-
写代码,必须要优雅...
大家好,我是 Jack。
最近看了一个新动画,间谍过家家,12 集都追完了,意犹未尽。
里面有一个细节:
优雅的劳埃德先生,通过暗号来解读报纸上的情报,普通的报纸上隐藏着想要传递的消息。

暗号 
解析 其实,程序员的我们,传递秘密的方式,可以更优雅。
劳埃德先生看后都会直呼:「对不起,我不是一个优雅的人!」
这张看似普通的约尔美照下面,其实藏着另一个人,你发现了吗?

肉眼很难看出来,但只需要运行一下程序,将图片下采样,就能得到阿尼亚的照片。

同理,照片里也可以藏文字,运行一下程序,就能得到一篇 160 万字的小说。

请问,这种情报传递的方式,够优雅吗?
今天,我就教教大家,这“恐怖如斯”(斗破梗)的实用技能。
学会了,别忘了在女朋友/男朋友面前秀一手,藏个表白照片,再藏段肉麻表白文,玩法很多,就看你脑洞有多大。
视频已经首发在了 B 站:

视频地址:
https://www.bilibili.com/video/BV1XV4y1p7nS
下面是图文版教程和代码:
其实,原理很简单,放大图片,我们就能发现这张约尔的图片上,有着规律分布的杂点,而这些点就是组成阿尼亚照片的像素点。

缩小约尔美照时,电脑会把这些杂点挑选出来,代替它们周围的点,组成缩小后的画面。
电脑刚好能挑选出这些掺入的点,是因为这些位置都是提前计算好的,这里用到的算法就是邻近法。
举个简单的例子,一张 9 * 9 的黑图,如果把它用邻近法缩放到 3 * 3 的正方形。
电脑首先会将这张图分成 9 份,取每份正中间的点,代替它周围的 8 个点,来组成缩小后的图片。

