-
【项目】实现一个mini的tcmalloc(高并发内存池)
tcmalloc
简单来说是谷歌一群大佬写的一个库,在高并发下比ptmalloc效率更高也更好用,go语言的内存管理器用的就是tcmalloc机制。下面我们实现的是mini版本,可以说是一个高并发内存池。
c语言用的是ptmalloc,gcc下有相应的选项让tcmalloc替换掉malloc.池化技术
把一些能够复用的东西放到池中,避免重复创建、销毁的开销,从而提高性能。
程序先向系统申请过量的资源,然后自己管理,以备多次申请。之所以要申请过量的资源,是因为每次申请该资源都有较大的开销,不如提前申请好了,这样用起来就会非常快捷,大大提高了程序的运行效率。比如内存池、连接池、线程池、对象池等。
我们这里的内存池也是同理,一次性申请一大块内存,之后什么时候要就从这大块内存取。
方便理解“池”的概念,我住山上,山上水资源紧缺,我每次用水都要去山下打水,那我自然会想建造一个池子,我一次性担很多水放到池子里,我要的时候里直接去池子里取就行了,相比于每次去山下的开销,显然在自己家附近建造一个池子的开销更小,而且更加快捷。
池化技术避免了反复的申请,减少了开销。
内存池解决的问题
- 效率的问题
生活费,我每次花钱都找爸妈,所以每次花钱前都要和爸妈沟通。 有了池化技术,我知道每个月大概要花八百块,那月初就向爸妈要八百块,那我每次用钱的时候就不用和爸妈沟通了,自己从小钱包里拿钱就行了。
内存池同理,每次要都像系统要,效率不高,不如一次申请好,要用就从池子里拿。
用了内存池,申请时的开销大一点,但是用起来就很快。
- 内存碎片问题
申请空间要求这块空间是连续的。所以会导致一种情况,内存里的空间是够的,但是碎片化了,也就是不连续,导致空间够了但我申请不出来。这就是内存碎片问题,导致我本该能申请出来的空间申请不出来了。
碎片分为内碎片和外碎片。下图表示的是外碎片

假设申请了四块空间,然后有了四块碎片,这四块碎片是不连续的,如果这四块碎片加起来是36KB,我们现在申请一个36KB大小的内存,会发现虽然可用的空间有36KB,但是因为碎片化了申请不出来。所以我们应该尽量避免碎片的产生。
malloc的相关知识
- tcmalloc和malloc的对比:TCMalloc与Malloc对比
- C和C++申请内存靠的是malloc,malloc向进程地址空间里的堆申请内存。
- c++常用new,我的理解new就是对malloc的封装,为什么要封装呢?符合C++一些抛异常的机制。
- 我们可以自定义operator new来自定义new,同时也可以通过定位new使得malloc可以调用构造方法。
- malloc也是一个内存池,进程调用malloc->库里调用brk()找操作系统要内存->操作系统执行brk(),brk()返回,malloc找到空闲内存块,申请内存成功,malloc返回。linux里有个函数sbrk(),是对brk()的封装。
- 如果我们用malloc去申请8字节的内存,一定不是只找系统要8字节,而是一次性要一个批量,比如一百万字节,这一百万字节就是池子,然后从池子里拿出八字节给malloc。
- malloc的底层实现是ptmalloc。
玩具malloc原理简述
下面的malloc只是简单的玩具,实际上远比这复杂。
这块找到的资料零零散散的,而且理解比较浅,有错误的地方敬请指出。
而且malloc的实现方式太多了,链表,位图,哈希桶等。。。
malloc也是采用的内存池技术,malloc用块来描述内存,每个块头上几个字节存储地址,表示next指针,接下来用一个标识来表示这块空间是否被使用(一般是一个比特位),再之后才是有效载荷或空闲的内存。将可用的空闲内存块通过next指针串起来,也就是链表。链表又分为单链表和双链表,大多数malloc的实现会采用双链表,利于内存块的合并和拆分。加上池化技术,malloc会一次从系统申请大块内存,然后进行管理。

代码实现上,块用结构体描述,里面会加许多别的属性,如块的大小等
malloc申请:
- 在链表上找到一个内存块给malloc,然后把这一块从链表上拿下来。
- 关于怎么在链表上找到这个内存块,有两种策略,一种是best fit,一种是first fit,best fit会找最合适的,比如有一块16KB,一块24KB的内存,我们要8KB,那best fit就会给16KB的,而first fit会找第一个匹配的。很多都会采用first fit,因为块,有点空间换时间的意思。
- 小于128KB的调用brk(),大于128KB的调用mmap()
- 如果我们要8KB,内存块是128KB,或者更大,那就会对这个128kb进行切分(split),切一块8KB的返回给malloc(用户),剩下的120KB依旧放在链表中,之后更改描述这个内存块的结构体属性即可。(这里有种操作系统管理的意味:操作的都是抽象出来的结构体,而不是说真的对这块内存做了什么。)
free释放:
