-
hadoop
文章目录
知识点
HDFS: 安装部署,配置参数,架构思想(DataNode, NameNode),基本原理 、文件读写, 元数据,命令操作,API操作,联邦路由,机架感知,基本调优,RPC。
YARN:架构思想,组成模块,基本原理,调度器,调度原理, API操作,日志查看,参数优化,运维调优。
MapReduce: 安装部署,配置参数,架构思想,基本原理、map reduce的过程,API操作,shuffle, 读写原理
日志聚集
Hadoop 3.x
Hadoop 是分布式系统基础架构。在某种程度上将多台计算机组织成了一台分布式计算机执行任务,
hadoop三大组件:
HDFS 相当于这台分布式计算机的硬盘,文件系统
YARN 相当于CPU、内存资源控制器
MapReduce 是这台计算机运行程序的框架HDFS文件读写,用MapReduce框架编写程序,提交给YARN运行
发行版本
三大发行版本:Apache、Cloudera、Hortonworks。
Apache 版本最原始(最基础)的版本
Cloudera 内部集成了很多大数据框架,对应产品 CDH。
Hortonworks 文档较好,对应产品 HDP。
2018被收购,推出新的品牌 CDP。安装部署
hadoop version # 配置 cd $HADOOP_HOME/etc/hadoop |-- workers 记录所有的数据节点的主机名或 IP 地址 |-- core-site.xml Hadoop 核心配置 |-- hdfs-site.xml HDFS 配置项 |-- mapred-site.xml MapReduce 配置项 |-- yarn-site.xml YRAN 配置项 # 启停 cd $HADOOP_HOME/sbin # 启动HDFS(NameNode节点) start-dfs.sh # 启动YARN(ResourceManager节点) start-yarn.sh cd $HADOOP_HOME/bin # 资料,案例 cd $HADOOP_HOME/share- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
高可靠性:数据块复制备份在不同服务器上
高扩展性:节点方便扩展
高性能:任务跟数据走
数据本地性原则
(1)任务和数据在同一节点
(2)任务和数据在同一机架
(3)任务和数据不在同一节点也不在同一机架
高容错性:能够自动将失败的任务重新分配。
高可用 HA模式
- namenode ,ResourceManager 高可用 ;一个以上Master 节点
HDFS
文件系统
HDFS 集群是建立在 Hadoop 集群之上
- 适用场景:一次写入,多次读出,PB级别数据
概念
主从结构,NameNode=主,DataNode=从
一个文件分成多个数据块 block 存储到DataNode,文件元数据记录在NameNode
数据块 block
存储单位:block 块, 默认128M
命名节点 (NameNode)
-
节点数量:(2.x 1个)(3.x 多个)
-
作用:
保存元数据(文件目录结构,文件名,文件属性、文件的block列表 与所在的DataNode)
指挥其它节点存储的节点 -
元数据都先保存到内存、定时持久化到本地磁盘
-
一个block一条数据,block位置由DataNode维护
数据节点 (DataNode)
储存block的节点
每个 block 都会有一个校验码,并存放到独立的文件中,以便读的时候来验证其完整性
数据在 DataNode 之间是通过 pipeline 的方式进行复制的
副命名节点 (Secondary NameNode)
-
节点数量:多个
-
作用:
分摊命名节点的压力、定时备份NN的状态并执行一些管理工作
提供备份数据以恢复命名节点
小文件存储问题:
一个文件如果小于128MB,则按照真实的文件大小独占一个数据存储块,存放到DataNode节点中
1浪费DataNode空间 2NameNode存储元数据膨胀
- 合并小文件
- 核心思想都是基于map/reduce的方式将多个文件合并成一个文件
- 多Master设计
- 让元数据分散存放到不同的NameNode中。
- HAR:Hadoop归档文件,文件以*.har结尾。将多个小文件归档为一个文件,包含元数据信息和小文件内容
将Namenode管理的元数据信息下沉到Datanode上的归档文件中
归档文件是逻辑上的概念,而实际的har是一个目录,是一个物理存储概念

