-
RNN&GNU&LSTM与PyTorch
官方APIRNN: 循环神经网络 short-term memory 只能记住比较短的时间序列的信息,时间长了会遗忘
GRU: 折中方案,相对于LSTM更加简单,计算成本更低
LSTM: 长短期记忆神经网络 long short-term memory 能够记住比较长的时间序列信息RNN

h ′ = t a n h ( W i h x + b i h + W h h h + b h h ) x : [ b a t c h _ s i z e , i n p u t _ s i z e ] h h ′ : [ b a t c h _ s i z e , h i d d e n _ s i z e ] W i h : [ i n p u t _ s i z e , h i d d e n _ s i z e ] W h h : [ h i d d e n _ s i z e , h i d d e n _ s i z e ] b i h b h h : [ h i d d e n _ s i z e ] " role="presentation">CLASS torch.nn.RNNCell(input_size, hidden_size, bias=True, nonlinearity='tanh', device=None, dtype=None) # nonlinearity: The non-linearity to use. Can be either 'tanh' or 'relu'. Default: 'tanh' # 输入: # input [batch_size, input_size] # hidden [batch_size, hidden_size] (Defaults to zero if not provided.) # 输出: # h' [batch_size, hidden_size] CLASS torch.nn.RNN(input_size, hidden_size, num_layers=1, nonlinearity='tanh', bias=True, batch_first=False, dropout=0, bidirectional=False, device=None, dtype=None) # num_layers: Number of recurrent layers. E.g., setting num_layers=2 would mean stacking two RNNs together to form a stacked RNN, with the second RNN taking in outputs of the first RNN and computing the final results. Default: 1 # dropout: If non-zero, introduces a Dropout layer on the outputs of each RNN layer except the last layer, with dropout probability equal to dropout. Default: 0 # bidirectional: If True, becomes a bidirectional RNN. Default: False # 注:bidirectional=False,则实际num_layers层;bidirectional=True,则实际2 * num_layers层 # D=2 if bidirectional=True otherwise 1 # 输入: # input [seq_len, batch_size, input_size] 或 PackedSequence # h_0 [D*num_layers, batch_size, hidden_size] (Defaults to zero if not provided.) # 输出: # output(单向最上面一层的所有输出,双向最上面两层的所有输出) [seq_len, batch_size, D*hidden_size] # h_n(所有层的最后隐状态hidden state) [D*num_layers, batch_size, hidden_size]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
GRU

r = σ ( W i r x + b i r + W h r h + b h r ) z = σ ( W i z x + b i z + W h z h + b h z ) n = t a n h ( W i n x + b i n + r ∗ ( W h n h + b h n ) ) h ′ = ( 1 − z ) ∗ h + z ∗ n x : [ b a t c h _ s i z e , i n p u t _ s i z e ] h h ′ : [ b a t c h _ s i z e , h i d d e n _ s i z e ] W i ? : [ i n p u t _ s i z e , h i d d e n _ s i z e ] W h ? : [ h i d d e n _ s i z e , h i d d e n _ s i z e ] b : [ h i d d e n _ s i z e ] " role="presentation" style="position: relative;">CLASS torch.nn.GRUCell(input_size, hidden_size, bias=True, device=None, dtype=None) # 输入: # input [batch_size, input_size] # hidden [batch_size, hidden_size] (Defaults to zero if not provided.) # 输出: # h' [batch_size, hidden_size] CLASStorch.nn.GRU(input_size, hidden_size, num_layers=1, bias=True, batch_first=False, dropout=0, bidirectional=False, device=None, dtype=None) # D=2 if bidirectional=True otherwise 1 # 输入: # input [seq_len, batch_size, input_size] 或 PackedSequence # h_0 [D*num_layers, batch_size, hidden_size] (Defaults to zero if not provided.) # 输出: # output(单向最上面一层的所有输出,双向最上面两层的所有输出) [seq_len, batch_size, D*hidden_size] # h_n(所有层的最后隐状态hidden state) [D*num_layers, batch_size, hidden_size]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
LSTM
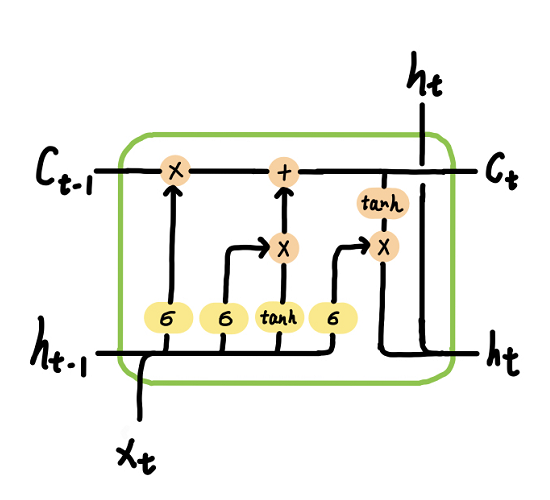