- 块有个属性描述这个块是否在被使用,我们就知道当前要释放的块是否被使用,如果这块内存没被使用我们还free就会造成free两次的效果,此时在代码实现上就要对其进行相应的处理。
- 如果当前内存块确实在被使用,那还回去的过程就是链接到空闲链表的过程,链接上链表后,我们要检测当前块的上一个块和下一个块,如果上一个块或下一个块没有被使用,那就进行合并,合并之后得到一个更大的块,下次我们申请就可以申请出一个更大的块了,缓解了内存碎片的问题。
块虽然是链表连接起来的,但相当一部分内存块在物理上也是连续的。
ptmalloc简述
参考资料:
ptmalloc是glibc的内存管理器。glibc是GNU发布的c运行库。
铺垫
复习下基础知识
进程地址空间的存在让每个进程都专注于自己的事情,保证了进程的独立性,同时可以保护物理内存,直接访问物理内存不安全。

前面提过linux里的sbrk()本质是对brk()的封装。
_edata指针指向数据段的最高地址(我暂时理解为堆顶指针。。。
小于128KB的会调用brk将指针_edata向上推,大于128KB的直接调用mmap,从栈和堆直接分配一块虚拟内存。大于128K的使用完直接调用unmmap还给系统。
此外malloc只是分配了虚拟内存,并没有建立与物理内存的联系,第一次访问发生缺页中断才会建立与物理内存的映射。
缺页中断:陷入内核态->检查虚拟地址是否合法->合法分配物理页->填充物理页->建立映射。如果不合法的话会报页缺失的错误。
网上经常看到一句话:高地址的内存没释放,低地址的也不能释放,我对这句话的理解是:高地址的没释放,_edata指针不能往回缩紧,缩紧的意思可以理解为合并两块内存,如果两块或者多块内存合并后大于128KB(有些说是64KB),那就执行内存紧缩操作,即把 _edata指针往回退而不是真的说高地址内存没释放低地址就不能释放了(我们free的时候没有一定的要求,不过建议是后malloc的先free,利于减少内存碎片)

chunk
参考资料:
上面几篇讲的很清楚了,这篇文章里这个知识点不是重点,但事实上ptmalloc里内存的分配和释放和chunk这个结构紧密相关。
chunk结构可以理解为一个结构体,里面有着我们要的一些属性,比如chunk的大小,比如指向前一个chunk的指针,以及前一个chunk的大小等,这些属性的作用是便于内存的管理。
我对此只是简单的了解,ptmalloc给了多个bin(链表),申请的内存情况有很多种,有很小的,很大的,中规中矩的,对于每种内存有相应的bin,比如小内存找fast bin,大内存找top chunk,如果很大很大,那直接就找系统要了。合并的时候同理,小内存如果合并成大内存就也要更改所在的bin,通过这种方式就可以通过多个链表把这些内存管理起来了。
摘自上面某篇文章:
小内存: [获取分配区(arena)并加锁] -> fast bin -> unsorted bin -> small bin -> large bin -> top chunk -> 扩展堆
大内存: 直接mmap
线程安全
最开始了解ptmalloc的原因就是因为线程安全,我们这文章主要的目的是实现mini版的tcmalloc,为什么要写tcmalloc,因为高并发下tcmalloc比malloc优秀很多,要知道为什么tcmalloc比malloc优秀很多我们显然得先知道malloc是怎么保证线程安全的。
先给结论:malloc是线程安全的,但是不可重入。
malloc保证线程安全是通过分区和加锁实现的。
- 在内存分配器ptmalloc中,分为主分配区和非主分配区,本质都是内存池。主分配区和非主分配区借助环形链表管理
- 每个进程有一个主分配区,允许有多个非主分配区,每个分配区借助互斥锁使得访问这个分配区时不被别的线程打扰
- 主分配区可以使用brk和mmap分配,非主分配区使用mmap分配(与那个128K没啥关系)。申请小内存时会产生很多内存碎片,ptmalloc整理时也要对分配区加锁。
- 举个例子:一个线程找malloc分配内存,先看这个线程的私有变量中是否存在一个分配区,有的话就尝试加锁,加锁成功就会用这个分配区分配内存,不成功遍历循环链表找到未加锁的,找不到就创一个新的再加锁,然后再分配内存。释放时也要先获取内存所在的分配区的锁,如果别的线程在用这个分配区就得等。可以看出如果每个线程都私有一个分配区的话就可以避免竞争,此时就引出了TLS(TLS是线程内各个函数都有的,别的线程看不到的,被称之为线程局部存储,thread local storage),有了TLS就可以更快的找到分配区,tcmalloc也用到了TLS。虽然如此,malloc仍然需要多次加锁解锁,导致并发下效率不佳,而且用久了会有比较多的外碎片,所以多线程下建议用tcmalloc,tcmalloc利用一些方法使得不用频繁的加锁解锁。
关于malloc线程安全但是不可重入:
参考资料:malloc线程安全但不可重入??
