-
MySQL之分库分表
- 为什么要分库分表
- 用户请求量太大
- 单服务器TPS、内存、IO都是有上限的,需要将请求打散分布到多个服务器
- 单库数据量太大
- 单库处理能力有限;单库所在服务器的磁盘空间有限;单库的操作IO有瓶颈
- 单表数据量太大
查询、插入、更新操作都会变慢;加字段、加索引、机器迁移都会产生高负载、影响服务
- 用户请求量太大
- 如何解决
- 垂直拆分
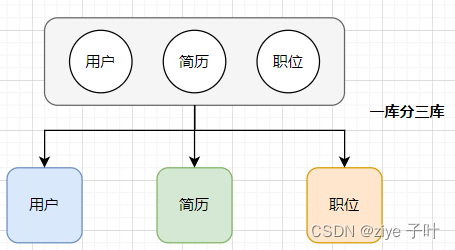
- 垂直分库
微服务架构,业务切割的足够独立,数据也会按照业务切分,保证业务数据隔离,大大提升了数据库的吞吐能力。
- 垂直分表
表中字段太多切包含大字段的时候,在查询是对数据库的IO、内存会受到影响,同时更新数据时,产生的binlog文件会很大,MySQL在主从同步时也会有延迟的风险。
在这里插入图片描述
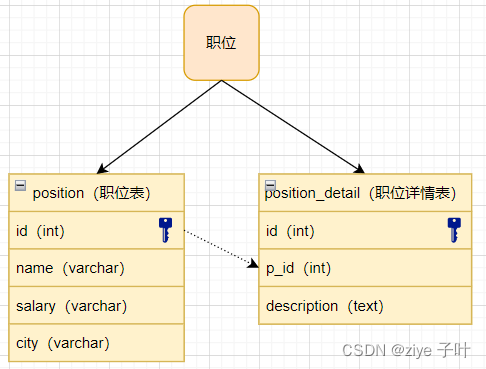
- 垂直分库
- 水平拆分
-
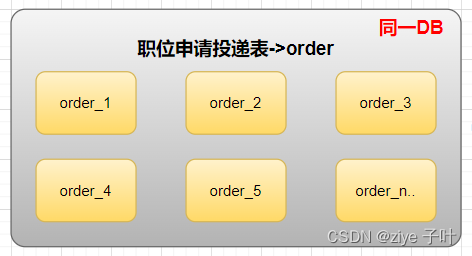
水平分表
针对数据量巨大的单张表(如职位申请投递表,order),按照规则把一张表的数据切分到多张表里面去。但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈的。
-
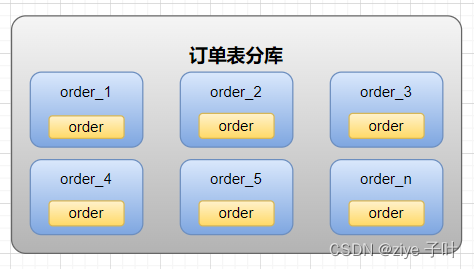
水平分库
将单张表的数据切分到多个服务器上,每个服务器具有响应的库与表,只是表中数据集合不同。水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬盘资源等瓶颈。
-
水平分库规则:
数据获取时,不跨库、不跨表,保证同一类数据都在同一个服务器上获取。 -
水平分表规则:
- RANGE(范围)
时间:按照年、月、日切分。如 order_2022、order_202208、order_20220801
地域:按照省或市切分。如 order_beijing
大小:从0到100万一个表。 - HASH(哈希)
用户ID取模 - 不同的业务使用的切分规则是不一样的,根据上面提到的切分规则,举例如下:
- 站内信:
- 用户维度:用户只能看到发送给自己的信息,其他用户是不可见的,这种情况下是按照拥堵ID hash分库,在用户查看历史记录翻页查询时,所有的查询请求都在同一个库内。
- 用户表:
- 范围法:以用户ID未划分依据,将数据水平切分到两个数据库实例,如:1到1000万在一张表1000万到2000万在一张表,这种情况会出现单表的负载较高。
- 按照用户ID hash尽量保证用户数据均衡分到数据库中。
- 流水表:
- 时间维度:可以根据每天新增的流水来判断,选择按照年份分库,还是按照月份分库,甚至也可以按照日期分库。
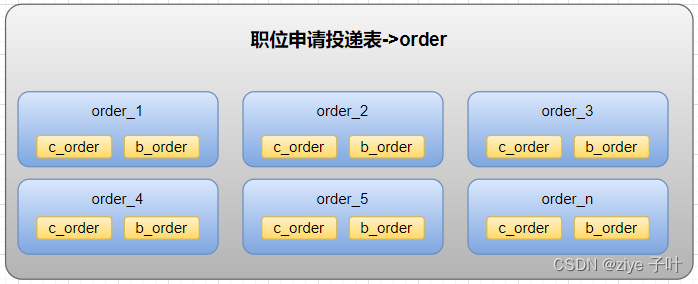
- 职位申请投递表->订单表:
求职者(C端)投递企业(B端)的职位产生的记录称之为订单表。在线上的业务场景中,C端用户看自己的投递记录,可以看到每次的投递到了哪个状态;B端用户查看自己收到的简历,对于合适的简历会进行下一步沟通,同一个公司内的员工可以协作处理简历。
为了同时满足C端和B端用户的业务场景,采用空间换时间,将一次的投递记录存为两份,C端的投递记录以用户ID为分片键,B端收到的简历按照公司ID为分片键。
- 主键选择:
分库分表继续使用主键自增,容易导致主键重复。- UUID:本地生成,不依赖数据库,缺点是因为太长和无序性导致索引树经常变更导致的性能太差。不推荐
- SNOWFLAKE:百度的UidGenerator、美团的Leaf,都是基于SNOWFLAKE算法实现的。
- 数据一致性:
- 强一致性:XA协议 -> 并发能力差
- 最终一致性:TCC、saga、Seata -> 并发能力强
- 数据库扩容:
- 成倍增加数据节点,基于平滑扩容 -> 2变4;4变8,8变16…
- 成倍扩容后,表中的部分数据请求已被路由到其他节点上,可以清除。
- 业务层改造:
- 基于代理层方式:MyCat、Sharding-Proxy、MySQL Proxy -> 只需指定一个连接池
- 基于应用层方式:Shardding-jdbc -> 需指定多个连接池
- 分库后面临的问题:
- 事务问题:一次投递需要插入两条记录,且分布在不同的服务器上,数据需保证一致性。
- 跨库跨表的join问题
- 全局表(字典表):基础数据,所有库都拷贝一份。
- 字段冗余:字段少可以使用字段冗余,就不用join查询。
- 系统层组装:可以在业务层分别查询出来,然后组装起来,逻辑较复杂。
- 额外的数据管理负担和数据运算压力:数据库扩容、维护成本变高。
- 站内信:
- RANGE(范围)
-
- 垂直拆分
其他章节 -> 跳转
end...- 1
- 为什么要分库分表
-
相关阅读:
equals和==的区别你真的知道吗?
relational learning关系学习
Google Play如何做ASO优化?影响搜索排名的主要因素.
Appium问题及解决:打开Appium可视化界面,点击搜索按钮,提示inspectormoved
一万小时真的能成为专家吗?
Go语言——快速使用Markdown解析库
羊了个羊通关秘籍
[计算机提升] 文件的创建与删除原理
html+css鼠标悬停发光按钮![HTML鼠标悬停的代码]使用HTML + CSS实现鼠标悬停的一些奇幻效果!
隐私计算FATE-离线预测
- 原文地址:https://blog.csdn.net/weixin_45881674/article/details/126308819