f = σ ( W i f x + b i f + W h f h + b h f ) i = σ ( W i i x + b i i + W h i h + b h i ) g = t a n h ( W i g x + b i g + W h g h + b h g ) o = σ ( W i o x + b i o + W h o h + b h o ) c ′ = f ∗ c + i ∗ g h ′ = o ∗ t a n h ( c ′ ) x : [ b a t c h _ s i z e , i n p u t _ s i z e ] h h ′ : [ b a t c h _ s i z e , h i d d e n _ s i z e ] c c ′ : [ b a t c h _ s i z e , h i d d e n _ s i z e ] W i ? : [ i n p u t _ s i z e , h i d d e n _ s i z e ] W h ? : [ h i d d e n _ s i z e , h i d d e n _ s i z e ] b : [ h i d d e n _ s i z e ] " role="presentation" style="position: relative;">CLASS torch.nn.LSTMCell(input_size, hidden_size, bias=True, device=None, dtype=None) # 输入: # input [batch_size, input_size] 或 PackedSequence # h_0 [batch_size, hidden_size] (Defaults to zero if not provided.) # c_0 [batch_size, hidden_size] (Defaults to zero if not provided.) # 输出: # h_1 [batch_size, hidden_size] # c_1 [batch_size, hidden_size] CLASStorch.nn.LSTM(input_size, hidden_size, num_layers=1, bias=True, batch_first=False, dropout=0, bidirectional=False, proj_size=0, device=None, dtype=None) # proj_size – If > 0, will use LSTM with projections of corresponding size. Default: 0 # D=2 if bidirectional=True otherwise 1 # 输入: # input [seq_len, batch_size, input_size] # h_0 [D*num_layers, batch_size, hidden_size或proj_size](proj_size不为0时[D*num_layers, batch_size, proj_size]否则[D*num_layers, batch_size, hidden_size]) (Defaults to zero if not provided.) # c_0 [D*num_layers, batch_size, hidden_size] (Defaults to zero if not provided.) # 输出: # output(单向最上面一层的所有输出,双向最上面两层的所有输出) [seq_len, batch_size, D*hidden_size或D*prog_size] # h_n(所有层的最后隐状态hidden state) [D*num_layers, batch_size, hidden_size或prog_size] # c_n(所有层的最后单元状态cell state) [D*num_layers, batch_size, hidden_size]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
辅助函数
问题
一个batch中的3个样本,最长长度为5,用0填充,如下图1所示。将3个样本的数据按照时间步不断输入一个RNN、GRU、LSTM单元时,样本1和样本2有多次输入了padding的数据0。为了减少padding的影响,我们希望样本1输入1后即得到最后的hidden state(或加cell state)、样本2输入2、3、4后即得到最后的hidden state(或加cell state),如下图2所示。可以使用后面的PackedSequence实现。
在seq2seq应用中,编码器推荐用此方法,因为h_5是对待翻译句子的记忆,而解码器不必要

pad_sequence & unpad_sequence

torch.nn.utils.rnn.pad_sequence(sequences, batch_first=False, padding_value=0.0) 参数: sequences (list[Tensor]): list of variable length sequences 返回: [max_seq_len, batch_size, *] (*表示剩余的多个维度) # 注意:该函数将对padded_sequences进行原址变换。在batch_first=False下padded_sequences由[max_seq_len, batch_size] -> [batch_size, max_seq_len];在batch_first=True下padded_sequences将保持[batch_size, max_seq_len]。推测该形态可能是unpad_sequence过程中的中间状态bug。 torch.nn.utils.rnn.unpad_sequence(padded_sequences, lengths, batch_first=False) 参数: padded_sequences (Tensor): [max_seq_len, batch_size, *] (*表示剩余的多个维度) lengths (Tensor): length of original (unpadded) sequences. 返回: list of variable length sequences- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
import torch from torch.nn.utils.rnn import pad_sequence, unpad_sequence a = torch.tensor([1]) b = torch.tensor([2, 3, 4]) c = torch.tensor([5, 6, 7, 8, 9]) test_data = [a, b, c] lengths = torch.as_tensor([v.size(0) for v in test_data]) padded_sequences = pad_sequence(test_data) print(padded_sequences) sequences = unpad_sequence(padded_sequences, lengths) print(sequences) # tensor([[1, 2, 5], # [0, 3, 6], # [0, 4, 7], # [0, 0, 8], # [0, 0, 9]]) # [tensor([1]), tensor([2, 3, 4]), tensor([5, 6, 7, 8, 9])] import torch from torch.nn.utils.rnn import pad_sequence, unpad_sequence a = torch.tensor([1]) b = torch.tensor([2, 3, 4]) c = torch.tensor([5, 6, 7, 8, 9]) test_data = [a, b, c] lengths = torch.as_tensor([v.size(0) for v in test_data]) padded_sequences = pad_sequence(test_data) print(padded_sequences) sequences = unpad_sequence(padded_sequences, lengths) print(sequences) # tensor([[1, 2, 5], # [0, 3, 6], # [0, 4, 7], # [0, 0, 8], # [0, 0, 9]]) # [tensor([1]), tensor([2, 3, 4]), tensor([5, 6, 7, 8, 9])] padded_sequences = pad_sequence(test_data) print(padded_sequences) sequences = unpad_sequence(padded_sequences, lengths) print(padded_sequences) # tensor([[1, 2, 5], # [0, 3, 6], # [0, 4, 7], # [0, 0, 8], # [0, 0, 9]]) # tensor([[1, 0, 0, 0, 0], # [2, 3, 4, 0, 0], # [5, 6, 7, 8, 9]]) padded_sequences = pad_sequence(test_data, batch_first=True) print(padded_sequences) sequences = unpad_sequence(padded_sequences, lengths, batch_first=True) print(padded_sequences) # tensor([[1, 0, 0, 0, 0], # [2, 3, 4, 0, 0], # [5, 6, 7, 8, 9]]) # tensor([[1, 0, 0, 0, 0], # [2, 3, 4, 0, 0], # [5, 6, 7, 8, 9]])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
pack_padded_sequence & pad_packed_sequence

# (重要)注:input是长度降序(enforce_sorted随意) 或 input不是长度降序但指定enforce_sorted=False,否则抛出异常 torch.nn.utils.rnn.pack_padded_sequence(input, lengths, batch_first=False, enforce_sorted=True) 参数: input (Tensor): padded batch of variable length sequences. lengths (Tensor or list(int)): list of sequence lengths of each batch element. (must be on the CPU if provided as a tensor). enforce_sorted: if True, the input is expected to contain sequences sorted by length in a decreasing order. If False, the input will get sorted unconditionally. Default: True. 返回: a PackedSequence object # (重要)注:如果pack_padded_sequence的 input不是长度降序但指定enforce_sorted=False,那么pad_packed_sequence返回值也不是长度降序而是本来的顺序。 torch.nn.utils.rnn.pad_packed_sequence(sequence, batch_first=False, padding_value=0.0, total_length=None) 参数: sequence (PackedSequence): batch to pad total_length (int, optional): if not None, the output will be padded to have length total_length. This method will throw ValueError if total_length is less than the max sequence length in sequence. 返回: Tuple of Tensor containing the padded sequence, and a Tensor containing the list of lengths of each sequence in the batch. Batch elements will be re-ordered as they were ordered originally when the batch was passed to pack_padded_sequence or pack_sequence.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
# PackedSequence中sorted_indices为sorted_input在input上的顺序,unsorted_indices为input在unsorted_input上的顺序 # 若传入的input是长度降序,则sorted_input和unsorted_indices均为tensor([0, 1, ..., batch_size - 1]) import torch from torch.nn.utils.rnn import pad_sequence, pack_padded_sequence, pad_packed_sequence a = torch.tensor([1]) b = torch.tensor([2, 3, 4]) c = torch.tensor([5, 6, 7, 8, 9]) test_data = [a, b, c] lengths = torch.as_tensor([v.size(0) for v in test_data]) padded_sequences = pad_sequence(test_data) print(padded_sequences) # tensor([[1, 2, 5], # [0, 3, 6], # [0, 4, 7], # [0, 0, 8], # [0, 0, 9]]) pack_padded = pack_padded_sequence(padded_sequences, lengths, enforce_sorted=False) print(pack_padded) # PackedSequence(data=tensor([5, 2, 1, 6, 3, 7, 4, 8, 9]), # batch_sizes=tensor([3, 2, 2, 1, 1]), # sorted_indices=tensor([2, 1, 0]), # unsorted_indices=tensor([2, 1, 0])) pad_packed = pad_packed_sequence(pack_padded) print(padded_sequences) # tensor([[1, 2, 5], # [0, 3, 6], # [0, 4, 7], # [0, 0, 8], # [0, 0, 9]])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
pack_sequence & unpack_sequence