我只是对上面的资料整合并且说一下自己的理解,理解上没有这些大佬那么透彻。
根据上面文章说的,malloc应该使用递归锁(可重入互斥锁)来避免信号中断带来的线程安全问题。如果一个进程执行malloc时收到了一个信号,之后进程中断去执行信号处理函数,如果信号处理函数里也有malloc,那可能导致死锁,因为第一次malloc的锁释放前就被中断了一直没释放,所以得用递归锁。
虽然这保证了malloc函数的线程安全,但是递归锁进去时可能破坏了共享的链表等资源,所以malloc是不能重入的。
此外破坏的资源是不可知的,所以执行malloc时被信号打断导致的结果是不可预料的,也因此我们说malloc虽然线程安全但是是不可重入的。(malloc的锁是分配区的锁,所以如果是同一个线程通过递归锁多次进入一个同一个分配区,即一个线程多次进入一个分配区,导致的问题是不可知的,但如果是不同的线程想进入同一个分配区,一般进入分配区前会提前尝试加锁,加锁失败就会去找别的分配区,也就保证了线程安全,此外递归锁的原理是计数器+记录线程号来保证同一线程可以多次进入一个函数放同时不会死锁)
简单来说,递归锁让不同线程不能同时进入一个分配区,也保证了同一个线程递归调用malloc不死锁,但是正因为递归锁允许一个线程多次进入malloc,使得malloc多次进入可能破坏一些资源,即malloc不可重入。
说白了就是这里用递归锁给了malloc重入的可能性,但碰到信号这样的malloc就可能会破坏当前进程的环境,或者说是资源,如一些锁,链表等,但不用递归锁的话我们又无法保证线程安全。
这也说明可重入函数一定线程安全,线程安全不一定可重入。
小结
如果还想了解ptmalloc的注意事项可以看前面的博客链接,我简单理解为下面几点
ptmalloc不适合长生命周期的内存。避免频繁分配内存,因为频繁的分配导致非主分配区增多,进而导致内存碎片增多。防止内存泄漏,ptmalloc对内存泄漏很敏感,根据他的内存紧缩机制,top chunk相邻的chunk没有被回收下面的chunk都回收不了,导致top chunk一下很多的内存不能还给系统(可以理解为上面的_edata指针不能往回走),内存不足时出现OOM,出现OOM会导致程序被系统干掉,所以我们应该预估号程序要的内存,避免OOM.(OOM:out of memory)
了解上面那些是为了更好的理解tcmalloc,知道tcmalloc为什么比malloc在高并发下更稳定、效率更高。
尺有所短寸有所长,malloc和tcmalloc都有自己的长短处,malloc的一些算法也是很多年前写的了,tcmalloc是谷歌里一群顶尖工程师写的,go语言的内存管理器也采用了开源的tcmalloc,tcmalloc整个项目是很庞大的,细节也很多,这里我们写的高并发内存池只不过是项目里的一角,对比真正的tcmalloc就是玩具,管中窥豹,可见一斑。
实现一个定长内存池
原理
定长内存池比作一个大块的长条内存,要的时候就切一块下来,特点是性能极致,几乎不会出现外碎片,因为每次切都是连续连续的切,切下来的内存使用完之后由自由链表管理(free后描述这个内存的数据结构会被链入自由链表)。特定情况下比malloc更快
申请大块内存

释放内存块

物理上内存块可能是连续的,但是我们逻辑上采用链表管理。
ObjectPool是定长内存池,负责创建和销毁T对象

代码
代码实现上,我们尽量脱离malloc,windows下malloc的底层是调用系统接口VirtualAlloc(),linux下是brk()和mmap(),我们在windows下写代码,所以采用条件编译+封装VirtualAlloc来脱离malloc.