-
SequenceFile 存储方案
二进制文件格式,类似key-value存储, 通过MR程序从文件中将文件取出 -
CombinedFile 存储方案
基于Map/Reduce将原文件进行转换,通过CombineFile InputFormat类将多个文件分别打包到一个split中, 将小文件进行整合 -
基于HBase的小文件存储方案
-
基于打包构建索引方案
基于压缩的思路,将多个小文件压缩成一个tar文件存放至HDFS上,通过HBASE记录文件名和HDFS文件的位置映射关系
对于既要存储大文件又要存储小文件的场景,我建议在上层作一个逻辑处理层,在存储时先判断是大文件还是小文件,再决定是否用打包压缩还是直接上传至HDFS
工作流程
写
HDFS Client:本地磁盘的HDFS客户端(文件切分,提供HDFS命令,读写数据)

- 内容 写入本地磁盘 临时文件
- 向NameNode申请上传文件;临时文件大小达到block大小时 向NameNode申请写block
- NameNode创建文件(不可见),把 block id和DataNode列表 返回给客户端
- 文件 写入 DataNode,并复制
- 文件内容写入第一个 DataNode
- 第一个 DataNode 写入磁盘,传输给第二个 DataNode,以此类推
- 后面的DataNode接收完文件内容,向前一个DataNode发送确认信息
- 写入某个 DataNode 失败,数据会继续写入其他的 DataNode。然后 NameNode 会找另外一个好的 DataNode 继续复制,以保证冗余性
- 最后全部完成接收,第一个DataNode 返回确认信息给HDFS Client
- HDFS Client接收到整个 block 的确认后,会向 NameNode 发送一个最终的确认信息
- 写完文件,NameNode 提交文件,(文件可见)
读

