印王座】伊莱克斯现身,龙皓晨获得一传承,圣采儿却惨遭反噬
- 原文地址:https://blog.csdn.net/weixin_48964486/article/details/126372610