封装VirtualAlloc,我们得到了一个SystemAlloc,参数是kpage,表示页号,每页的大小我们设定为8K。
SystemAlloc(5)就表示向系统申请5*8K=40K的空间
#ifdef _WIN32 #include#else //linux ... #endif // 直接去堆上按页申请空间 inline static void* SystemAlloc(size_t kpage) { #ifdef _WIN32 void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE); #else // linux下brk mmap等 #endif if (ptr == nullptr) throw std::bad_alloc(); return ptr; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
申请和释放
申请的优先级:自由链表>大块内存>系统
自由链表没有就去大块内存切,大块内存切不出就去找系统要,大块内存也就是我们的内存池。
切好的内存采用定位new初始化 (placement new的传送门)
申请从自由链表去:本质就是头删,留在链表里的都是可以使用的内存块,现在要取出来就是从链表里删除。
释放:本质就是自由链表的头插,不顾插入前记得调用T对象的析构。
代码的细节注释也写的比较清楚了,自行阅读即可。
void*& NextObj(void* obj) { return *((void**)obj);//得到这个内存块的头4/8个字节,等同于next指针,用来存储下一个结点的地址 }//用int*在64位下就会出问题,所以强转的类型是void** //对象内存池(定长去切,特定情况下效率比malloc略高) template<class T>//每次创建一个T对象 class ObjectPool { public: T* New()//申请一个T对象 { T* obj; //优先找自由链表,从自由链表里拿一个出来,头删 //头上的就是_freeList指向的 if (_freeList != nullptr) { obj = (T*)_freeList; _freeList = NextObj(_freeList); } else { //链表里没有,池子(大块内存)里剩下的字节不够一个对象时重新开辟 //重新开辟的时候调用系统api,跳过malloc if (_remainBytes<sizeof(T)) { _remainBytes = 16<<13;// _memory =(char*)SystemAlloc(_remainBytes>>13);//2^13==8KB,记得强转返回值的类型 if (_memory==nullptr)//分配失败抛异常 { throw std::bad_alloc(); } } obj = (T*)_memory; //如果申请的T是char存不下一个指针就给一个指针 //T类型存的下那T类型是多大就给多大 size_t actualNum = sizeof(T) > sizeof(void*) ? sizeof(T) : sizeof(void*); _memory += actualNum;//这也是为啥要用char* _remainBytes -= actualNum; } //上面的开好了空间,下面就要初始化了 //malloc初始化调用定位new new(obj)T; return obj; } void Delete(T* obj) { //显式的调用析构函数 obj->~T(); //链入自由链表,单链表采用头插 NextObj(obj) = _freeList; _freeList = obj; } private: char* _memory=nullptr;//开辟的指向大块内存的指针 void* _freeList=nullptr;//自由链表的头指针 //使用定长内存时一直在切,到最后可能要8字节只有5字节了就需要重新开辟并舍弃这5字节 size_t _remainBytes = 0; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
测试
我们说一些情况下定长内存池比malloc更快:比如申请单一对象的时候。(申请不同的对象,对象的大小不同每次切的大小也不同,就不太好切,所以定长内存池一般用于我们清晰的知道要申请什么,即固定大小的内存申请释放需求)
#includestruct TreeNode { int _val; TreeNode* _left; TreeNode* _right; TreeNode() :_val(0) , _left(nullptr) , _right(nullptr) {} }; void TestObjectPool() { // 申请释放的轮次 const size_t Rounds = 5; // 每轮申请释放多少次 const size_t N = 1000000; std::vector<TreeNode*> v1; v1.reserve(N); size_t begin1 = clock(); for (size_t j = 0; j < Rounds; ++j) { for (int i = 0; i < N; ++i) { v1.push_back(new TreeNode); } for (int i = 0; i < N; ++i) { delete v1[i]; } v1.clear(); } size_t end1 = clock(); std::vector<TreeNode*> v2; v2.reserve(N); ObjectPool<TreeNode> TNPool; size_t begin2 = clock(); for (size_t j = 0; j < Rounds; ++j) { for (int i = 0; i < N; ++i) { v2.push_back(TNPool.New()); } for (int i = 0; i < N; ++i) { TNPool.Delete(v2[i]); } v2.clear(); } size_t end2 = clock(); cout << "new cost time:" << end1 - begin1 << endl; cout << "object pool cost time:" << end2 - begin2 << endl; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
测试结果:

高并发内存池整体框架
高并发下主要考虑下面几个问题:
- 性能问题
- 多线程下锁的竞争问题
- 内存碎片问题
然后就有大佬设计出了这种三级缓存的结构:
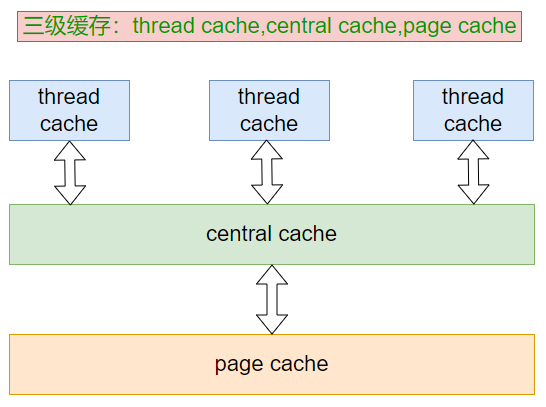
大体原理为:每个线程有自己的thread cache(cache现阶段理解为管理内存的数据结构)。线程通过自己的TLS申请内存,如果内存大小合适就进入三级缓存:thread cache不够找central cache要,central cache不够找page cache要,page cache不够找系统要。申请的内存过大就直接找系统要。
TLS是线程的局部存储,相当于只有线程自己看得到,别的线程都看不到的一个变量。因为线程各自私有就可以避免反复的加锁解锁了。
thread cache :每个线程独有自己的thread cache,所以就不用加锁了。这里避免了锁的竞争提高了性能。
central cache :中心缓存,起居中调度的作用。thread cache不够了就找central cache要,合适的时候central cache也会回收thread cache里的对象。中心缓存是多个线程公有的,所以会存在锁竞争问题,这里central cache采用哈希桶实现,每个桶都有一个锁,线程进入不同的桶和所有的线程走一个桶,哪个效率高一目了然了,所以这里锁的竞争不太激烈。(为什么锁的竞争引起效率不高?一个线程加锁了就表示别的线程要用只能在外面等着解锁,所以锁的竞争激烈会影响性能,我们这的桶锁就减缓了竞争,注意减缓而不是消除)
page cache :页缓存,central cache不够的时候找页缓存,页缓存以页为单位来管理内存,一页的大小是4KB或者8拷贝,虽然是我们写代码时决定的,但还是建议4/8KB。合适的时候会从central cache回收对象,回收后还会进行把小对象合并成大对象。页缓存是多个线程公有的,那自然要加锁,而且由于存储结构的原因,这里是一把“大锁”,即对这块进行读写就要加锁。
具体的过程会在下面展开。
三级缓存
thread cache

上图可以知道Thread Cache是哈希桶结构,其中最小的桶是8字节,最大的桶是256KB。那一共有多少个桶呢?
