-
新一代分布式实时流处理引擎Flink入门实战之先导理论篇-上
概述
定义
Apache Flink 官网 https://flink.apache.org/
Apache Flink GitHub地址 https://github.com/apache/flink
Apache Flink 官方文档地址-1.15 https://nightlies.apache.org/flink/flink-docs-release-1.15/
Apache Flink 是一个开源分布式处理引擎和框架,具有强大的流和批处理功能,用于对无界和有界数据流进行有状态的计算;Flink 能在所有常见的集群环境中运行,并能以内存速度和任意规模进行计算。最新版本1.15.1

截止至今大数据计算框架引擎大致经历以下四代:
- 第一代计算引擎:Hadoop MapReduce
- 第二代计算引擎:Tez
- 第三代计算引擎:Spark
- 第四代计算引擎:Flink
为什么使用Flink
-
流数据更真实地反映了我们的生活方式
-
传统的数据架构是基于有限数据集
-
流批计算融合
-
基于事件进行纯实时计算(连续事件),支持事件时间(event-time)和处理时间(processing-time)语义。
-
支持高吞吐、低延迟、高性能的流处理,每秒要处理数百万个事件,保证毫秒级延迟
-
支持带有事件时间的窗口 (Window) 操作
-
支持有状态计算的 Exactly-once 语义,精确一次(exactly-once)的状态保持一致性。
-
支持高度灵活的窗口 (Window) 操作,支持基于 time、count、session 以及 data-driven 的窗口操作
-
支持具有 Backpressure 功能的持续流模型
-
支持基于轻量级分布式快照(Snapshot)实现的容错
-
一个运行时同时支持 Batch on Streaming 处理和 Streaming 处理
-
Flink 在 JVM 内部实现了自己的内存管理
-
支持迭代计算
-
动态扩展,高可用,保障7*24高可用。
-
支持程序自动优化:避免特定情况下 Shuffle、排序等昂贵操作,中间结果有必要进行缓存
-
基于流的世界观:在 Flink 的世界观中,一切都是由流组成的,离线数据是有界的流;实时数据是一个没有界限的流:这就是所谓的有界流和无界流。
-
运行任意规模的应用:Flink通常把应用程序并行化数千个任务,这些任务分布在集群中并发执行。因此应用程序能够充分利用无尽的CPU、内存、磁盘和网络IO。Flink能够很方便的对应用程序的状态进行维护。其异步和增量的检查点算法仅仅会对数据延迟产生极小的影响。而且能够保证精确一次状态的一致性。
- 每天能处理数以万亿的数据
- 应用维护几TB大小的状态
- 应用在数千个内核上运行
-
利用内存进行计算:有状态的 Flink 程序针对本地状态访问进行了优化。任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。
应用行业和场景
应用行业
- 电商和市场营销:数据报表、广告投放、业务流程处理。
- 物联网行业:传感器实时数据采集和显示、显示报警、交通运输。
- 通信行业:电信、联通、移动数据分析、基站流量位置分析。
- 互联网:实时报警、热门事件新闻。
- 银行和金融行业:实时数据结算和通知推送、实时监测异常行为。
应用场景
Flink常见应用场景如下:
-
Event-driven Applications(事件驱动应用):事件可以理解为消息,事件驱动的应用程序是一种状态应用程序,它会从一个或者多个流中注入事件,通过触发计算更新状态,或外部动作对注入的事件作出响应。典型事件驱动型应用包括:
- 欺诈检测
- 异常检测
- 基于规则的告警
- 业务流程监控
- 反爬虫监控
- 社交网络、Web应用程序
下图为传统的事务应用和事件驱动应用的对比
- 程序与数据的位置:传统应用程序不要求程序和程序使用的数据位于相同的机器上,数据的位置对程序来说无关紧要【排除网络传输】,而且一般数据在远端。而事件驱动程序则要求数据本地性,这有利于数据的快速计算,特别对于大批量数据来说效果更加明显。
- 容错:传统应用程序一般不依赖容错机制,因处理逻辑链条较短且同一个程序内部并发较少,因此一般使用事务来限制数据异常。而事件驱动程序,需要7*24不间断执行,且增量计算比较常见,因此使用容错和检查点就显得尤为重要了。