- 向发起HDFS Client读请求
- HDFS Client向NameNode发送读取请求
- NameNode返回文件的所有block和这些block所在的DataNodes(包括复制节点)
- HDFS Client 直接从DataNode中读取数据,如果该DataNode读取失败(DataNode失效或校验码不对),则从复制节点中读取
使用
Web 页面
查看 HDFS 上存储的数据信息 http://NameNode-IP:9870- 1
- 2
命令行
hadoop fs [命令]
hdfs dfs [命令]
# 显示根目录 / 下的文件和子目录,绝对路径 hadoop fs -ls / # 新建文件夹,绝对路径 hadoop fs -mkdir /hello # 上传文件 hadoop fs -put hello.txt /hello/ # 下载文件 hadoop fs -get /hello/hello.txt # 输出文件内容 hadoop fs -cat /hello/hello.txt # 从本地磁盘复制文件到HDFS hadoop fs -copyFromLocal [localSource] [hdfs] # 检查文件的完整性 hadoop fsck # 重新平衡HDFS start-balancer.sh- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
java api
<dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-clientartifactId> dependency>- 1
- 2
- 3
- 4
MapReduce
- 网络IO速度 << 本地磁盘IO速度
代码向数据迁移:大数据系统会尽量地将任务分配到离数据最近的机器上运行(程序运行时,将程序及其依赖包都复制到数据所在的机器运行) 尽量让一段数据的计算发生在同一台机器上
-
传输时间 << 寻道时间
一般数据写入后不再修改
概念
数据类型-序列化 (Writable)
hadoop 数据只在自己集群节点传输, 需要序列化 不需要复杂的处理,自己实现了比java轻量的序列化
-
序列化接口:Writable
-
默认序列化类型
Java类型 Hadoop Writable类型 boolean BooleanWritable byte ByteWritable int IntWritable float FloatWritable long LongWritable double DoubleWritable String Text map MapWritable array ArrayWritable - 自定义序列化类型
- 实现 Writable 接口
- 实现序列化接口
- 实现反序列化接口,(反序列化反射要调用空构造函数)
- 重写toString()
- 实现comparable排序接口
MapReduce进程
-
两个阶段
一个 Map 阶段和一个 Reduce 阶段 -
三类实例
MrAppMaster实例: 整个程序的过程调度及状态协调
map阶段:并发执行MapTask 实例
Reduce 阶段:并发执行ReduceTask 实例
切片
job提交
- 数据切片:是 MapReduce 程序计算 **输入数据的单位 **;
- 数据切片=逻辑存储单位
- HDFS数据块 =物理存储单位
FileInputFormat每个文件单独切片
MapTask 实例个数
-
数量:一个MapTask处理一个切片》MapTask个数=切片数
- MapTask拷贝在DataNode上去处理数据,如果要处理的数据在其他DN节点,需要去其他DN读取数据
-
切片大小
- 默认 切片大小=blocksize,一个DataNode一个MapTask
切片规划文件提交到YARN上,YARN上的MrAppMaster就可以根据切片规划文件计算开启MapTask个数。
分区
shuffle阶段,数据按照条件输出到不同文件
分区号必须从零开始,逐一累加
- 默认Partitioner分区:根据key的hashCode对ReduceTasks个数取模
public int getPartition(K key, V value, int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; }- 1
- 2
- 3
-
自定义Partitioner
- 自定义类继承Partitioner,重写getPartition()方法
- 在Job驱动中,设置自定义Partitioner
- 自定义Partition后,要根据自定义Partitioner的逻辑设置相应数量的ReduceTask
job.setPartitionerClass(CustomPartitioner.class); job.setNumReduceTasks(n);- 1
- 2
- 3
ReduceTask 实例个数
- ReduceTask的数量 > getPartition的结果数
- 则会多产生几个空的输出文件part-r-000xx;
- 1 < ReduceTask的数量 < getPartition的结果数
- 则有一部分分区数据无处安放,会Exception;
- ReduceTask的数量 = 1
- 不管MapTask端输出多少个分区文件,最终结果都交给这一个 ReduceTask,最终也就只会产生一个结果文件 part-r-00000
driver类,job提交
程序入口 driver类
作用:job驱动,提交job, yarn创建MrAppMaster进程(Mr=job)
job.waitForCompletion(); submit(){ // 1 建立连接 connect(); // 创建job代理 // 判断是 yarn集群运行环境 还是 本地运行环境 YarnClient LocalClient // 2 提交job // 创建job路径 // 拷贝jar包到集群 // 计算切片,产生 切片规划文件 // 提交job,返回状态 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