如果每1字节对应一个桶,那256KB=256*1024B=262144B,就需要二十多万个桶,显然管理这么多个桶太麻烦了,所以采用了一种映射策略,控制内碎片在10%。映射策略是向上对齐,1-128字节以8字节对齐,129-1024字节以16字节对齐,1025- 8 * 1024字节以128字节对齐…后面一共对齐出206个桶,相比二十多万个桶,显然管理206个桶轻松很多。
// 整体控制在最多10%左右的内碎片浪费 // [1,128] 8byte对齐 freelist[0,16) // [128+1,1024] 16byte对齐 freelist[16,72) // [1024+1,8*1024] 128byte对齐 freelist[72,128) // [8*1024+1,64*1024] 1024byte对齐 freelist[128,184) // [64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208) static inline size_t _RoundUp(size_t bytes,size_t alignNum)//向上对齐 { //bytes是申请的字节,alignNum是对齐数 //bytes为6就给8字节,bytes为129就给144字节 return (((bytes)+alignNum - 1) & ~(alignNum - 1)); //~(alignNum-1)让alignNum为1的那一位后面的位都是0,其余的位都是1,保证答案肯定是对齐数的倍数 //((bytes)+alignNum - 1)让某位变成1,保证答案一定向上对齐 //上面两个部分&一下,得到的数后面几位都是0,其余的位和((bytes)+alignNum - 1)的每一位对应相等 //后面几位都是0保证得到的数一定是对齐数的倍数 //自己代两个数算一下就明白了 } static inline size_t RoundUp(size_t size) { assert(size > 0); if (size<=128) { return _RoundUp(size, 8); } else if (size <= 1024) { return _RoundUp(size, 16); } else if (size <= 8*1024) { return _RoundUp(size, 128); } else if (size <= 64*1024) { return _RoundUp(size, 1024); } else if (size <= 256*1024) { return _RoundUp(size, 8*1024); } else { //申请大于256KB的 //assert(false); //以1<- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
对于上面的映射策略这里举个例子,比如我要申请1个字节,1-128字节的对齐数是8字节,所以1字节向上对齐到8字节,即申请一字节给8字节。
向上对齐导致了部分空间的浪费,比如我们申请5字节给了8字节,那这3个字节就是内碎片,但是内碎片和外碎片不同,内碎片回收回来下次还能用,外碎片产生了如果不合并就一直在那了,所以malloc不适合一直在跑的程序(因为malloc可能产生很多内存碎片,然后越来越卡,这是有可能的。)
central cache

从图中可知中心缓存也是哈希桶结构,并且其桶的映射规则与thread cache一样,不同的是线程缓存管理的是可以直接用的小块内存,而中心缓存管理的是span对象
span对象
span可以译为跨度
中心缓存管理的是span对象。span可以切成小块内存分给thread cahce,在合适的时候也会把分出去的内存回收回来。从这个角度上可以把span理解为大块内存(span的英文是跨度的意思)。
span有一些属性,比如span的大小,span对象的大小单位是页(1页是4KB或者8KB,由我们自己定义,代码中定为8KB),不同的span大小可能不同,如当前span是否在被使用,span分成了几块小内存,切成的小内存又是多大等,span最开始是从page cache里更大的内存切来的,所以会有个相关属性是页号(这个属性便于把span回收到page cache),此外还有一些别的属性。span回收的逻辑涉及到合并,所以管理span的桶不采用单链表,而采用双链表管理。
一般是用完一个span再申请一个,但是由于回收等的原因,一个桶下面是可以存在多个空的span,而不是说一个桶里只有一个span为空。