也就是说,如果我们将每份正中间的点改成红色,从整体看,他还是黑图,只是看起来有些杂色。

但图片缩小后,黑色正方形就变成了红色正方形。

看下生成代码和解析代码:
- # -*- coding: utf-8-*-
- # Author: Jack Cui
- import sys
- from turtle import width
- import cv2
- from PIL import Image
- import numpy as np
- def parse_from_img(img_path):
- img = cv2.imread(img_path)
- img_h, img_w, _ = img.shape
- stepx = 10
- stepy = 10
- sml_w = img_w // stepx
- sml_h = img_h // stepy
- res_img = np.zeros((sml_h, sml_w, 3), np.uint8)
- for m in range(0, sml_w):
- for n in range(0, sml_h):
- map_col = int(m * stepx + stepx * 0.5)
- map_row = int(n * stepy + stepy * 0.5)
- res_img[n, m] = img[map_row, map_col]
- return res_img
- def generate_img(big_img_path, small_img_path):
- big_img = cv2.imread(big_img_path)
- sml_img = cv2.imread(small_img_path)
- dst_img = big_img.copy()
- big_h, big_w, _ = big_img.shape
- sml_h, sml_w, _ = sml_img.shape
- stepx = big_w / sml_w
- stepy = big_h / sml_h
- for m in range(0, sml_w):
- for n in range(0, sml_h):
- map_col = int(m * stepx + stepx * 0.5)
- map_row = int(n * stepy + stepy * 0.5)
- if map_col < big_w and map_row < big_h:
- dst_img[map_row, map_col] = sml_img[n, m]
- return dst_img
学过深度学习的小伙伴,对这种操作绝对不陌生,这就是一种特定的卷积操作。
卷积甚至可以设置得更复杂一些,比如像这样。
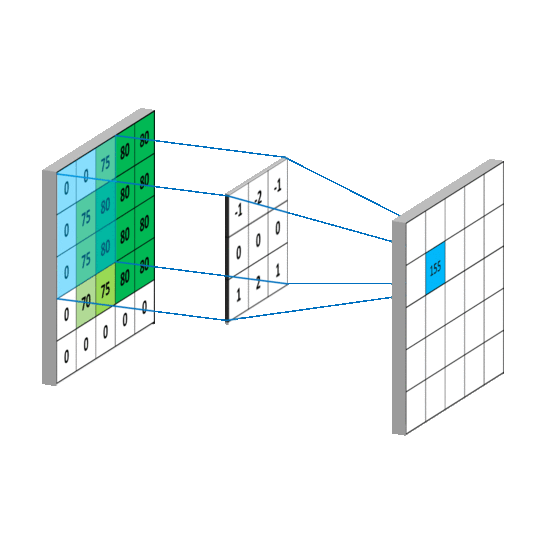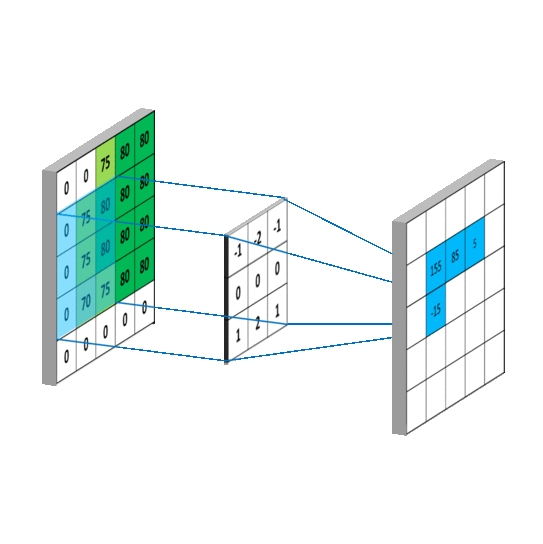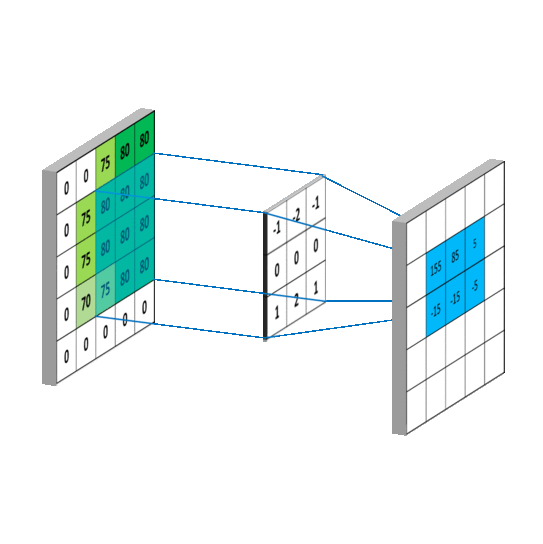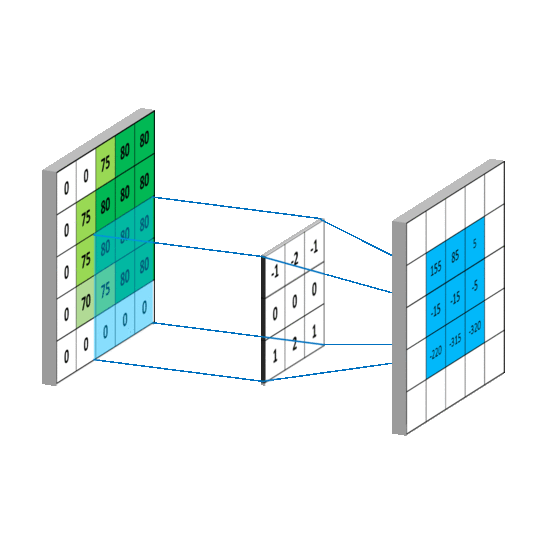
照片里能藏照片,同样也就能藏文字。
我们知道,图片是由 RGB 三通道组成的,其实就是一串数字。

而文字的编码也是一串数字,比如请给我三连,这个连字。
它的 Unicode 数值是 36830,这是十进制,转换为十六进制就是(8F, DE)。
那也就可以写成(0x00,0x8F,0xDE),R 通道不赋值为零,G 通道和 B 通道赋值。
显然,将文字的 Unicode 数值,表示成 RGB 数值的形式,就可以将文字转换成图片,一个像素点代表一个文字。
一张 1000 * 1680 分辨率的图片,就可以存储 168 万个文字。
文字的生成图片代码和解析代码:
- # -*- coding: utf-8-*-
- # Author: Jack Cui
- import sys
- from turtle import width
- import cv2
- from PIL import Image
- import numpy as np
- def Img2Text(img_fname):
- img = cv2.imread(img_fname)
- height, width, _ = img.shape
- text_list = []
- for h in range(height):
- for w in range(width):
- R, G, B = img[h, w]
- if R | G | B == 0:
- break
- idx = (G << 8) + B
- text_list.append(chr(idx))
- text = "".join(text_list)
- with open("斗破苍穹_dec.txt", "a", encoding="utf-8") as f:
- f.write(text)
- def Text2Img(txt_fname, save_fname):
- with open(txt_fname, "r", encoding="utf-8") as f:
- text = f.read()
- text_len = len(text)
- img_w = 1000
- img_h = 1680
- img = np.zeros((img_h, img_w, 3))
- x = 0
- y = 0
- for each_text in text:
- idx = ord(each_text)
- rgb = (0, (idx & 0xFF00) >> 8, idx & 0xFF)
- img[y, x] = rgb
- if x == img_w - 1:
- x = 0
- y += 1
- else:
- x += 1
- cv2.imwrite(save_fname, img)
拓展一下,其实只要按照一定的规则,将某些信息写入到图片内,就能达到神不知鬼不觉地保存这些信息的目的。
这个规则,可以设置地复杂一些,并且生成规则和解析规则只有你知道,这样就能得到一张只有你能读懂的照片。