- Stream & Batch Analytics:分析类工作从原始数据中提取信息和见解,批次分析是通过对记录事件的有限数据集进行批量查询或应用程序来执行的,将结果写入存储系统或以报销的形式呈现。流式分析则是批次分析的特例,即来一条数据或者一批次数据后进行查询,将结果实时写入存储系统或以报表的形式呈现。典型的应用场景包括:
- 报表或实时大屏
- 网络通信质量分析
- 产品更新分析和移动应用的性能评估
- 消费者实时数据的即席分析
- 大规模图分析
Flink支持流以及批处理分析应用程序,如下图所示:

-
Data Pipelines & ETL:提取转换加载(ETL)是在存储系统之间转换和移动数据的常用方法。通常会定期触发ETL作业,以将数据从事务数据库系统复制到分析数据库或数据仓库。数据管道的用途和ETL作业类似,它们可以转换和丰富数据,并且可以将其从一个存储系统转移到另一个存储系统,但是它们以连续模式运行,不是定期触发。因此它们能够从连续产生数据的源中读取记录,并以低延迟将其移动到目的地。例如数据管道可能会监视文件系统目录中是否有新文件,并将其数据写入事件日志,另一个应用程序可以将事件流具体化到数据库中,或者以增量方式构建和完善搜索索引。与周期性ETL作业相比,连续数据管道的明显优势是减少了将数据移至其目的地的等待时间。此外,数据管道更通用,可以用于更多用例,因为它们能够连续使用和发出数据。典型数据管道和ETL应用:
- 电商中持续ETL
- 离线或者实时数据数仓
- 电商中实时搜索索引构建
下图描述了定期ETL作业和连续数据管道之间的区别

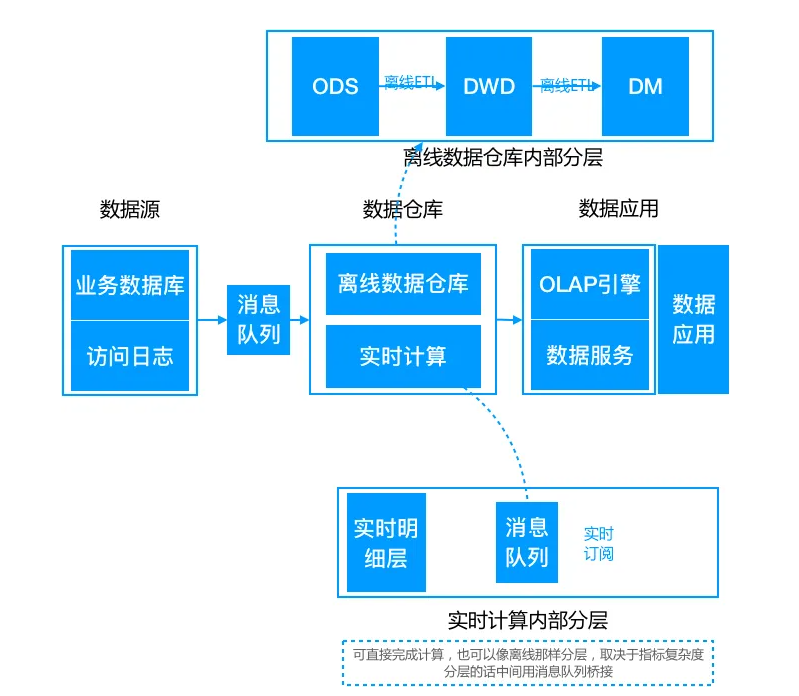
实时数仓演变
Flink也常用于离线和实时的数据仓库,下图为数仓架构的演变:

离线数据仓库架构图如下:

Lambda架构实时与离线计算融于一体
Kappa架构为Lambda架构简化版本,去掉其离线部分,Flink认为批次也是实时的特例

Flink VS Spark

- 处理机制:flink是流处理,spark streaming是微批处理,等待形成一批的时间是无可避免的延时。
- 数据模型:spark 采用 RDD 模型,spark streaming 的 DStream 实际上也就是一组 组小批数据 RDD 的集合。flink 基本数据模型是数据流,以及事件(Event)序列。
- 运行时架构:spark 是批计算,将 DAG 划分为不同的 stage,一个完成后才可以计算下一个,flink 是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理。
架构
系统架构
Flink是一个分布式系统,需要有效地分配和管理计算资源才能执行流应用程序。它集成了所有常见的集群资源管理器,如Hadoop YARN和Kubernetes,但也可以设置为作为一个独立的集群甚至作为一个库运行。一个Flink Cluster=运行时由两类进程组成总是由一个JobManager和一个或多个Flink taskmanager组成。JobManager负责Job提交的处理,Job的监督以及资源的管理。Flink任务管理器是工作进程,负责执行构成Flink作业的实际任务。可以通过客户端提交Flink作业执行各种操作任务。

-
Program Code:我们编写的 Flink 应用程序代码。
-
Job Client:Job Client 不是 Flink 运行时和程序执行的内部部分,但它是任务执行的起点。 Job Client 负责接受用户的程序代码,然后创建数据流,将数据流提交给 Job Manager 以便进一步执行。 执行完成后,Job Client 将结果返回给用户。Client用于准备数据流并向JobManager发送数据流。之后,客户端可以断开连接(分离模式),或者保持连接来接收进度报告(附加模式);客户机要么作为触发执行的Java/Scala程序的一部分运行,要么在命令行进程中运行。
-
Job Manager:主进程(也称为作业管理器)协调和管理程序的执行。 它的主要职责包括安排任务,管理 checkpoint ,故障恢复等。机器集群中至少要有一个 master,master 负责调度 task,协调 checkpoints 和容灾,高可用设置的话可以有多个 master,但要保证一个是 leader, 其他是 standby; Job Manager 包含 Actor system、Scheduler、Check pointing 三个重要的组件。
- JobManager:JobManager主要负责协调 Flink 应用程序的分布式执行,如它决定何时调度下一个 task(或一组 task)、对完成的 task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复等等。始终至少有一个 JobManager。高可用(HA)设置中可能有多个 JobManager,其中一个始终是 leader,其他的则是 standby这个进程又由三个不同的组件组成。
- Resource Manager:ResourceManager 负责 Flink 集群中的资源提供、回收、分配 -它管理 task slots(Flink 集群中资源调度的单位)。Flink 可为不同的环境和资源提供者(例如 YARN、Mesos、Kubernetes 和 standalone 部署)实现了对应的 ResourceManager。在 standalone 设置中,ResourceManager 只能分配可用 TaskManager 的 slots,而不能自行启动新的TaskManager。
- Dispatcher:Dispatcher 提供了一个 REST 接口,用来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 用来提供作业执行信息。
- JobMaster:JobMaster 负责管理单个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
-
Task Manager:从 Job Manager 处接收需要部署的 Task。Task Manager 是在 JVM 中的一个或多个线程中执行任务的工作节点。
- 任务执行的并行性由每个 Task Manager 上可用的任务槽(Slot 个数)决定。 每个任务代表分配给任务槽的一组资源。 例如,如果 Task Manager 有四个插槽,那么它将为每个插槽分配 25% 的内存。 可以在任务槽中运行一个或多个线程。 同一插槽中的线程共享相同的 JVM。
- taskmanager(也称为worker)执行数据流的任务,并缓冲和交换数据流。必须始终至少有一个TaskManager。TaskManager中最小的资源调度单位是任务槽。TaskManager上的任务槽数表示并发处理的任务数。注意,多个操作符可以在一个任务槽中执行(参见任务和操作符链)。
-
JobManager和taskmanager可以以各种方式启动:直接在机器上作为独立的集群启动,在容器中启动,或者由像YARN这样的资源框架管理。TaskManagers连接到JobManagers,宣布自己可用,并被分配工作。
术语
- Checkpoint Storage:状态后端将在检查点期间存储其快照的位置(JobManager 或文件系统的 Java 堆)。
- Flink Application Cluster:Flink Application Cluster 是一个专用的 Flink Cluster,它只执行来自一个 Flink Application 的 Flink Jobs, Flink Cluster 的生命周期与 Flink Application 的生命周期绑定。
- Flink Job Cluster:Flink Job Cluster 是一个专用的 Flink Cluster,它只执行单个 Flink Job, Flink Cluster 的生命周期与 Flink Job 的生命周期绑定;自 Flink 1.15 起,该部署模式已被弃用。