//管理多个连续页的大块内存跨度结构 //属性记得初始化 struct Span { //大块内存起始页的页号 //64位下以每页8KB为例一共有2^64/2^13=2^51页,int存不下,用unsigned long long+条件编译解决 PAGEID _pageId = 0; //页的数量,有几页大小 size_t _n = 0; //双向链表的结构 Span* _next=nullptr; Span* _prev = nullptr; //切好的小块内存被分配给thread cache的计数 size_t _useCount = 0; //切好的小块内存的自由链表 void* _freeList = nullptr; //当前span是否在被使用 bool _isUse = false; //这个span切的小对象的大小 size_t _objSize = 0; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
page cache

从图中可以看出也是哈希桶结构,但是映射的规则与前面两层不同,page cache哈希桶的映射规则是直接映射,比如1page对应的桶,每个桶都是一个循环双链表,链表的每一个元素都是span,1page桶对应的span的大小就是1页。
page cache和central cache虽然管理的对象都是span,但是span对象是不同的,central cache里的span对象主要作用是切成小对象然后用链表挂起来给thread cache用,而且同一个桶里的几个span大小可能是不同的,但是page cache一个桶里的span都是相同的。
page cache里的span是为central cache准备的,central cache里没有合适大小的span时就会去找page cache要,span的大小是以页为大小的,自然大页可以切成小页给central cache用。那page cache没有内存时呢?找系统要一个大块内存,然后挂到page cache里。
申请与释放
申请
我们要向池子里申请6个字节,具体过程是怎样的?
首先肯定是一个线程,线程独有的TLS调用对应的申请函数,申请函数根据字节数算出thread cache里对应的桶,去看桶里面有没有小块内存,有的话直接给。
没有的话去找central cache要,中心缓存给线程缓存一次肯定不止给一个,而是给一个批量,所以中心缓存对应函数算出批量,再根据字节对应的桶号去桶里看有没有不为空的span,有的话就给thread cache,thread cache也就申请到了内存,
如果桶里的span都为空的话就去找page cache申请一个新的span,page cache遍历自己的桶,找出一个span给central cache,central cache拿到span后切成小块内存切好挂起来。
如果page cache里找不到合适的span,就去找系统申请一个大块的内存,然后挂到page cache里然后再给central cache,page cache切好后给thread cache,线程也就拿到了对应的内存。
细节
细节主要是从代码的角度
- 小内存是怎么用链表挂起来的?
内存块的前4或8个字节存储下一个内存块的地址,充当next指针。
- 中心缓存给线程缓存一次给一个批量,批量怎么算?
批量的计算采用慢开始算法,第一次给1个,第二次给2个…其中上限是512个。
static size_t NumMoveSize(size_t size)//越小的字节算出来的批量越大,但上限是512 { assert(size > 0); size_t num = MAX_BYTES / size;//MAX_BYTES就是256KB if (num<2) { num = 2; } if (num>512) { num = 512; } return num; } //----------------------慢开始算法----------------- { int batchNum = (num > _freeList[index]._MaxSize) ? _freeList[index]._MaxSize : num; if (batchNum == _freeList[index]._MaxSize) { _freeList[index]._MaxSize+=1;//对应桶的maxsize++ } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 中心缓存的桶里面有没有空的span是什么意思?
中心缓存里空的span即span下面没挂小内存,即切分好的小内存都被分配出去了,找不到小内存给thread cache了,所以这里就称这种叫空的span。即span里的小内存用完了
- 怎么看中心缓存对应的桶下面有没有不为空的span?
span是用循环双链表串起来的,遍历这个循环双链表即可。找不到再去申请新的span
- 中心缓存有的话给thread cache这句话包含了什么过程?
中心缓存的span下面挂的小内存是用链表挂起来的,现在要给线程缓存,所以先把要给线程缓存的那一段拿出来,然后再把这一段里除第一个小内存块外的都挂到thread cache上去,即thread cache在对应的桶下面插入一段,第一个小内存块不插入,是因为第一个是我们申请的要用内存。
- 找page cache申请一个新的span是怎样的?