除了这种间谍过家家,逗逗男女朋友,其实这项技术,有着更有意义的用途:用于保护知识产权的数字水印技术。
将影视作品的版权信息,存到视频本身的画面中,这,就是数字水印技术。
与传统的水印不同,这种水印很难被察觉,也很难被抹去,版权信息需要通过特定的解析计算才能得到。

出于好奇,我联系了一位在阿里安全做数字水印的朋友,想看看他们的技术,是否跟我想得差不多。
不看不知道,一看吓一跳。思路大致相同,但是他们设计得更为复杂。
首先,他们的技术鲁棒性要好很多。
比如对一副图片进行裁剪、缩放、有损压缩等,鲁棒性强的水印技术依然能够提取出我们想要的版权等信息。
阿里安全的数字水印鲁棒性就很好,我要来了一个他们的效果,大家可以感受一下。
电视播放着《流浪地球》这部电影,这段视频中隐藏了版权信息,版权信息咱们设为 123456789。此时,有台摄像机正在盗摄画面。

对盗摄后的画面进行分析,可以看到,程序呢,轻松地解析出了信息:123456789。

有了这个技术就能追踪溯源,甚至找出盗摄者。
对画面缩放到非常小,程序还是能够解析出信息:123456789。
甚至只盗摄一部分画面,比如只有画面一小块,程序依然能解析出信息:123456789。

文字表述不够直观,大家可以直接看视频感受一下,解析是有多准确!
视频地址:
https://www.bilibili.com/video/BV1XV4y1p7nS
无论是缩放还是裁剪,程序都能轻松地解析出想要的信息。
在各种噪声和攻击下,水印的漏检率小于 1%,误检率小于10的负9次方。
就很猛!
可见,他们的策略不是简单的在像素中插入数值那么简单,还做了很多提高鲁棒性的工作。
具体细节没有对我透露,毕竟这是人家的产品,发了很多专利,甚至还得到了好莱坞认证。
现在有了国内自主研发的水印产品,这样就可以避免受制于人。
懂的都懂,技术还是自己研发的好。
zu
知识产权保护任重而道远,不仅仅要靠平台,也需要我们每个人的帮助。
视频被盗,维权很困难,特别是对一些小 up。
比如我 21 年的一期视频,被剪辑,盗用发布在了某手。

好家伙,他将我 AI 还原乾隆后妃样貌的视频进行了裁剪,拆分成了三期视频发布。
更杀人诛心的是,每期视频都比我原视频播放高就算了,向官方举报盗用视频还无济于事,以无法鉴别的理由给我回绝了。
现在有了数字水印这项技术,这类问题就有了解决方案,在不影响视频画面的情况下,还能藏入版权信息,只要各个平台都接入这类技术,视频是不是盗用,还不一目了然?
当然,光靠一项技术,想要完全保护知识产权是不可能的,还需要每个平台,每个环节的配合,也需要有完善的、公平的鉴别规则。
只有这样,那些辛辛苦苦做视频的小 up,才能不被视频盗用的问题磨灭了创作热情。
只有这样,那些投资大量人力、物力创作的影视作品,才能不被盗摄盗版等问题弄得焦头烂额。
这就是这项技术的价值所在。
未来,还会有很多技术创新用于解决社会问题。
这些科研人员,每往前走一点,我们生活的安全感就可能多一分。
感谢这些一直在背后努力的人。生成和解析代码以及素材,我已经打包放到了我的公众号:jackcui-ai,后台回复「优雅」,即可获得。
好了,今天就聊这么多,我是 jack,我们下期见~
最后再送大家一本,帮助我拿到 BAT 等一线大厂 offer 的数据结构刷题笔记,是一位 Google 大神写的,对于算法薄弱或者需要提高的同学都十分受用:
以及我整理的 BAT 算法工程师学习路线,书籍+视频,完整的学习路线和说明,对于想成为算法工程师的,绝对能有所帮助:
别光收藏,来个赞哦,笔芯~
-
相关阅读:
Spring注解处理机制
Windows下Nacos安装
牛客网 ACM 模式 输入输出
【愚公系列】2022年6月 ASP.NET Core下CellReport报表工具基本介绍和使用
论文字数和检测字数有什么区别?
【红队】要想加入红队,需要做好哪些准备?
你必须要掌握的大数据计算技术,都在这了
GEE:根据影像最小值和最大值自适应可视化参数设置
单独用HTML javascript CSS 写三版99乘法表,我就是班里最靓的仔
spring基本使用
- 原文地址:https://blog.csdn.net/c406495762/article/details/126622205