-
机器学习实训(4)——支持向量机(补充)
目录
1 一些问题
- 支持向量机的基本思想是什么?
拟合类别之间可能的、最宽的“街道”。简而言之,它的目的是使决策边界之间的间隔最大化,从而分隔出两个类别的训练实例。
- 什么是支持向量?
位于“街道”之上的实例被称为支持向量,也包括处于边界上的实例。
- 使用SVM时,对输入值缩放为什么重要?
如果训练集不经缩放,SVM将趋于忽略值较小的特征。
- 如果训练集有上千万个实例和几百个特征,我们应该使用SVM原始问题还是对偶问题来训练模型?
这个问题仅适用于线性支持向量机,因为核SVM只能使用对偶问题。
- 假设我们用RBF核训练了一个SVM分类器,不过好像对训练集拟合不足,我们应该提升还是降低
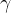 (gamma)? 那么C ?
(gamma)? 那么C ?
这可能是由于过度正则化导致的,因此我们可以提升 gamma 或 C 来降低正则化。
2 训练LinearSVC
在一个线性可分离数据集上训练LinearSVC,然后在同一数据集上训练 SVC 和 SGDClassifier 。看看是否可以用它们产生出大致相同的模型。
这里我们使用鸢尾花数据集,因为Iris Setosa和Iris Versicolor类是线性可分离的。
下面是代码实现:
- import numpy as np
- from sklearn import datasets
- from sklearn.svm import SVC, LinearSVC
- from sklearn.linear_model import SGDClassifier
- from sklearn.preprocessing import StandardScaler
- #加载数据
- iris = datasets.load_iris()
- X = iris["data"][:, (2, 3)] # 花瓣长度和宽度
- y = iris["target"]
- setosa_or_versicolor = (y == 0) | (y == 1)
- X = X[setosa_or_versicolor]
- y = y[setosa_or_versicolor]
- #训练
- C = 5
- alpha = 1 / (C * len(X))
- lin_clf = LinearSVC(loss="hinge", C=C, random_state=42)
- svm_clf = SVC(k
-
相关阅读:
Comparator和Comparable
编程的终结;展望2023年AI系统方向;AI的下一个阶段
git操作
树莓派搭建K8S集群
Elasticsearch 入门 索引、分词器
直流电源供电 LED升压 恒流驱动IC 方案AP9193
锐捷Smartweb管理系统 默认开启Guest账户漏洞
计算机毕业设计(附源码)python疫情综合管控系统平台
17.Oauth2-微服务认证
【数据分享】2006-2021年我国城市级别的市容环境卫生相关指标(20多项指标)
- 原文地址:https://blog.csdn.net/WHJ226/article/details/126734346