- Flink Cluster:由(通常)一个 JobManager 和一个或多个 Flink TaskManager 进程组成的分布式系统。
- Event:事件是关于应用程序建模的域状态变化的声明,事件可以是流或批处理应用程序的输入和/或输出,事件是特殊类型的记录。
- ExecutionGraph:参见物理图
- Function:函数由用户实现,封装了一个 Flink 程序的应用逻辑。大多数函数都由相应的运算符包装。
- Instance:实例用于描述运行时特定类型(通常是运算符或函数)的特定实例。由于 Apache Flink 大部分是用 Java 编写的,这对应于 Java 中 Instance 或 Object 的定义。在 Apache Flink 的上下文中,术语并行实例也经常用于强调相同 Operator 或 Function 类型的多个实例并行运行。
- Flink Application:Flink 应用程序是一个 Java 应用程序,它从 main() 方法(或通过其他方式)提交一个或多个 Flink Jobs。提交作业通常是通过在执行环境上调用 execute() 来完成的。应用程序的作业可以提交到长时间运行的 Flink 会话集群、专用的 Flink 应用程序集群或 Flink 作业集群。
- Flink Job:Flink Job 是逻辑图(也通常称为数据流图)的运行时表示,通过在 Flink 应用程序中调用 execute() 创建和提交。
- JobGraph:参见逻辑图
- Flink JobManager :JobManager 是 Flink Cluster 的编排器。它包含三个不同的组件:Flink Resource Manager、Flink Dispatcher 和每个运行的 Flink Job 一个 Flink JobMaster。
- Flink JobMaster :jobMaster 是 JobManager 中运行的组件之一。 JobMaster 负责监督单个作业的任务的执行。
- JobResultStore:JobResultStore 是一个 Flink 组件,它将全局终止(即完成、取消或失败)的作业的结果保存到文件系统,允许结果比完成的作业更有效。然后 Flink 使用这些结果来确定作业是否应该在高可用集群中进行恢复。
- Logical Graph:逻辑图是一个有向图,其中节点是算子,边定义算子的输入/输出关系,并对应于数据流或数据集。通过从 Flink 应用程序提交作业来创建逻辑图。逻辑图通常也称为数据流图。
- Managed State:Managed State 描述了已向框架注册的应用程序状态。对于托管状态,Apache Flink 将负责持久性和重新缩放等。
- Operator :逻辑图的节点,Operator 执行某种操作,通常由 Function 执行,Sources 和 Sinks 是用于数据摄取和数据输出的特殊 Operator。
- Operator Chain:一个 Operator Chain 由两个或多个连续的 Operator 组成,中间没有任何重新分区;同一 Operator Chain 内的 Operator 直接相互转发记录,无需经过序列化或 Flink 的网络堆栈。
- Partition :分区是整个数据流或数据集的独立子集。通过将每条记录分配给一个或多个分区,将数据流或数据集划分为多个分区。任务在运行时使用数据流或数据集的分区,改变数据流或数据集分区方式的转换通常称为重新分区。
- Physical Graph:物理图是翻译逻辑图以在分布式运行时执行的结果。节点是任务,边表示输入/输出关系或数据流或数据集的分区。
- Record:记录是数据集或数据流的组成元素。运算符和函数接收记录作为输入并发出记录作为输出。
- (Runtime) Execution Mode :DataStream API 程序可以以两种执行模式之一执行:BATCH 或 STREAMING。
- Flink Session Cluster:一个长时间运行的 Flink Cluster,它接受多个 Flink Jobs 来执行。这个 Flink Cluster 的生命周期不受任何 Flink Job 的生命周期的约束。以前,Flink Session Cluster 也被称为会话模式下的 Flink Cluster。对比 Flink 应用集群。
- State Backend:对于流处理程序,Flink Job 的 State Backend 决定了它的状态如何存储在每个 TaskManager 上(TaskManager 的 Java Heap 或(嵌入式)RocksDB)。
- Sub-Task :Sub-Task 是负责处理数据流的一个分区的Task,强调对于同一个算子或算子链有多个并行任务。
- Table Program:使用 Flink 的关系 API(Table API 或 SQL)声明的管道的通用术语。
- 任务:物理图的节点。任务是基本的工作单元,由 Flink 的运行时执行。任务封装了一个 Operator 或 Operator Chain 的并行实例。
- Flink TaskManager:TaskManager 是 Flink Cluster 的工作进程。任务被调度到 TaskManagers 执行。它们相互通信以在后续任务之间交换数据。
- Transformation:转换应用于一个或多个数据流或数据集,并产生一个或多个输出数据流或数据集。转换可能会基于每条记录更改数据流或数据集,但也可能仅更改其分区或执行聚合。虽然 Operators 和 Functions 是 Flink API 的“物理”部分,但 Transformations 只是一个 API 概念。具体来说,大多数转换都是由某些 Operator 实现的。
无界和有界数据
任何数据都可以形成一种事件流。银行卡(信用卡)交易、传感器测量、机器日志、网站或移动应用程序上的用户交易记录等等,所有这些数据都能形成一种流。流是数据的自然栖息地,无论是来自网络服务器的事件,股票交易所的交易,还是来自工厂车间机器的传感器读数,数据都是作为流的一部分创建的。但是分析数据时可以围绕有界流或无界流组织处理,也即是数据可以被作为无界和有界流来处理。