span的大小单位是页,中心缓存给线程缓存的是一个批量,这里页缓存给中心缓存的也是用到了批量,比如我们申请的是6字节,批量算出最多给512个,512*6=3072字节,一页是8192字节,说明给一页就够了,即central cache找page cache要一个一页的span,page cache是根据页数来映射的,那从第一个桶开始,遍历所有的桶,看有没有不为空的桶,比如遍历到第三个桶不为空,第三个桶对应的span就是3页大小,那就从第三个桶拿出一个span,切成一个1页的span给central cache,剩下的两页挂回page cache,即挂到page cache的第二个桶。这里central cache就拿到了一个新的span,再切分成对应的小块内存,再给thread cache用就行了。
线程如果是从central cache里拿到一批内存,这批内存的第一个就是我们申请要用的,其余的会被挂起来,也即池化技术,下次要用直接拿即可,其中有一些慢开始算法,映射桶的算法,对齐数的算法等,详细了解还得看代码。
释放
释放一个内存,在我们的池子里就是把对应的小内存块挂回thread cache,再将其进行回收合并等操作。
回收一个内存块,根据内存块的地址算出其对应大小,根据大小挂回线程缓存对应的桶里,这里有两种策略,thread cache某个桶的大小太大或者这个桶里的元素太多都可以将其回收回page cache。这里我们采用桶里的元素过多就将其回收回central cache。
如果桶里的元素过多,将其回收到中心缓存的span里,如果某个span所有分配出去的小内存都回来了,就将这个span回收到page cache对应的页中,page cache看span对应的页能不能前后合并,将span对应的几页尽量合并成大页,再挂回page cache对应的桶中
细节
- 挂回线程缓存的桶里即把这个内存块链入相应桶对应的链表。
- 页号与地址的关系
地址转为一个数字除以8192就是对应的页号,所以64为下编号肯定会大于无符号整型,所以需要条件编译。
//条件编译保证能够存储页号不溢出 //64位下会定义_WIN64和_WIN32两个宏,32位只会定义_WIN32 #ifdef _WIN64 typedef unsigned long long PAGEID; #elif _WIN32 typedef size_t PAGEID; #else typedef unsigned long long PAGEID; #endif // _WIN64- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 根据内存块的地址怎么算出其大小?
我们在之前申请的过程中建立页号与span*的映射,地址转换成一个数除以8192即可算出对应的页号,根据页号再映射对应的span上,span里有一个属性_objSize表示这个span切成的小对象的大小,我们当前的内存块就是来源于这个span,则 _objSize就是当前内存块的大小
- 根据大小挂回线程缓存对应的桶里
根据大小自然可以算出对应的桶号,再把这个内存块插入对应的链表(桶)中即可。
- 桶里的元素过多是什么意思
元素过多表示链表太长了,即链表的元素过多。(桶是我们抽象出来的概念,其具体实现是链表)
-
thread cache里的链表太长,回收的是一个批量,而不是一个内存块。批量的体现就是一段链表
-
回收一个批量的内存回central cache的过程?
回收一个批量,即回收一个链表,首先在线程缓存里把这一段链表给删除了,找到链表每个元素对应的span,挂回span下面的链表,其中span有个属性为_useCount,span下面的链表分配出去一个 _useCount++,现在回来一个就 _useCount–,减到0就说明这个span分配出去的都回来了,就把这个span回收到page cache
- span里_isUse属性的必要性
为什么需要_isUse, _useCount等于0不就说明没人在用吗?但是存在这么一种情况,我刚申请出一个新的span,正在切分这个span,但是还没用这个span, _useCount不就是0吗,此时正好在合并,一看这个span的 _useCount==0没人用直接拿来合并,导致另一边把刚申请出来的就拿回去合并了,而且还回去了还切分显然不合理,所以引入一个 _isUse标志,来标志当前span有没有在使用。
- page cache怎么合并?
根据span的页号找到其前面的页,根据前面建立的映射关系从页号拿到对应的span(从这我们可以看出建立span映射时要建立首尾页的映射),记为prevSpan,如果没有前面的页、prevSpan在使用或者合并后页的大小超过了128,那就不合并,反之就合并,合并到不能合并为止,这是向前合并,同理向后合并,合并的本质就是改span的属性,再把合并好的span挂回pageCache。
//开始往前合并 //改变span的属性 while (1) { //找到前面的页 PAGEID prevId = span->_pageId - 1; //没有前面的页 //auto ret = _idSpanMap.find(prevId); auto ret = (Span*)_idSpanMap.get(prevId); //if (ret==_idSpanMap.end()) if (ret==nullptr) { break; } //前面的页在使用了 Span* prevSpan = ret; if (prevSpan->_isUse==true) { break; } //合并后的页大于等于NPAGES if (prevSpan->_n+span->_n>=NPAGES) { break; } //可以合并了 span->_pageId = prevSpan->_pageId; span->_n += prevSpan->_n; _spanList[prevSpan->_n].Erase(prevSpan);//解决span的prev和next指针 //把以前描述span的结构体delete了,两个合并成一个肯定有一个没了 //delete prevSpan; _spanPool.Delete(prevSpan); } //再将其向后合并 