-
Java集合源码剖析——基于JDK1.8中ConcurrentHashMap的实现原理
文章目录:
1.2 Collections.synchronizedMap
1.解决HashMap线程不安全的几种方法
1.1 Hashtable
第一种方法就是使用Hashtable,这是个线程安全的集合类,而它在针对 put、get等一系列操作时,都是对整个方法进行上锁。
- public synchronized V put(K key, V value) {
- // Make sure the value is not null
- if (value == null) {
- throw new NullPointerException();
- }
- // Makes sure the key is not already in the hashtable.
- Entry tab[] = table;
- int hash = key.hashCode();
- int index = (hash & 0x7FFFFFFF) % tab.length;
- @SuppressWarnings("unchecked")
- Entry
- for(; entry != null ; entry = entry.next) {
- if ((entry.hash == hash) && entry.key.equals(key)) {
- V old = entry.value;
- entry.value = value;
- return old;
- }
- }
- addEntry(hash, key, value, index);
- return null;
- }
- public synchronized V get(Object key) {
- Entry tab[] = table;
- int hash = key.hashCode();
- int index = (hash & 0x7FFFFFFF) % tab.length;
- for (Entry e = tab[index] ; e != null ; e = e.next) {
- if ((e.hash == hash) && e.key.equals(key)) {
- return (V)e.value;
- }
- }
- return null;
- }
可以看到,不管是往 map 里边添加元素还是获取元素,都会用 synchronized 关键字加锁。那么如果有多个线程同时操作这个map集合,肯定会存在资源竞争,同时也只能有一个线程可以获取到锁,操作资源。所以,Hashtable 的缺点显而易见,它不管是 get 还是 put 操作,都是锁住了整个 哈希表,效率十分低下,因此并不适合高并发场景。
1.2 Collections.synchronizedMap
这个集合工具类中提供了一系列 synchronizedXXX 的静态方法,用于将那些线程不安全的集合转为线程安全的,不过不太推荐使用,原因来看看:↓↓↓
- public static
- return new SynchronizedMap<>(m);
- }
- /**
- * @serial include
- */
- private static class SynchronizedMap
- implements Map
- private static final long serialVersionUID = 1978198479659022715L;
- private final Map
- final Object mutex; // Object on which to synchronize
- SynchronizedMap(Map
- this.m = Objects.requireNonNull(m);
- mutex = this;
- }
- SynchronizedMap(Map
- this.m = m;
- this.mutex = mutex;
- }
- public int size() {
- synchronized (mutex) {return m.size();}
- }
- public boolean isEmpty() {
- synchronized (mutex) {return m.isEmpty();}
- }
- public boolean containsKey(Object key) {
- synchronized (mutex) {return m.containsKey(key);}
- }
- public boolean containsValue(Object value) {
- synchronized (mutex) {return m.containsValue(value);}
- }
- public V get(Object key) {
- synchronized (mutex) {return m.get(key);}
- }
- public V put(K key, V value) {
