-
【论文阅读】Multiple Instance Learning with Emerging Novel Class
题目
Multiple Instance Learning with Emerging Novel Class
新兴类的多实例学习
2019-2-IEEE Transactions on Knowledge and Data Engineering摘要
通过应用多实例学习(MIL)算法,解决了涉及蛋白质和图像等复杂数据对象的各种应用。然而,在开放和动态的环境中,很少有MIL算法能够处理出现新类别样本的问题。在这种新兴的新型类别设置中,算法不仅要能够准确地从观察到的类别中分类出样本,而且要能够从新类别中识别出样本。
本文针对多示例学习中出现的新类别Novel class(MIEN)问题,从度量学习的角度给出了MIEN的定义。
我们从所有观察到的类中提取关键实例以形成每个观察类的 “super-bag”,并从所有观察类中提取非关键实例以形成一个“meta super-bag”。在这些超包的基础上,我们提出了一种学习判别度量的方法,用于将MIL包从观察到的类中分类出来,并从新类中识别出包。
不同领域的实验结果,例如生物功能注释、文本分类和以对象为中心/以场景为中心的图像分类,表明当新类出现时 MIEN-metric 显着优于其他基线方法。同时,MIEN-metric 与传统 MIL 设置中用于二进制分类的最先进的 MIL 算法相当。背景引入
以前对多示例学习的研究大多是在一个稳定的环境中进行的,而不是一个开放的、逐渐变化的环境。
本文中,我们主要研究新兴新类(MIEN)的多示例学习,不仅要求将包从观察到的类别中准确地分类,而且还要求从新的/增加的类别中识别包例如:
增广类识别:MIL模型来自动标注蛋白质的类别,由于突变的影响,可能会出现一些新的蛋白质类;构建以MIL图像分类系统识别大象、狐狸和鸟,但该系统必须在未来预测更多类别的图像,当一幅被标记为老虎的图像出现时,传统的MIL算法会在观察到的类之一(如Fox)中预测它;
MIEN-metric 流程:
首先在每个 MIL 包 X i X_i Xi中提取关键实例,例如使用现成的关键实例检测方法;
然后,来自每个观察类的关键实例合并到对应的超级包 S c S_c Sc, ( 1 ≤ c ≤ C 1\leq c \leq C 1≤c≤C);
所有剩余的不被认为是关键实例的实例组合成一个元超级包 S 0 S_0 S0;(超级包具有对观察类进行分类的判别能力,元超级包 用于识别增强类中的包)
度量包到超级包的距离 B 2 S B2S B2S, d 2 ( X i , S k ) , 0 ≤ k ≤ C d^2(X_i,S_k),0\leq k\leq C d2(Xi,Sk),0≤k≤C,并引入实例权重,以减轻关键实例可能无法非常准确检测的影响贡献:
第一次在MIL背景下处理新兴新类问题;
提出了MIL距离度量方法,该方法通过对MIL包学习适当的度量,得到带有排序限制的超包距离,该方法既可以从观察类中联合分类MIL包,也可以从新类中检测MIL包相关工作
增量学习:
增量学习是应对环境变化的方法的一个分支,它包括示例增量学习[19]、[20]、属性增量学习[21]、类增量学习[16]、[22]等,其中类增量学习是本文的增广类识别问题
异常检测:
新兴新类检测(增广类识别)还与异常检测相关
有新实例的多实例多标签学习:
关键实例检测(KID)算法
符号系统
符号 表示 D = { ( X 1 , y 1 ) , … , ( X i , y i ) , … , ( X N , y N ) } D=\{(X_1,y_1),\dots, (X_i,y_i),\dots, (X_N,y_N)\} D={(X1,y1),…,(Xi,yi),…,(XN,yN)} 数据集 X i = { x i 1 , … , x i n i } X_i=\{x_i^1,\dots,x_i^{n_i}\} Xi={xi1,…,xini} 包 x i j ∈ R d x_i^j \in \mathcal{R}^d xij∈Rd 实例 y i ∈ Y = { 1 , … , C } y_i \in \mathcal{Y}=\{1,\dots,C\} yi∈Y={1,…,C} 包标签 D o = { ( X i , y i ) } i = 1 ∞ D_o=\{(X_i,y_i)\}_{i=1}^{\infty} Do={(Xi,yi)}i=1∞ 开放数据集 y i ∈ Y ′ = { 1 , … , C , C + 1 , … , K } y_i \in \mathcal{Y^{'}}=\{1,\dots,C,C+1,\dots,K\} yi∈Y′={1,…,C,C+1,…,K} 包标签 f ( X i ) → y i ∈ Y ′ = { n o v e l , 1 , … , C } f(X_i) \rightarrow y_i \in \mathcal{Y^{'}}=\{novel,1,\dots,C\} f(Xi)→yi∈Y′={novel,1,…,C} 包标签 与传统的MIL不同,在测试阶段,我们需要从开放数据集中预测袋子的类别
MIEN-metric method
本文提出了通过考虑类的性质来求解MIEN,它评估了观察到的类与MIL包之间的关系。
1)包 X i X_i Xi到超级包 S k S_k Sk的距离被定义为每个关键实例与其在包中的最近邻居之间的马氏距离:

S k = [ s k 1 , … , s k V k ] S_k=[s_k^1,\dots,s_k^{V_k}] Sk=[sk1,…,skVk]
x ^ i v \hat{x}_i^v x^iv是根据欧式距离与 s k v s_k^v skv最近的实例
M k M_k Mk是 X i X_i Xi到超级包 S k S_k Sk的第 k k k个度量的学习参数2)为每个超包学习一个度量
对聚集有两个限制:
包 X i X_i Xi与其超级包( S y i S_{y_i} Syi)之间的距离应小于 X i X_i Xi与其他超级包(包括元超级包 S 0 S_0 S0)之间的距离。
X i X_i Xi与 S 0 S_0 S0之间的距离应小于 X i X_i Xi与其他超级包(除了 S y i S_{y_i} Syi)之间的距离
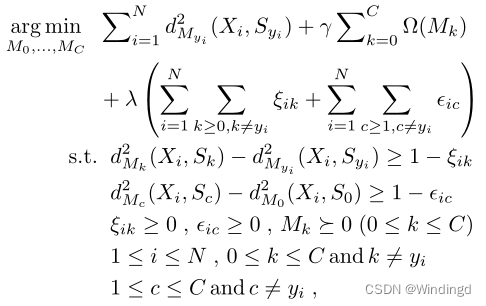
使得 d M y 1 2 ( X i , S y 1 ) d^2_{M_{y_1}}(X_i,S_{y_1}) dMy12(Xi,Sy1)为最小, d M 0 2 ( X i , S y 0 ) d^2_{M_{0}}(X_i,S_{y_0}) dM02(Xi,Sy0)位为第二小;并使用 d M 0 2 ( X i , S y 0 ) d^2_{M_{0}}(X_i,S_{y_0}) dM02(Xi,Sy0)作为中间级别,在相关和不相关的类别之间保持差距;使 S 0 S_0 S0成为拒绝选项,当一个包与现有的超包没有明显的模式时,它将接近 S 0 S_0 S0,将被认为是来自扩充类的包。MIEN-metric的学习策略
半正定规划法可直接求解最小二乘问题,计算量大,为了提高算法的有效性和效率,对B2S距离的计算进行了两点修正:
1)引入实例权重 w k \boldsymbol{w}_k wk

2)为了加快距离计算速度和降低训练成本,将度量 M k M_k Mk表示为T基的组合


重新表示MIEN的目标函数:

测试阶段:
X ∗ X_* X∗与每个超级包之间的距离。如果到某一超级包的距离最小,则为该类别;否则与 S 0 S_0 S0最接近,则该包来自一个增强类实验策略:随机选择一个类作为扩展类,其他类作为观察类
-
相关阅读:
c# 读取xml到dataset中
关于并行开发的一些概念整理【并发编程系列_1】
【HTML】表格标签,语义化
腾讯云4核8G12M带宽服务器支持多少人同时在线?
OTN的7层结构
LangChain入门:24.通过Baby AGI实现自动生成和执行任务
浅谈嵌入式系统结构和嵌入式Linux
实现高并发内存池(C++)
网页下拉菜单
Flink Batch Hash Aggregate
- 原文地址:https://blog.csdn.net/qq_43505356/article/details/126503695