- 无界流 有定义流的开始,但是没有定义流的结束,会无休止地产生数据。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。涉及到无界数据流在概念上输入可能永远不会结束,因此必须在数据到达时持续处理数据。
- 有界流 有定义流的开始,也有定义流的结束。有界流所有数据可以被排序,所以并不需要有序提取。有界流通常被称为批处理。批处理是处理有界数据流时的工作模式。在这种操作模式下可以选择在产生任何结果之前拉取整个数据集,可以对数据进行排序、计算全局统计数据或生成汇总所有输入的最终报告。
Flink擅长处理无界和有界数据集 精确的时间控制和状态化使得Flink的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理。
流式分析基础
- 在Flink中,应用程序由可由用户定义的操作符转换的流数据流组成。这些数据流形成有向图,以一个或多个源开始,以一个或多个汇聚结束。

- 通常程序中的转换与数据流中的操作符之间存在一对一的对应关系,但也可以一个转换可能包含多个操作符。应用程序可以使用来自流媒体的实时数据,比如消息队列或分布式日志,比如Apache Kafka或Kinesis,flink也可以使用来自各种数据源的有限的历史数据。类似地,由Flink应用程序产生的结果流可以发送到各种各样的系统,这些系统可以作为接收器连接。

- 并行数据流:Flink中的程序本质上是并行和分布式的。在执行过程中,一个流有一个或多个流分区,每个操作符有一个或多个操作符子任务。操作符子任务彼此独立,在不同的线程中执行,可能在不同的机器或容器上执行。运算符子任务的数量是特定运算符的并行度。同一程序的不同运算符可能具有不同级别的并行性。