- synchronized (mutex) {return m.put(key, value);}
- }
- public V remove(Object key) {
- synchronized (mutex) {return m.remove(key);}
- }
- public void putAll(Map map) {
- synchronized (mutex) {m.putAll(map);}
- }
- public void clear() {
- synchronized (mutex) {m.clear();}
- }
在调用 Collections.synchronizedMap 之后,它实际上是为我们 new 了一个 SynchronizedMap 类,追进这个类的源码(截取了部分代码),发现它和Hashtable差不多,也是锁住了整个哈希表,那就不用多说了,在高并发场景下效率肯定是个大问题。
1.3 ConcurrentHashMap(JDK1.7)
主角登场啦,针对上面两种解决方法的局限性,它们都是把整个哈希表锁住再进行后续的操作。那么为了进一步提升效率,我们能不能把整张哈希表分成 N 个部分,并使元素尽量均匀的分布到每个部分中,分别给每个部分加锁,使它们互相之间并不影响,这种方式岂不是更好 。这就是在 JDK1.7 中 ConcurrentHashMap 采用的方案,被叫做锁分段技术,每个部分就是一个 Segment(段)。
在 JDK1.7中,本质上还是采用链表+数组的形式存储键值对的。但是,为了提高并发,把原来的整个 table 划分为 n 个 Segment 。所以,从整体来看,它是一个由 Segment 组成的数组。然后,每个 Segment 里边是由 HashEntry 组成的数组,每个 HashEntry之间又可以形成链表。我们可以把每个 Segment 看成是一个小的 HashMap,其内部结构和 HashMap 是一模一样的。
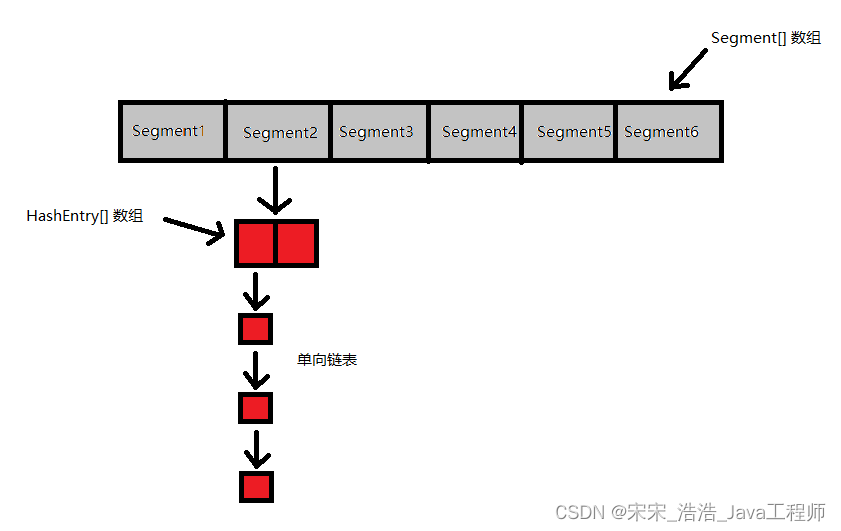
当对某个 Segment 加锁时,如图中 Segment2,并不会影响到其他 Segment 的读写。每个 Segment 内部自己操作自己的数据。这样一来,我们要做的就是尽可能的让元素均匀的分布在不同的 Segment中。最理想的状态是,所有执行的线程操作的元素都是不同的 Segment,这样就可以降低锁的竞争。
2.JDK1.8中的ConcurrentHashMap
上面针对1.7的ConcurrentHashMap就简单的说这么多了,我主要是考虑目前基本用的都是JDK1.8,所以这里主要来说一下JDK1.8中ConcurrentHashMap的实现原理。
JDK 1.8 的 CHM(ConcurrentHashMap) 实现,完全重构了 1.7 。不再有 Segment 的概念,只是为了兼容 1.7 才申明了一下,并没有用到。因此,不再使用分段锁,而是给数组中的每一个头节点(为了方便,以后都叫桶)都加锁,锁的粒度降低了。采用的是 Synchronized + CAS ,把锁的粒度进一步降低,而放弃了 Segment 分段。


2.1 put方法
注释写的很详细了,唉,花了好长时间才理解。。。还是自己太菜了
-
根据 key 计算出 hashcode 对应的桶下标。
-
判断是否需要进行初始化。(只会有一个线程初始化哈希表成功,其他失败的线程会自旋)
-
根据hash算法找到当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
-
如果当前位置的
hashcode == MOVED == -1,则需要进行扩容。 -
如果都不满足,则利用 synchronized 锁写入数据。
-
如果数量大于
TREEIFY_THRESHOLD则要执行树化方法,在treeifyBin中会首先判断当前数组长度≥64时才会将链表转换为红黑树。
- public V put(K key, V value) {
- return putVal(key, value, false);
- }
- final V putVal(K key, V value, boolean onlyIfAbsent) {
- //可以看到,在并发情况下,key 和 value 都不能为null。有一个为null直接空指针
- if (key == null || value == null) throw new NullPointerException();
- //这里就是计算key的hash值(具体的好像还挺复杂,我这里没有深入研究)
- int hash = spread(key.hashCode());
- //用来计算当前链表上kv键值对的个数
- int binCount = 0;
- for (Node
- Node
- //如果哈希表为空,说明还未进行初始化
- if (tab == null || (n = tab.length) == 0)
- //initTable()方法用来初始化哈希表,后面我来说这个方法
