-
使用移动平均数调整曲线 by Python
声明:
本文所使用的数据均已经过脱敏处理,行业与流量均为随机虚构数据。
一、业务场景背景
网站即将开放商家页面的访问数据给各个商家查看,但有的表现极差的商家的数据存在以下几种情况:
1、部分商家在所选取的时间范围内无访问流量

2、部分商家在所选取的时间范围内只有零散流量,曲线不连续

3、部分商家在所选取的时间范围内有连续流量,但流量值很低
对此,业务侧提出以下需求(不要让展示数据太难看):
- 使用相对值进行分数展示
- 无访问流量的商家数据需要有数据曲线
- 数据零散曲线不连贯的商家数据需要有平滑的曲线
- 流量值低的数据需要进行抬升
二、计算原理
简单来说,就是在商家原始值的基础上,通过加入不同权重的指标(商家自身流量的移动平均数和商家所处的行业流量数据的移动平均数)来消除数据随机波动,平滑并抬升曲线。
1、商家流量移动平均数
如果商家在所挑选的窗口期(如过去7天/过去14天/过去30天)存在历史数据则计算商家的移动平均数。若无历史数据则跳过此加权项。使用商家的移动平均数加权可以消除商家数据的随机波动,使商家的数值曲线与历史数据波动保持一致。
移动平均数=选定时间范围内的历史数据的平均数。
例如,现有某商家10天的访问流量,计算窗口期为3天的商家访问流量移动平均数:
第3天的移动平均数
MA=(D1+D2+D3)/3=(2+1+4)/3=2.3
第4天的移动平均数
MA=(D2+D3+D4)/3=(1+4+3)/3=2.7

2、供应商所属行业的移动平均数
因为有的商家经营实在惨淡,历史数据也难以入眼,为使曲线符合行业波动趋势,加入商家所属行业的移动平均数。计算方式同上。
3、计算3个Z分数
(1)商家访问流量的Z分数
(2)商家移动平均数的Z分数
(3)商家所属行业的移动平均数Z分数
z=(商家每天数值-所有商家均值)/所有商家的标准差
计算出商家的3个指标绝对值变为标准化的相对值Z分数
4、使用Min-max计算3个基础分数S(Score)
将原始数据变换为Z分数后,并不会对原数据分布进行改变。尽管惨淡经营的商家数据已经转换为相对值,曲线本身仍然能透露出惨淡的味道。所以在转化Z分数之后,进行一次线性变换,将数据压缩在一起,减小极端值对分布的影响。
基础分数S(Score)的计算公式为:St=(Xt-Mint)/(Maxt-Mint)
3个基础分数通过上述3个Z分数计算出来。
5、分配权重后得到最终分数
为3个基础分数分配不同权重x1, x2, x3,最终流量T= (x1*s1+ x2*s2+ x3*s3)
三、算法实现
1、观察原始数据
提取时间周期为【2022-6-24】-【2022-07-04】的数据进行观察。


可以看出来,如果商家在某一天没有流量,不会留下数据记录,这对我们进行移动平均数计算存在阻碍,所以需要复原流量为0的数据。
2、复原流量为0的数据思路
1)创建n个表an,n为商家数量,每个表中只有一个商家,日期列显示每一天,无流量的Traffic为0
例如:

2)合并所有的an表,得到表b

3)取出去重的行业作为行业表,与表b进行关联,得到完成复原的表c

2、代码开始,复原流量为0数据
- import pandas as pd
- import numpy as np
- import datetime
- import warnings
- warnings.filterwarnings('ignore')
- file='xxx/data.csv'
- data= pd.read_csv(file)
- #因为日期是object格式,转化为时间戳才能计算最大值最小值
- data['Date']=pd.to_datetime(data['Date'])
- data["Organisation Id"]=data["Organisation Id"].astype('str')
- date_start=data['Date'].min()
- date_end=data['Date'].max()
- #Timedelta在pandas中是一个表示两个datetime值之间的差(如日,秒和微妙)的类型,所以需要加上days
- date_range=(date_end-date_start).days
- #unique去除该列的重复值,unique()方法得到的对象是numpy.ndarray类型,调用tolist方法转换为列表,便于我们进行循环
- org_list=pd.unique(data['Organisation Id']).tolist()
- #table_a暂时存储每一个商家的id&日期,这样才不会遗漏任何一个日期
- table_a=pd.DataFrame()
- #table_b用来合并所有的table_a
- table_b=pd.DataFrame()
- for org_id in org_list:
- table_a["Organisation Id"]=org_id
- #如果不将格式转化为object的话,会默认为float
- table_a["Organisation Id"]=table_a["Organisation Id"].astype('str')
- table_a["Date"]=pd.date_range(date_start,date_end)
- table_b=table_b.append(table_a,ignore_index=True)
- #drop all rows that have any NaN values
- table_b=table_b.dropna(axis=0,how='any')
- #industry用来存储商家的行业
- industry=data[['Organisation Id','Industry']]
- industry=industry.drop_duplicates()
- table_c = pd.merge(table_b,industry,on = 'Organisation Id', how='left')
- table_d= pd.merge(data.drop(['Industry'], axis=1),table_c, on = ['Organisation Id','Date'],how='right')
- table_d=table_d.sort_values(by=['Organisation Id','Date'])
- #重置index并删除原来的index
- table_d=table_d.reset_index()
- table_d=table_d.drop(['index'],axis=1)
- #填充NaN值为0
- table_d=table_d.fillna(0)
经过上面的操作之后得到了table_d
print(table_d)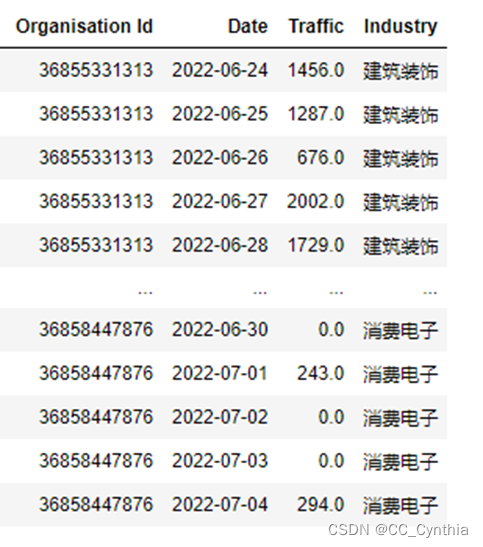
3、计算每个商家的移动平均数MA
这里的移动平均数选择过去7天作为窗口期,得到table_e。
- #*************************************************
- #下面计算商家MA
- #MA_a存储每一个商家的移动平均数
- MA_a=pd.DataFrame()
- #MA_b合并所有MA_a
- MA_b=pd.DataFrame()
- for org_id in org_list:
- MA_a=table_d[table_d['Organisation Id']==org_id]
- #取出的数值带小数点
- MA_a["Org_ma"]=table_d[table_d['Organisation Id']==org_id]['Traffic'].rolling(7).mean().round(2)
- MA_b=MA_b.append(MA_a,ignore_index=True)
- table_e=MA_b.fillna(0)
print(table_e)

4、计算行业的MA
同样也是以7天作为窗口期
- #*************************************************
- #下面计算行业MA
- #创建industry_list方便我们进行循环
- industry_list=pd.unique(data['Industry']).tolist()
- #按照行业进行每一天的traffic汇总
- industry_a=table_e.groupby(['Industry','Date']).sum().reset_index()
- industry_a=industry_a.drop(['Org_ma'],axis=1)
- industry_a=industry_a.fillna(0)
- #industry_b存储每一个行业的移动平均数
- industry_b=pd.DataFrame()
- #industry_c合并所有的数据
- industry_c=pd.DataFrame()
- for ind_id in industry_list:
- industry_b=industry_a[industry_a['Industry']==ind_id]
- industry_b["Ind_ma"]=industry_a[industry_a['Industry']==ind_id]['Traffic'].rolling(7).mean().round(2)
- industry_c=industry_c.append(industry_b,ignore_index=True)
- industry_c=industry_c.fillna(0)
- industry_c=industry_c.drop(['Traffic'],axis=1)
- #最终得到一个带有商家移动平均数与行业移动平均数的table_f
- table_f = pd.merge(table_e,industry_c,on =['Industry','Date'] , how='left')
最终得到一个带有商家MA与行业MA的table_f
Print(table_f)

