-
Re29:读论文 D2GCLF: Document-to-Graph Classifier for Legal Document Classification
论文标题:D2GCLF: Document-to-Graph Classifier for Legal Document Classification
NAACL官方下载地址:https://aclanthology.org/2022.findings-naacl.170/
(这个PDF文档参考文献有缺失内容,我已经发邮件问过作者了,所以如果也有此需要的话可以直接问我要)本文是2022年NAACL论文,关注法律领域的文书分类任务。是将每篇文书都构建为了4个图,然后将4个关系图合并,用GAT实现图分类任务。
本文的分类标签是民事案件的纠纷类型(从400类中选出语义上最相近的20类):

本文提出模型Document-to-Graph Classifier (D2GCLF),从案例中抽取主要当事人之间的关系作为事件,用4张relation graph来代表一篇法律文书。
1. Background
和传统分类任务不同,不同类的法律文书也可能在语义上高度相似:
DOCSCRH(商业住房产权纠纷)类型(只有房地产公司能出售商业住房):

DOCSPHP(房屋买卖合同纠纷)类型:

本文认为,有两点原因造成传统文本分类方法不适用于法律领域:
- 传统文本分类没有充分利用文本结构信息。一些过去的方法用句子关系来解决这一问题,但并非所有句子都于预测任务有利。
- 法律案例中事实与理由部分最重要,但现在的词贡献图难以表征关键事实,且含大量与预测任务无关的词语。
本文认为法律文书分类任务最重要在理解事实,本文表示为实体之间的关系。
2. D2GCLF
从法律抽取中抽取关键当事人(原告和被告)的事实构成4个图:
- Entity-Matter
- Entity-Action
- Entity-Keyword(主题)
- Semantic Role Labeling (SRL):建模更广泛的关系,包括有第三方人事的
然后组合4张图,过GNN(GAT),得到图表征,作为文书表征,实现分类。
整体架构图:

2.1 Motivation和民事诉讼文书数据分析
民事诉讼文书组成部分:
- Entity information sections:诉讼当事人的信息
- Facts
- Reason:原告诉讼理由
(当事人关系常存于facts和reason部分) - Miscellaneous items:相关法律、程序、证据的讨论,与文书类型关系不大,因为同一法律可能应用于不同纠纷中
组成部分示意图:

不同类型借贷纠纷的示例(DOCPL是私人贷款合同纠纷,例子1讨论借贷行为,例子2、3提到借贷诉讼的目的和原因;DOCS是保人合同纠纷):

如果模型不知道句子之间的关系,可能会忽略关键词guarantor。2.2 建图
2.2.1 Entity-Matter Graph
matters:识别纠纷类别的重要证据
常是名词,和原被告出现在同一句,所以本文用POS解析器1抽取每一包含原被告的句子里的名词。为了理解matters上发生的动作,我们也抽取了形容被抽取名词的动词,如table2中的borrowed和dollar。文书节点,原告节点A,被告节点B:

2.2.2 Entity-Action Graph
案例中,纠纷必然对应某些原被告之间的动作。
本文抽取出现原被告句子中的动词,和每个动作的对象。
2.2.3 Entity-Keyword Graph
生成原被告相关的主题。
本文用TextRank抽取含有所有当事人句子中的关键词。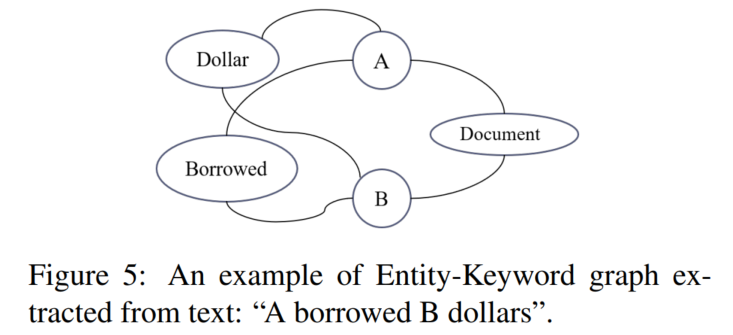
2.2.4 SRL Graph
(subject, predicate, object)
predicate谓语
用LTP工具2从每一句中抽取。
2.2.5 Combined graph