- tab = initTable();
- //根据key的hash值通过哈希算法计算得到对应的桶下标,并且判断是否为空
- else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
- //走进来则说明当前桶为空,进而通过CAS原子操作将新节点插入到此位置,保证了只有一个线程可以CAS成功
- //判断哈希表下标为i的节点是否为null,如果为null,则更新为new Node
- if (casTabAt(tab, i, null,
- new Node
- break; // no lock when adding to empty bin
- }
- //如果计算得到对应的桶下标不为空,则判断该节点的hash值是否为MOVED(值为-1)
- else if ((fh = f.hash) == MOVED)
- //如果节点的hash值为-1,则说明当前桶下的数组正在扩容,需要当前线程帮忙迁移数据
- tab = helpTransfer(tab, f);
- //排除上面三种情况,则会走到这里
- else {
- //临时变量,用来保存key对应的旧值
- V oldVal = null;
- //加上同步锁,保证线程安全,这里是对当前桶中的第一个节点对象加锁
- synchronized (f) {
- //这里先再次检查一下,确保当前桶的第一个节点没有变化
- //tabAt(tab, i)方法表明获取tab这个哈希表中下标为i的第一个节点对象
- if (tabAt(tab, i) == f) {
- //如果key的hash值大于等于0,则说明是链表结构
- if (fh >= 0) {
- binCount = 1;
- //从头节点开始遍历,每遍历一次binCount计数加1
- for (Node
- K ek;
- //找到了和当前key相同的节点(hash值相同 && equals为true)
- if (e.hash == hash &&
- ((ek = e.key) == key ||
- (ek != null && key.equals(ek)))) {
- //先将key对应的旧值保存到变量oldVal中
- oldVal = e.val;
- if (!onlyIfAbsent)
- //用新的value值替换key对应的旧值
- e.val = value;
- break; //已经找到,可以退出循环
- }
- Node
- //如果遍历到了链表的尾节点,还没有找到与要插入的key相同的节点
- if ((e = e.next) == null) {
- //则将要插入的节点放在链表的最后(尾插)
- pred.next = new Node
- value, null);
- break; //退出循环
- }
- }
- }
- //不是链表了话,那就是树节点了。这里提一下,TreeBin只是头结点对TreeNode的再封装
- else if (f instanceof TreeBin) {
- Node
- binCount = 2;
- //这里进行红黑树的相关操作
- if ((p = ((TreeBin
- value)) != null) {
- oldVal = p.val;
- if (!onlyIfAbsent)
- p.val = value;
- }
- }
- }
- }
- //注意下,这个判断是在同步锁的外部,因为treeifyBin方法内部也有同步锁,所以并不影响
- if (binCount != 0) {
- if (binCount >= TREEIFY_THRESHOLD)
- treeifyBin(tab, i);
- if (oldVal != null)
- return oldVal;
- break;
- }
- }
- }
- //put完成之后,哈希表的元素要加1,并且可能触发扩容,这个比较复杂,我没有深入研究
- addCount(1L, binCount);
- return null;
- }
2.2 initTable方法
从源码中可以发现
ConcurrentHashMap的初始化是通过自旋和 CAS 操作完成的。里面需要注意的是变量sizeCtl,它的值决定着当前的初始化状态- //此时哈希表为空,要进行初始化操作
- private final Node
- Node
- //循环判断哈希表是否为空,直到初始化成功为止
- while ((tab = table) == null || tab.length == 0) {
- //sizeCtl这个值有很多情况,默认值为0,
- //当为 -1 时,说明有其它线程正在对哈希表进行初始化操作
- //当哈希表初始化成功后,又会把它设置为扩容阈值
- //当为一个小于 -1 的负数,用来表示当前有几个线程正在帮助扩容
- if ((sc = sizeCtl) < 0)
- //若sc小于0,其实在这里就是-1,因为此时哈希表是空的,不会发生扩容,sc只能为正数或者-1
- //因此,当前线程放弃CPU时间片,只是自旋