工作流程

输入 输出 input 文件 mapper list ( shuffle list ( reduce list ( MapTask 实例
作用:分割及映射
并发运行MapTask处理数据, 互不相干
InputFormat
- 作用:读取数据给map()
- 所有的输入格式都继承于InputFormat抽象类
各种InputFormat读取机制不同:
- FileInputFormat 读文件
- TextInputFormat 一次一行,k=文件字节偏移量 v=行内容
- NLineInputFormat 一次多行读取,处理小文件
- DBInputFormat 把数据库表的数据读入到HDFS中
- TableInputFormat 读取HBase
默认用TextInputFormat类
class TextInputFormat{ // 读取文件,返回kv给mapper RecorderReader(){} // 判断文件是否可切片 isSplitable(){} }- 1
- 2
- 3
- 4
- 5
- 6
- 自定义InputFormat
- 自定义一个类继承
FilelnputFormat。 - 自定义一个类继承
RecordReader,实现一次读取一个完整文件,将文件名为key,文件内容为value。 - 在输出时使用
SequenceFileOutPutFormat输出合并文件。
- 自定义一个类继承
mapper
- 输入 InputFormat的kv
- 每个InputFormat的kv执行一次map()方法
- map()输出自定义kv
Mapper抽象类
// 输入kv Mapper< 输入k,输入v,输出可排序类型k,输出v> >{ //重写三个方法:reduce() setup() cleanup () map(输入k,v,Context); setup(Context); cleanup(Context); public void run(Context context){ setup(context); try { while (context.nextKeyValue()){ map(...) } } finally { cleanup(context); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
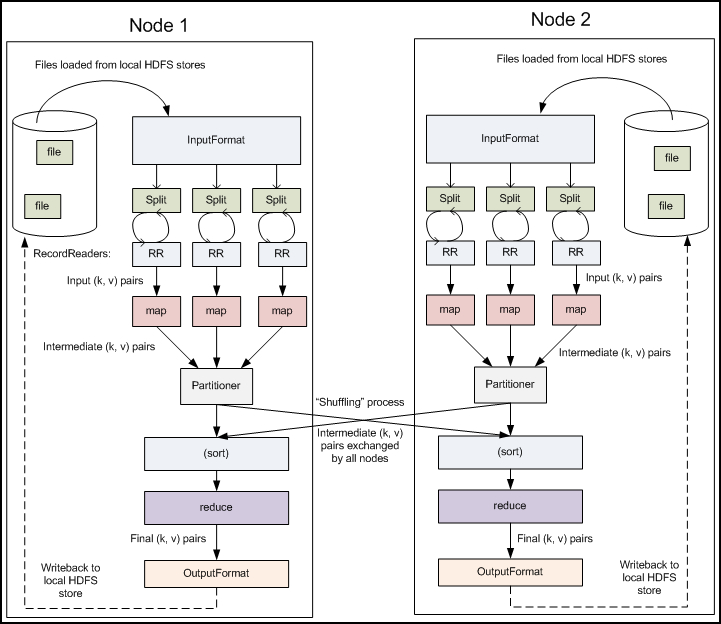
Shuffle
在map阶段输出时,reducer拉取之前,混洗数据的过程
- 环形缓冲区:默认100m,左半存Mata索引,右半存数据,占用到80%后逆写

- map输出数据
- 标记数据 分区(不同分区的数据给不同的Reduce去处理),放入环形缓冲区
- 环形缓冲区 达到溢写阈yu值,对同一分区内的数据 用key 按字典 快排
- 【多次】环形缓冲区–溢写–>磁盘 输出2个文件:索引文件 spill.index 内容文件 Spill.out
- 【可选】分区合并流程 Combiner (分区内按key合并
- 【可选】分区合并流程 Combiner (分区内按key合并
- 归并排序(对磁盘上的多个溢写文件 相同分区归并)
- 【可选】分区合并流程 Combiner (分区内按key合并)
- 压缩(map数据压缩后传输给reduce)
- 输出到磁盘
- 不同分区还是输出到一个文件
排序
hadoop默认会对key进行排序
map阶段:环形缓冲区,溢写前快排,溢写后归并
reducer阶段:拉取数据后归并排序
- 部分排序:输出多个文件,每个内部有序
- 全排序:输出一个文件,内部有序
- 辅助排序:进入reducer的key重新排序
- 二次排序
- 自定义排序实现
合并
可选流程。shuffle最后 相同key合并
- 自定义Combiner实现
压缩
优:以减少磁盘 IO、减少磁盘存储空间
缺:增加 CPU 开销
IO 密集型的 Job,多用压缩
ReduceTask 实例
作用:重排,还原,合并结果
依赖map阶段MapTask的输出,并发运行ReduceTask处理数据, 互不相干
Reducer