6、计算得分
- #计算table_f的Z分数
- table_f['Traffic_Zscore'] = (table_f['Traffic'] - table_f['Traffic'].mean())/table_f['Traffic'].std(ddof=0)
- table_f['Org_ma_Zscore'] = (table_f['Org_ma'] - table_f['Org_ma'].mean())/table_f['Org_ma'].std(ddof=0)
- table_f['Ind_ma_Zscore'] = (table_f['Ind_ma'] - table_f['Ind_ma'].mean())/table_f['Ind_ma'].std(ddof=0)
- #计算3个Z分数的Min-max分值S
- table_f['Traffic_Score']=(table_f['Traffic_Zscore']-table_f['Traffic_Zscore'].min())/(table_f['Traffic_Zscore'].max()-table_f['Traffic_Zscore'].min())
- table_f['Org_ma_Score']=(table_f['Org_ma_Zscore']-table_f['Org_ma_Zscore'].min())/(table_f['Org_ma_Zscore'].max()-table_f['Org_ma_Zscore'].min())
- table_f['Ind_ma_Score']=(table_f['Ind_ma_Zscore']-table_f['Ind_ma_Zscore'].min())/(table_f['Ind_ma_Zscore'].max()-table_f['Ind_ma_Zscore'].min())
- #计算最终得分,权重分配看心情
- table_f['Total_Score']=((0.2*table_f['Org_ma_Score']+0.1*table_f['Ind_ma_Score']+0.7*table_f['Traffic_Score'])*1000).round(0)
- #存储
- table_f.to_csv('xxxx/data_total_score.csv',encoding='utf_8_sig',index=False)

四、结果与优化建议
1、6月24日作为数据起始点,在窗口7天的情况下,6月24日至6月29日的Total_score没有行业MA与商家MA的得分加权。
1)当Traffic为0的情况下,整体得分为0

2)当Traffic不为0的情况下,整体得分偏低

失去了加权的得分比加权得分低太多
3)建议
姑且将6月24日至6月29日这些用来计算MA的数据成为窗口期数据吧,这些窗口期数据不能与加权优化后的数据放在一起,不然会出现戏剧提升比如下图中的商家:


2、去除窗口期数据观察低流量商家
1)通过加权之后原始流量为0的商家也有一条看着流量分值不低的平缓曲线了
当然,如果需要差异比较大,那么可以适当调高Traffic分数的权重,并放大最后乘以的系数1000。

2)当2个商家的原始流量为0,不同行业的得分也不相同

3)建议
①对于B2B平台而言,用户访问频率比较低,只取过去7天并不能很好的代表商家的过去流量,窗口期可以拉长到过去1个月;
②行业的MA并不一定要按照最大类进行计算,如果需要细分行业的差别,那么就将行业的定义缩小一些,选择更贴近商家的类目;
③可以考虑使用T分数替代Z分数,因为Z分数之后的Min-Max标准化分数会将负数Z转化为0,从而降低加权效果。
这部分数据我也会放到我的微信公众号(BXH_data)上,后台回复【移动平均数调整曲线】即可获得。
-
相关阅读:
JUC源码学习笔记4——原子类,CAS,Volatile内存屏障,缓存伪共享与UnSafe相关方法
【计算机视觉】图片文件格式的讲解
Mysql数据库 ---高级操作
2.2 IOC之基于XML管理bean
【逆向】通过新增节移动导出表和重定位表(附完整代码,直接可运行)
计算机基础知识35
如何理解vue声明式渲染
408王道操作系统强化——PV大题解构
ElasticSearch认识及安装
牛客网刷题-(6)
- 原文地址:https://blog.csdn.net/CC_Cynthia/article/details/126387843
