-
论文阅读_自然语言模型加知识图谱_DKPLM
英文题目:DKPLM: Decomposable Knowledge-enhanced Pre-trained Language Model for Natural Language Understanding
中文题目:DKPLM:可分解的利用知识增强的预训练语言模型
论文地址:https://arxiv.org/abs/2112.01047
领域:自然语言处理, 知识图谱
发表时间:2021.12
作者:Taolin Zhang等,华东师范大学,阿里团队
出处:AAAI-2022
代码和数据:https://github.com/alibaba/EasyNLP(集成于EasyNLP)
阅读时间:2022.09.11读后感
自然语言和知识图结合的一种新尝试,几种优化方法比较有意思。尤其是他对长尾信息的分析,很有启发性:即使在无监督学习的情况下,也要尽量使用重要的数据训练模型。另外,还给出了具体方法,比如实体出现频率高于均值,则忽略它…
介绍
加入知识增强的自然语言模型简称KEPLM,它将知识图中的三元组注入NLP模型,以提升模型对语言的理解能力。在模型使用时需要知识搜索和编码,运算量大。
本文提出可分解的知识增强名为DKPLM,具体方法是使用长尾实体作为知识注入的目标,还在训练时设计了重建知识三元组的知识解码任务。它只在预测训练时注入了知识,在精调模型和预测时用法与BERT一致,相对节省资源。如图-1所示:

在预训练时使用以下主要技术:
- 基于知识的长尾实体探测
- 利用知识图中三元组做成伪实体替换长尾实体训练模型,模型无需增加参数。
- 利用三元组中的关系,通过对实体及其谓词来解码对应实体中的每个token。
实验证明对于zero_shot任务,以及预测速度都有明显提升。
方法
整体架构如图-2所示:

长尾实体检测
通过对wiki数据分析可以看到实体出现的频率服从幂律分布,如图-3所示:
只有很少的实体高频出现,多数实体出现次数少,这使用自然语言模型难以从上下文中有效学习。之前论文提到注入高频三元组不总是有利于对下游任务,反而更容易注入负面知识。因此更好的方法是注入长尾实体,同时还需要考虑实体在知识图中和句中的重要性。具体考虑以下三点(图-2第二层右侧):
- 实体频率:实体在预训练数据集中出现的频率,记作:Freq(e)。
- 语义重要性:实体在句中的重要性,记作:SI(e)。计算SI可以使用语义相似度,通过去掉句中的实体e后的编码hrep与原句编码ho比较,识别该实体的重要性。

- 知识连接:实体在知识图中多跳邻居的个数,记作:KC(e)。如下式所示,其中Rmax,Rmin是预定义的阈值,|N|表示邻居个数,Hop指跳数。

最终基于知识的长尾系数KLT计算如下:

其I{x}为布尔性的指示函数,当实体出现频率高于均值时,则忽略该实体。
(我理解是:在训练集中出现次数太多的去掉,在知识图中邻居太多的去掉,在句子里有它没它都一样的去掉)伪Token嵌入的注入
为了提升模型对长尾实体的理解,将知识图中的关系代入模型训练。如果预测训练数据中出现了头实体eh,则用它相关的关系谓词和尾实体替换它的嵌入:
同理,如果出现尾实体,则用谓词加头实体来表示。
以替换头实体为例,对关系和尾实体编码:
其中F(e)是预训练模型PLM的输出,fsp是自注意力池化,LN是标准化层,W是模型参数。
由于尾实体和关系谓词通常都比较短,生成的表示可能是无效的,因此还加入了对头实体的描述文本记作e_h^des,使用预训练模型对其编码,最终的伪实体表示如下: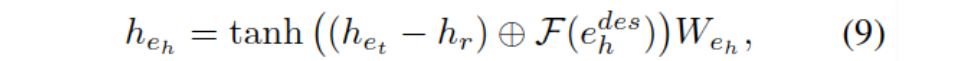
这里的⊕表示串联。通过上述方法,促进模型学习知识图中的三元组。
相关知识解码
为了更确定地让模型学习注入信息,又调整了解码层逻辑。在最后一层,利用自注意力池化获取跨实体的实体掩码表示。

用头实体本身通过上述方式生成表示h_eho,再加入hr,目标是解码尾实体,用h_di表示预测尾实体的第i个token。

上式中δ是缩放因子,h_d^0等于h_eh_o作为初始的启发。
由于词表较大,使用采样的SoftMax来对比预测值与实际值。损差函数计算方法如下:

这里yi是实际token,yn是采样的负token,Q是负采样函数,N为负例个数。
训练目标包含两项任务:相关的知识解码和BERT自带掩码模型任务,最终损失函数计算如下:

实验
模型底层框架基于RoBERTa,使用英文Wikipedia作训练数据,知识图包含3085345个实体,822种关系。由于实体太多,使用PEPR算法选择负实体,并将N设为20,λ1最终取值为0.5。主实验结果如下:

从表-4可以看到,DKPLM速度明显优于其它知识注入模型:

从图-5的消融实验可以看到,三种优化方法各自的贡献:

-
相关阅读:
Vue3---uni-app--高德地图引用BUG
FFmpeg入门详解之6:VLC播放器简介
领先特斯拉,中国电车制造商“登陆”东南亚,电气化潮流一触即发
HTTPS、SSL/TLS,HTTPS运行过程,RSA加密算法,AES加密算法
数据标注行业中的“睁一只眼闭一只眼”
基于STM32单片机设计的红外测温仪(带人脸检测)
2023年CCF非专业级别软件能力认证第二轮 (CSP-S)提高级C++语言试题
总结一下使用paramiko遇到的问题
大白话说Python+Flask入门(六)Flask SQLAlchemy操作mysql数据库
【gpt实践】实用咒语分享
- 原文地址:https://blog.csdn.net/xieyan0811/article/details/126806288