流可以在两个操作符之间以一对一(或转发)的模式传输数据,也可以采用重分发模式:
- **One-to-one **Stream:一对一的流(例如上图中的Source和map()操作符之间)保留元素的分区和排序。这意味着map()操作符的子任务[1]将看到与Source操作符的子任务[1]产生的相同顺序的相同元素。
- Redistributing streams:重新分配流:(如上面的map()和keyBy/window之间,以及keyBy/window和Sink之间)会改变流的分区。每个操作符子任务将数据发送到不同的目标子任务,具体取决于所选择的转换。例如keyBy()(通过哈希键重新分区),broadcast(),或rebalance()(随机重新分区)。在重分配交换中,元素之间的顺序只保留在每对发送和接收子任务中(例如map()的子任务[1]和keyBy/window的子任务[2])。因此如上面所示的keyBy/window和Sink操作符之间的重新分配引入了关于不同键的聚合结果到达Sink的顺序的不确定性。
Flink能够通过状态快照和流重放的组合提供容错、恰好一次的语义。这些快照捕获分布式管道的整个状态,将偏移量记录到输入队列中,以及在整个作业图中由于吸收了该点之前的数据而产生的状态。当发生故障时,重新绕线源,恢复状态,恢复处理;状态快照是异步捕获的,不会妨碍正在进行的处理。
分层API
Flink为开发流/批处理应用程序提供了不同级别的抽象:越顶层越抽象,表达含义越简明,使用越方便;越底层越具体,表达能力越丰富,使用越灵活。

- 最低层次的抽象只提供有状态和及时的流处理。它通过进程函数嵌入到DataStream API中。它允许用户自由地处理来自一个或多个流的事件,并提供一致的容错状态。此外,用户还可以注册事件时间和处理时间回调,使程序能够实现复杂的计算。
- ProcessFunction:ProcessFunction是一个低阶的流处理操作,它可以访问流处理程序的基础构建模块:
- 事件(event):流元素。
- 状态(state):容错性,一致性,仅在keyed stream中。
- 定时器(timers):event time和processing time, 仅在keyed stream中。
- ProcessFunction:ProcessFunction是一个低阶的流处理操作,它可以访问流处理程序的基础构建模块:
- DataStream API(有界/无界流)和DataSet API(有界数据集):在实践中许多应用程序不需要上面描述的低级抽象,而是可以针对核心API编程:这一层API为数据处理提供了通用的构建块,比如各种形式的用户指定的转换、连接、聚合、窗口、状态等。在这些api中处理的数据类型表示为各自编程语言中的类。低级的Process Function与DataStream API集成,使其能够在需要的基础上使用低级抽象。DataSet API为有界数据集提供了额外的原语,比如循环/迭代。Flink中的DataStream程序是对数据流进行转换的常规程序(例如,过滤,更新状态,定义窗口,聚合)。数据流的最初的源可以从各种来源(例如,消息队列,套接字流,文件)创建,并通过sink返回结果,例如可以将数据写入文件或标准输出。Flink程序以各种上下文运行,独立或嵌入其他程序中。执行可能发生在本地JVM或许多机器的集群上。
- Table API :Table API 是一个以表为中心的声明式DSL,可以动态地改变表(当表示流时)。Table API遵循(扩展的)关系模型:表有一个附加的模式(类似于关系数据库中的表),该API提供类似的操作,如选择、项目、连接、组by、聚合等。表API程序声明性地定义应该执行哪些逻辑操作,而不是确切地指定操作代码的外观。虽然Table API可以通过各种类型的用户定义函数进行扩展,但它不够明确。可以在表和数据流/数据集之间无缝转换,允许程序将表API与数据流和数据集API混合使用。
- SQL:Flink SQL 是基于 Apache Calcite 来实现的标准 SQ,Flink提供的最高级别抽象是SQL。这种抽象在语义和表达方面与Table API相似,但将程序表示为SQL查询表达式。SQL抽象与表API密切交互,并且可以在表API中定义的表上执行SQL查询。
运行模式
Flink作业提交模式又可分为:
- Detached:Flink Client 创建完集群之后,可以退出命令行窗口,集群独立运行。
- Attached:不能关闭命令行窗口,需要与集群之间维持连接。
Flink Job部署方式包括session(会话)模式、Per-Job(分离)模式和Application(应用)模式;而Flink on Yarn都支持这三种部署方式:
- session(会话)模式:适用于有大量小作业的场景,即多个作业共享资源。
- 使用Flink中的Yarn-session(yarn客户端),会启动两个必要的服务JobManager和TaskManager。客户端通过yarn-session提交作业,yarn-session会一直启动,不停地接收客户端提交的作业,有大量的小作业适合使用这种方式。
- 在session模式下,集群中的所有作业只有一个JobManager,Job 被随机分配给TaskManager。
- Per-Job(分离)模式:适用大作业的场景,即一个作业需要长期独占占据资源;
- 直接提交任务给YARN,大作业的场景,使用这种方式。每个Job都有一个JobManager,每个TaskManager只有单个Job。
- Application(应用)模式:适用于一个应用包括多个作业(Job)的场景,实现了更加轻量级的可扩展的作业提交流程,将客户端负载均衡转移到了每个应用程序的JobManager,节省提交作业时要准备资源的时间,可以将资源提前准备好,如将jar包先存储到HDFS上。
- 部署服务是一个消耗资源比较大的服务,并且很难计算出实际资源限制,Flink 1.11 引入了另外一种部署选项 Application Mode, 该模式允许更加轻量级,可扩展的应用提交进程,将之前客户端的应用部署能力均匀分散到集群的每个节点上。由于每个应用程序有一个JobManager,因此可以更平均地分散网络负载。Application 模式允许提交由多个Job组成的应用程序。Job执行的顺序受启动Job的调用的影响不受部署模式的影响。
作业提交流程
顶层抽象流程