# pad_sequence & pack_padded_sequence的合体 torch.nn.utils.rnn.pack_sequence(sequences, enforce_sorted=True) 参数: sequences (list[Tensor]): A list of sequences of decreasing length. enforce_sorted (bool, optional): if True, checks that the input contains sequences sorted by length in a decreasing order. If False, this condition is not checked. Default: True. 返回: a PackedSequence object # pad_packed_sequence & unpad_sequence的合体 torch.nn.utils.rnn.unpack_sequence(packed_sequences) 参数: packed_sequences (PackedSequence): A PackedSequence object. 返回: a list of :class:`Tensor` objects- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
import torch from torch.nn.utils.rnn import pack_sequence, unpack_sequence a = torch.tensor([1]) b = torch.tensor([2, 3, 4]) c = torch.tensor([5, 6, 7, 8, 9]) pack_seq = pack_sequence([a, b, c], enforce_sorted=False) print(pack_seq) # PackedSequence(data=tensor([5, 2, 1, 6, 3, 7, 4, 8, 9]), # batch_sizes=tensor([3, 2, 2, 1, 1]), # sorted_indices=tensor([2, 1, 0]), # unsorted_indices=tensor([2, 1, 0])) unpack_seq = unpack_sequence(pack_seq) print(unpack_seq) # [tensor([1]), tensor([2, 3, 4]), tensor([5, 6, 7, 8, 9])]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
语言翻译例
import torch import torch.optim as optim import torch.utils.data as Data from torch import nn from torch.nn import RNN from torch.nn.utils.rnn import pad_sequence, pack_padded_sequence # ==================================================================================================== # 参数配置 if torch.cuda.is_available(): device = 'cuda' else: device = 'cpu' epochs = 1000 input_size = 512 hidden_size = 512 # ==================================================================================================== # 数据处理 sentences = [ # 中文和英语的单词个数不要求相同 # enc_input dec_input dec_output ['我 有 一 个 好 朋 友', 'S i have a good friend .', 'i have a good friend . E'], ['我 有 零 个 女 朋 友', 'S i have zero girl friend .', 'i have zero girl friend . E'] ] # 中文词库 src_vocab = {'P': 0, '我': 1, '有': 2, '一': 3, '个': 4, '好': 5, '朋': 6, '友': 7, '零': 8, '女': 9} src_idx2word = {w: i for i, w in src_vocab.items()} src_vocab_size = len(src_vocab) # 英文词库 tgt_vocab = {'P': 0, 'i': 1, 'have': 2, 'a': 3, 'good': 4, 'friend': 5, 'zero': 6, 'girl': 7, 'S': 8, 'E': 9, '.': 10} tgt_idx2word = {w: i for i, w in tgt_vocab.items()} tgt_vocab_size = len(tgt_vocab) class MyDataSet(Data.Dataset): """ 自定义DataLoader,返回: enc_input: [batch_size, len_src] dec_input: [batch_size, len_tgt] dec_output: [bath_size, len_tgt] enc_input_len: [batch_size] """ def __init__(self, sentences, src_vocab, tgt_vocab): super(MyDataSet, self).__init__() self.len = len(sentences) self.enc_input = [] self.dec_input = [] self.dec_output = [] self.enc_input_len = [] for i in range(self.len): self.enc_input.append(torch.tensor([src_vocab[n] for n in sentences[i][0].split()])) self.dec_input.append(torch.tensor([tgt_vocab[n] for n in sentences[i][1].split()])) self.dec_output.append(torch.tensor([tgt_vocab[n] for n in sentences[i][2].split()])) self.enc_input_len.append(len(self.enc_input[-1])) # padding之后的长度即为len_src self.enc_input = pad_sequence(self.enc_input, batch_first=True) # padding之后的长度即为len_tgt dec = pad_sequence(self.dec_input + self.dec_output, batch_first=True) self.dec_input = dec[:self.len] self.dec_output = dec[self.len:] def __len__(self): return self.len def __getitem__(self, idx): return self.enc_input[idx], self.dec_input[idx], self.dec_output[idx], self.enc_input_len[idx] loader = Data.DataLoader(MyDataSet(sentences, src_vocab, tgt_vocab), 2, True) # ==================================================================================================== # RNN模型 class Model(nn.Module): def __init__(self, input_size, hidden_size, src_vocab_size , tgt_vocab_size): super(Model, self).