- 从各个map输出数据 拉取(远程拷贝) 指定分区 的数据
- 数据放入内存,内存不够溢写到磁盘;
- 内存文件大小/数量达到阈值 合并后溢写到磁盘
- 磁盘文件数量达到阈值, 进行 归并排序 输出一个大文件
- 拷贝完毕后,按key分组 归并排序
- 调用reducer()
Reducer抽象类
// 输入kv = map输出kv的聚合 Reducer< 输入kv<String,int>,输出kv<String,int> >{ //重写三个方法:reduce() setup() cleanup () reduce(k,Iterable<v>,Context); setup(Context); cleanup(Context); public void run(Context context){ setup(context); try { while (context.nextKey()){ reduce(...) } } finally { cleanup(context); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
OutputFormat
输出到文件、mysql、其他数据库等等
默认实现类是 TextOutputFormat,
功能逻辑是:将每一个 KV 对,向目标文本文件输出一行。
- 自定义OutputFormat
1. 自定义一个 RecordWriter类 继承RecordWriter,写输出流
1. 自定义一个 OutputFormat类 继承OutputFormat
3. OutputFormat 类 RecordWriter方法 return RecordWriter
开发:wordCount
输入 输出 input 源文件 < 行偏移,行内容 > mapper < 行偏移,行内容 > list ( shuffle list ( <有序 归并word, list(1)> reduce list ( mapper类
重写 map()
void map(key,value,context){ //获取一行 String line = value.toString(); //行分词 String[] words = line.split(" "); //输出 Text outK = new Text(); IntWritable outV = new IntWritable(1); outK.set(word); context.write(outK,outV); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
reducer类
- 继承Reducer抽象类
// 输入kv = map输出kv的聚合 Reducer< 输入kv<String,int>,输出kv<String,int> >- 1
- 2
-
逻辑写在 reducer() 方法
-
ReducerTask 对每组相同k的输入kv调用一次reducer()
重写 reducer()
void reduce(key,Iterable<Int> values,context){ //遍历 values集合 for (IntWritable count : values) { //累加value sum += count.get(); } //输出 IntWritable v = new IntWritable(); v.set(sum); context.write(key,v); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
driver类
public class WordCountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 1 获取配置信息, 获取 job 对象实例 //框架会按照JobConf描述的信息去完成这个作业 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 2 关联本 Driver 程序的 jar job.setJarByClass(WordCountDriver.class); // 3 关联 Mapper 和 Reducer 的 jar job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); // 4 设置 Mapper 输出的 kv 类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 5 设置最终输出 kv 类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 6 设置输入和输出路径 job.setInputFormatClass(input类.class); job.setOutputFormatClass(output类.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7 提交 job boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
运行:
# 运行job,本地方式或yarn方式 # hadoop jar[mainClass: driver类名] args... hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar wordcount input.txt output- 1
- 2
- 3
应用案例:
join
需求:读取不同的数据格式,进行join操作(2张表 数据join)
- reduce阶段join :容易数据倾斜
setup(Context context){ //判断数据源 FileSplit fileSplit = (FileSplit) context.getInputSplit();//文件切片信息 filename = fileSplit.getPath().getName(); } map(...){ //不同filename 输出value的数据不同 } reduce(...){ //相同key 不同value 数据join }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- map阶段join
Driver 驱动类{ //缓存小表 } mapper类 setup(Context context){ //获取缓存 } map(...){ //读大表 //join 大表-缓存 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
ETL 数据清洗
清理的过程往往只需要运行 Mapper 程序,不需要运行 Reduce 程序。
需求:筛选error日志
// 在 Map 阶段对输入的数据根据规则进行过滤清洗。 map(key,value,context){ if(不合法){ return; } //直接写出value context.write(value, NullWritable.get()); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
job.setNumReduceTasks(0); // 设置 reducetask 个数为 0- 1
YARN
为 MapReduce 提供资源管理服务 ,主要管理cpu、内存
概念
ResourceManager
管理整个集群的资源
NodeManager
管理单节点资源,每个节点上一个
ApplicationMaster
单个作业的资源管理和任务监控
Container
资源申请的单位和任务运行的容器
架构

- 在 NodeManager 创建Container 容器,在Container里运行ApplicationMaster
- ApplicationMaster向ResourceManager申请运行任务的服务器资源
- ApplicationMaster在申请的资源上创建Container,运行task任务
- task结果写入到HDFS
工作流程:MapReduce+Yarn