上图为 Flink 的提交高层级抽象流程,随着部署模式、资源管理平台的不同,会有不同,具体步骤如下:
- 由客户端(App)通过分发器提供的 REST 接口,将作业提交给JobManager。
- 由分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
- JobMaster 将 JobGraph 解析为可执行的 ExecutionGraph,得到所需的资源数量,然后向资源管理器请求资源(slots)。
- 资源管理器判断当前是否由足够的可用资源;如果没有,启动新的 TaskManager。
- TaskManager 启动之后,向 ResourceManager 注册自己的可用任务槽(slots)。
- 资源管理器通知 TaskManager 为新的作业提供 slots。
- TaskManager 连接到对应的 JobMaster,提供 slots。
- JobMaster 将需要执行的任务分发给 TaskManager。
- TaskManager 执行任务,互相之间可以交换数据。
如果部署模式不同,或者集群环境不同(例如 Standalone、YARN、K8S 等),其中一些步 骤可能会不同或被省略,也可能有些组件会运行在同一个 JVM 进程中。比如独立集群环境的会话模式,就是需要先启动集群,如果资源不够,只能等待资源释放, 而不会直接启动新的 TaskManager。
基于Yarn 会话(Session)模式
在会话模式下,我们需要先启动一个YARN session,这个会话会创建一个 Flink 集群。 这里只启动了 JobManager,而 TaskManager 可以根据需要动态地启动。在 JobManager 内部由于还没有提交作业,所以只有 ResourceManager 和 Dispatcher 在运行,如图所示。

接下来就是真正提交作业的流程,如图所示:

- 客户端通过 REST 接口,将作业提交给分发器。
- 分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
- JobMaster 向资源管理器请求资源(slots)。
- 资源管理器向 YARN 的资源管理器请求 container 资源。
- YARN 启动新的 TaskManager 容器。
- TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
- 资源管理器通知 TaskManager 为新的作业提供 slots。
- TaskManager 连接到对应的 JobMaster,提供 slots。
- JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
**本人博客网站 **IT小神 www.itxiaoshen.com
-
相关阅读:
java毕业设计选题二手车汽车车辆管理系统项目[包运行成功]
导轨式工业交换机的安装方式
Java 获得applet参数学习笔记
Python基础知识入门(三)
Anaconda彻底卸载及重安装
算法:最长递增子序列
离散数学 学习 之 5.3 一阶逻辑的推理理论
jedis的minIdle和maxIdle参数
Codeforces Round #820 (Div. 3) B Decode String
一文带你了解ServletContext
- 原文地址:https://blog.csdn.net/qq_20949471/article/details/126433257