__init__() self.src_emb = nn.Embedding(src_vocab_size, input_size) self.tgt_emb = nn.Embedding(tgt_vocab_size, input_size) self.rnn = RNN(input_size, hidden_size) self.projection = nn.Linear(hidden_size, tgt_vocab_size) def forward(self, enc_input, dec_input, enc_input_len): """ :param enc_input: [batch_size, len_src] :param dec_input: [batch_size, len_tgt] :param enc_input_len: [batch_size] :return: """ # [len_src/len_tgt, batch_size, input_size] enc_input = self.src_emb(enc_input.t()) dec_input = self.tgt_emb(dec_input.t()) # [1, batch_size, hidden_size] # 注意,虽然enforce_sorted=False使得rnn会将enc_input排序为长度降序,但返回的hidden_state的batch顺序和原始输入enc_input相同 _, hidden_state = self.rnn(pack_padded_sequence(enc_input, enc_input_len, enforce_sorted=False)) # [len_tgt, batch_size, hidden_size] output, _ = self.rnn(dec_input, hidden_state) # [len_tgt, batch_size, hidden_size] # -> [len_tgt, batch_size, tgt_vocab_size] # -> [len_tgt * batch_size, tgt_vocab_size] dec_logits = self.projection(output) dec_logits = dec_logits.view(-1, dec_logits.size(-1)) return dec_logits # ==================================================================================================== # 训练 model = Model(input_size, hidden_size, src_vocab_size, tgt_vocab_size) model = model.to(device) criterion = nn.CrossEntropyLoss(ignore_index=tgt_vocab['P']) optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.99) # 用adam的话效果不好 for epoch in range(epochs): for enc_input, dec_input, dec_output, enc_input_len in loader: """ enc_input: [batch_size, len_src] dec_input: [batch_size, len_tgt] dec_output: [batch_size, len_tgt] enc_input_len: [batch_size] """ enc_input, dec_input, dec_output = enc_input.to(device), dec_input.to(device), dec_output.to(device) output = model(enc_input, dec_input, enc_input_len) loss = criterion(output, dec_output.t().flatten()) print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss)) optimizer.zero_grad() loss.backward() optimizer.step() # ========================================================================================== # 预测 def greedy_decoder(model, enc_input, src_vocab, tgt_vocab, device): """ :param model: 模型 :param enc_input: str sequence :param src_vocab: 源语言字典 :param tgt_vocab: 目标语言字典 :param device: 设备 :return: """ # str seq -> tensor int seq # [1, ?] ?和len_src可以不等 seq = torch.tensor([[src_vocab[n] for n in enc_input.split()]], device=device) # tensor([], size=(1, 0), dtype=torch.int64) dec_input = torch.zeros(1, 0).to(device=device, dtype=torch.int64) # 首先存入开始符号S next_symbol = tgt_vocab['S'] terminal = False while not terminal: # [1, dec_input_len_cur] dec_input = torch.cat([dec_input, torch.tensor([[next_symbol]]).to(device)], -1) # [dec_input_len_cur, tgt_vocab_size] dec_logits = model(seq, dec_input, [seq.shape[1]]) # [1] next_symbol = dec_logits[-1].argmax() print(tgt_idx2word[next_symbol.item()]) if next_symbol == tgt_vocab["E"]: terminal = True greedy_decoder(model, '我 有 零 个 女 朋 友', src_vocab, tgt_vocab, device)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
-
相关阅读:
FTP 基础 与 使用 Docker 搭建 Vsftpd 的 FTP 服务
【Hack The Box】linux练习-- Blocky
征战MINI学习路线
ant design vue:自定义锚点样式
linux 进程管理相关内容
CPU卡学习
潮玩宇宙源码开发:开启全新的数字潮流时代
对比Python,PySpark 大数据处理其实更香
pdf转excel,如何把pdf转换成excel表格
【云原生之K8s】 Pod控制器
- 原文地址:https://blog.csdn.net/qq_42283621/article/details/126620495