2.3 GNN
本文用预训练的词嵌入作为初始节点表征,用GAT聚合得到document节点表征,然后后面的就是常规MLP分类模型了。
3. 实验
3.1 数据集
本文算是给出了一部分的数据集?就给了这些:https://drive.google.com/file/d/1bZVv0TPSjIRsRjO0P67v8Y-K-tb-o7IE/view

4000个案例(每类最新200个案例),20类。70%训练集,30%测试集。替换指示代词为原被告真名。
3.2 baseline
词嵌入用的是https://github.com/Embedding/Chinese-Word-Vectors
传统机器学习方法词嵌入用的是https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
深度学习方法词嵌入用的是https://huggingface.co/hfl/chinese-roberta-wwm-extlarge
(为什么词嵌入都不统一呢这个小编也不知道!)基于图的方法:构建文档-词图,即直接连接文档节点及其中的词语节点、在文档中共现的词语节点。
用AUC作为评估指标。
(用不同词嵌入方法的结果见附件)

3.3 实验设置
在训练集上交叉验证3取参数。
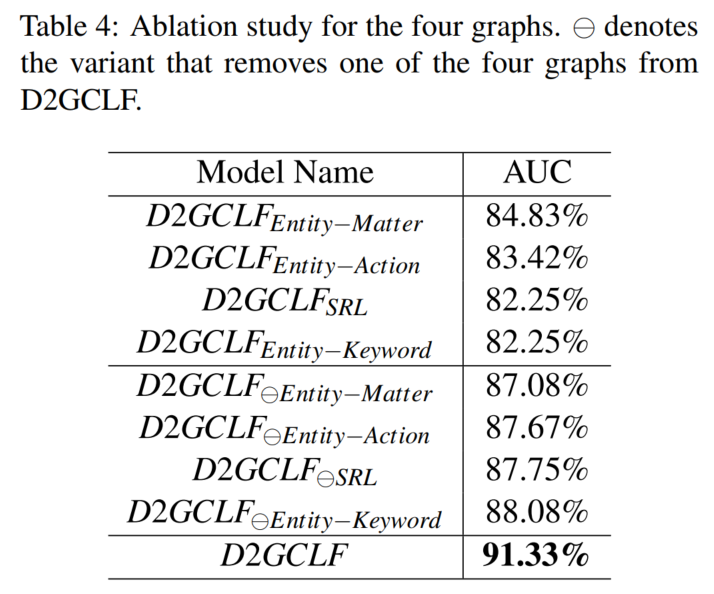
3.4 模型分析

https://pypi.org/project/pkuseg/ 具体使用方法可参考我撰写的博文:常用Python中文分词工具的使用方法 ↩︎
交叉验证相关资料,一时不知道该放在哪里,就先放在这里了:
Kaggle知识点:交叉验证常见的6个错误:在K的数量上一般选择5;用StratifiedKFold保持标签分布不变,用StratifiedGroupKfold保持按照对照组划分;先划分数据集后采样、做特征提取和转换操作;用TimeSeriesSplit划分时间序列;固定数据划分的随机种子 ↩︎
-
相关阅读:
Redis到底是单线程还是多线程
《痞子衡嵌入式半月刊》 第 102 期
区块链论文速读A会-ATC 2024 如何降低以太坊存档节点的存储要求?
PHP入门-Window 下利用Nginx+PHP 搭建环境
与缓存相关的状态码
运行的 akrun 会打印信息到控制台,如何取消打印 -- chatGPT
【2023】某python语言程序设计跟学第八周内容
Golang Xorm更新Mysql数据库 结构体内的0值数据未更新
Spring基础之AOP和代理模式
AD09 PCB拼板制作完整流程
- 原文地址:https://blog.csdn.net/PolarisRisingWar/article/details/126711341