- 1 client提交job
job.waitForCompletion(), 产生一个YarnRunner - 2 YarnRunner 向ResourceManager申请运行应用,ResourceManager返回job路径
- 3 YarnRunner 向job路径上传资源 (Job.split切片文件,Job.xml配置文件,jar包)
- 4 YarnRunner 向ResourceManager申请运行MRAppMaster
- 5 ResourceManager 产生MrAppMaster任务,放入任务调度队列
- 6 NodeManager 从任务队列领取MRAppMaster的任务
- 7 NodeManager 创建容器,启动MRAppMaster进程
- 8 MRAppMaster 下载job资源
- 9 MRAppMaster 根据Job.split 向ResourceManager申请运行MapTask
- ResourceManager 产生MapTask任务,放入任务队列
—

- 10 NodeManager 从任务队列领取MapTask的任务, 创建容器,拷贝jar包
- 11 MRAppMaster 启动MapTask,等等MapTask执行完毕
- 12 MRAppMaster 产生ReduceTask任务 向ResourceManager申请运行;…领取任务,创建容器,执行ReduceTask
- 14 MRAppMaster 等全部完成后,向ResourceManager申请释放资源
调度器
ResourceManager 任务调度队列,任务优先级
三种作业调度器
- FIFO
- 容量(apache Hadoop3.1默认)
- 公平(CDH框架默认)
资源默认只考虑内存,DRF策略(内存+CPU 综合配比)
容量调度器
-
多队列
- 核心策略:最小占用率的任务优先执行
- 设置每个队列的最低与最多使用资源
- 多队列并发执行任务,多资源分配:空闲资源可以借给其他队列
- 单队列可选FIFO DRF,单资源分配:优先给前面的任务,有剩余资源继续分配给后面的任务(单队列并发执行任务)
-
多用户
- 设置单用户资源上限

- 资源分配流程
- 选队列 分配资源:最小占用率的任务优先执行
- 选job 分配资源:job优先级,提交时间顺序
- 选容器 分配资源:容器优先级,数据本地性原则
公平调度器
单个队列内所有任务共享资源,时间尺度公平资源
-
多队列
- 核心策略:资源缺额大的优先
- 设置每个队列的最低与最多使用资源
- 空闲资源可以借给其他队列
- 单队列可选 :FIFO DRF FAIR
-
多用户

- 资源分配流程 = 选队列,选job,选容器
是否饥饿: 实际使用份额<最小资源份额
资源配比:实际使用份额 / 最小资源份额
饥饿优先,资源配比小优先,时间顺序
使用
Web页面
查看 YARN 上运行的 Job 信息 http://ResourceManager-ip:8088- 1
- 2
命令行
# 列出所有 Application yarn application -list >>> Application-Id Application-Name Application-Type # 根据 Application 状态过滤 yarn application -list -appStates FINISHED # Kill Application: yarn application -kill <Application-Id> # 查看任务 yarn applicationattempt -list <ApplicationId> >>> ApplicationAttempt-Id State Container-Id Tracking-URL # 查看容器 yarn container -list <ApplicationAttemptId> # 查询日志 Application : yarn logs -applicationId <Application-Id> # 查询日志 Container : yarn logs -applicationId <ApplicationId> -containerId <ContainerId> # 查看节点状态 yarn node -list -all # 查看队列 yarn queue -status <QueueName>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
# 按yarn平台运行job yarn jar <jar> [mainClass] args...- 1
- 2
腾讯云EMR
新建hadoop集群,基础组件可直接使用
- Hadoop 相关软件路径在
/usr/local/service/hadoop
https://cloud.tencent.com/document/product/589/12289
-
相关阅读:
UVC 设备框架在 Linux 4.15 内核的演变
MySQL8小时连接超时断开问题
实时数据更新与Apollo:探索GraphQL订阅
UJNOJ_1287-1293-水题
《python 可视化之 matplotlib》第一章 折线图 plot
PowerDesigner 16 导入表结构与生成 Html
使用Docker安装运行RabbitMQ---阿里云服务器
一文详解爬楼梯
易点易动固定资产管理系统:高效完成固定资产盘点任务
Java本地高性能缓存实践
- 原文地址:https://blog.csdn.net/xyc1211/article/details/126607730