- Thread.yield(); // lost initialization race; just spin
- //通过CAS把 sc 的值设置为-1,表明当前线程正在进行哈希表的初始化
- //当其中一个线程将sc更新为-1之后,其它失败的线程就会自旋
- else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
- try {
- //重新检查一下哈希表是否为空
- if ((tab = table) == null || tab.length == 0) {
- //如果sc大于0,则为sc,否则返回默认容量16
- //当调用有参构造创建 Map 时,sc的值是大于0的
- int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
- @SuppressWarnings("unchecked")
- //创建哈希表,长度大小为n
- Node
- table = tab = nt;
- //n - 1/4 n,也就是0.75n,表示扩容阈值
- sc = n - (n >>> 2);
- }
- } finally {
- //最后将sizeCtl更新为扩容阈值
- sizeCtl = sc;
- }
- //如果当前线程初始化哈希表成功,则跳出循环
- //其他自旋的线程因为判断哈希表不为空,也会停止自旋
- break;
- }
- }
- return tab;
- }
2.3 get方法
- 根据 hash 值计算位置。
- 查找到指定位置,如果头节点就是要找的,直接返回它的 value.
- 如果头节点 hash 值小于 0 ,说明正在扩容或者是红黑树,find查找。
- 如果是链表,遍历查找。
- public V get(Object key) {
- Node
- //这里就是计算key的hash值
- int h = spread(key.hashCode());
- //如果哈希表不为空,并且根据key的hash值计算得到的桶下标对应的节点也不为空
- if ((tab = table) != null && (n = tab.length) > 0 &&
- (e = tabAt(tab, (n - 1) & h)) != null) {
- //如果当前桶的头节点直接命中,匹配成功
- if ((eh = e.hash) == h) {
- if ((ek = e.key) == key || (ek != null && key.equals(ek)))
- //直接返回key对应的value
- return e.val;
- }
- //头节点的hash值小于0,说明正在扩容或者是红黑树,find查找
- else if (eh < 0)
- return (p = e.find(h, key)) != null ? p.val : null;
- //否则说明是正常的链表,遍历查找即可
- while ((e = e.next) != null) {
- if (e.hash == h &&
- ((ek = e.key) == key || (ek != null && key.equals(ek))))
- return e.val;
- }
- }
- return null;
- }
3.总结
以上分享借鉴了很多大佬的文章博客,最后加上自己的理解。
Java7 中
ConcurrentHashMap使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个Segment都是一个类似HashMap数组的结构,它可以扩容,它的冲突会转化为链表。但是Segment的个数一但初始化就不能改变。Java8 中的
ConcurrentHashMap使用的Synchronized锁加 CAS 的机制。底层的数据结构也由 Java7 中的Segment数组 +HashEntry数组 + 链表 进化成了 Node 数组 + 链表 / 红黑树,Node 是类似于一个 HashEntry 的结构。当某个桶下挂载的节点数超过一定大小时会转化成红黑树,节点数小于一定数量时又会恢复成链表。 -
相关阅读:
java计算机毕业设计移动端校园请假系统设计与实现服务器端MyBatis+系统+LW文档+源码+调试部署
中国网络安全审查认证和市场监管大数据中心数据合规官CCRC-DCO
AI绘画使用Stable Diffusion(SDXL)绘制中国古代神兽
java毕业生设计在线教学质量评价系统计算机源码+系统+mysql+调试部署+lw
量子计算实现:量子算法的实现
Unity3D C# 反射与特性的配合使用
PHPOffice/PhpSpreadsheet的导入导出操作基本使用
迈向数字化发展新阶段,某商业银行数据存储创新方案及实践经验
常见的数码管中的引脚分布情况
react输入框输入的空格 样式 和输入后页面显示一致
- 原文地址:https://blog.csdn.net/weixin_43823808/article/details/126732474