while (1) { //找到后面的页 PAGEID nextId = span->_pageId+span->_n ; //没有后面的页 //auto ret = _idSpanMap.find(nextId); auto ret = (Span*)_idSpanMap.get(nextId); if (ret == nullptr) { break; } //后面的页在使用了 Span* nextSpan = ret; if (nextSpan->_isUse == true) { break; } //合并后的页大于等于NPAGES if (nextSpan->_n + span->_n >= NPAGES) { break; } //可以合并了 span->_pageId = nextSpan->_pageId; span->_n += nextSpan->_n; _spanList[nextSpan->_n].Erase(nextSpan);//解决span的prev和next指针 //把以前描述span的结构体delete了,两个合并成一个肯定有一个没了 //delete nextSpan; _spanPool.Delete(nextSpan); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
加锁与解锁
操作central cache时要加桶锁,桶锁可以减少竞争。
central cache锁住的情况下调用page cache的函数肯定要加page cache的锁,那page cache上锁之前要不要把central cache的锁解开?要的,解开后可以让别的线程还内存给这个桶进而提高效率
对不同大小的内存块的处理
线程缓存和中心缓存最大的桶映射的是256KB,页缓存最大的桶映射的是128页,一页是8KB,128*8=1024KB。所以我们将内存块分为三类:
- 小于等于256KB
- 大于256KB小于等于1024KB
- 大于1024KB的
申请内存时:
其中小于等于256KB的,走三层缓存,即从thread cache到page cache。
大于256KB小于等于1024KB,直接走page cache。
大于1024KB的,直接找系统要(或者说找堆要)。
不管这个申请的内存多大,我们都会建立相应的span,只是大小在三层缓存内的我们会挂到相应的桶里,三层缓存外的就不会挂到桶里(没有相应的桶啊)
释放内存时:
大于256KB的直接由地址拿到对应的span,然后直接把span还到page cache。
小于等于256KB的那就先还给thread cache,再往下判断是否回收到central cache,走到central cache再判断是否合并起来还给page cache。
注意池子里的内存不会还给系统了。
优化
替换new
之前写了个定长内存池,也可以叫做对象池,即要申请固定的对象时用对象池比new更快.
我们的代码实现中用的new的地方都是在new span,所以可以进一步提高效率,建立一个span对象内存池来替换new.
//对象池替换new ObjectPool<Span> _spanPool; -------------------- //Span* span = new Span; Span* span = _spanPool.New();- 1
- 2
- 3
- 4
- 5
基数树
先前我们提到要建立页号和span*映射,实现上肯定就是哈希表了。如果是用STL的unordered_map,那就要加锁,显然加锁带来的性能损耗是很大的。所以我们解决掉这个加锁的问题后可以进一步优化我们的程序。
建立的映射是页号和一个地址的映射,但是页号这个数可能很大,在64位下得用unsigned long long来存,所以选用了基数树这种数据结构。
基数树可以在一棵树内快速查到一个key,即可以快速查到一个长整数,此外基数树在插入一个数或者删除一个数结构不会变。
基数树的结构我们放在page cache内,我们只有在new一个新的Span的时候才会建立相应的映射,即往基数树里写,其余的时间都在读。(这个得熟悉对应的代码,完整代码放在最后的github链接里)
比如有两个线程,这两个线程new的span对应的页号肯定是不同的,即两个线程肯定不会new同一个span。也就说明两个线程肯定不会对基数树的同一个位置写入,进而说明基数树肯定是线程安全的,即可以不加锁。除此之外new Span这个函数是在central cache内调用的,调用前会加page cache的大锁,所以基数树肯定线程安全。那就直接用基数树替换掉之前的哈希表。这样使得性能进一步提高,其实通过VS的一些调试工具可以发现这就是我们项目当前的一个性能瓶颈,我们用基数树替代了STL里的哈希解决了这一个瓶颈。
基数树RadixTree,里面有基数树对应的图和介绍,比较清晰。
换个角度理解基数树,我们这用的基数树目的是为了实现哈希,替换掉STL的unordered_map,所以从哈希的角度看基数树可以抽象成下面的结构

上面的结构是一层基数树,64位下因为数字太大了,一层的存不下,所以得用三层的,一层一层的往下面递进。

剩下的bug
在64位的系统下跑不起来,因为一开始写的时候是按32位写的,条件编译没做到位。也可能是基数树第三层的代码有问题,因为一层基数树可以直接映射,64位下得用三层映射。
完整代码
-
相关阅读:
4年后,Debian终夺回“debian.community“ 域名!
GBase 8s 执行计划查询分析
使用eXplorer本地搭建免费在线文件管理器并实现远程登录——“cpolar内网穿透”
python面试题合集(一)
利用视觉分析技术提升水面漂浮物、水面垃圾检测效率
DoS是什么?
快速批量升级 NugetPackage 版本
Redis学习笔记18:基于spring data redis及lua脚本的分布式锁
Python国庆祝福
asp毕业设计——基于asp+access的新闻发布系统设计与实现(毕业论文+程序源码)——新闻发布系统
- 原文地址:https://blog.csdn.net/m0_53005929/article/details/126691709
