-
神经网络(一)基本概念
一、概率论基本概念
①概率:随机事件发生的可能性大小,介于0-1之间
②随机变量:可能发生的事件,称为X
③概率分布:一个随机变量X取每种可能值的概率(总和为1)
④离散随机变量:
伯努利分布:X为事件A出现的次数,事件A发生的概率为μ,不发生的概率为1-μ
分布公式为:

二项分布:n次伯努利分布中,X表示A出现的次数,
分布公式为:
 , k=1...,n
, k=1...,n⑤连续随机变量:一般采用概率密度函数来描述

高斯分布:


⑥累积分布函数:随机变量X的取值小于等于x的概率
cdf(x) = P(X≤x)

⑦随机向量:一组随机变量构成的向量
联合概率分布:

条件概率:对于离散随机向量(X,Y),已知X=x时,Y=y的条件概率

⑧采样:给定一个概率分布p(x),生成满足条件的样本
如何进行采样
1.直接采样:均匀分布->线性同余发生器:

2.间接采样:仅均匀分布能直接采样,其他的都是通过间接采样
⑨期望:随机变量的均值
离散变量:
![E[X]=\sum_{n=1}^{N}x_np(x_n)](https://1000bd.com/contentImg/2022/08/18/033714745.gif)
连续随机变量:
![E[X]=\int_{R}^{}xp(x)dx](https://1000bd.com/contentImg/2022/08/18/033715816.gif)
⑩大数定律:样本数量很大的时候,样本均值和真实均值(期望)充分接近
二、机器学习的定义
通过算法使机器从大量数据中学习规律从而对新的样本做决策

三、机器学习的类型
1.监督学习
包含了回归问题(连续)和分类问题(离散)

2.无监督学习
包含三种方法类聚、降维、密度估计

3.强化学习
通过与环境的交互来进行学习(例如阿尔法狗),属于无监督学习
4.总结

四、机器学习的要素
机器学习的四要素:数据、模型、学习准则、优化算法
1.模型


2.学习准则
好的模型在所有取值上应与真实映射函数一致

损失函数:非负的实数函数,用以量化模型预测和真实标签之间的差异
以回归问题为例:平方损失函数

期望风险:损失函数在真实数据分布下的期望
![R(\theta )=E_{(x,y)~p_r(x,y)}[L(y,f(x;\theta))]](https://1000bd.com/contentImg/2022/08/18/033719471.gif)
由大数定律可知,在N区域无穷时,期望风险可以近似为经验风险
经验风险:由训练数据推算而来

机器学习目的是寻找参数 ,使得经验风险函数最小化
,使得经验风险函数最小化3.优化算法
机器学习问题通过经验风险转变为一个最优化问题
①导数法:令函数一阶导=0,求极值点
②梯度下降法:是一种迭代算法

搜索步长α也可称为学习率
学习率为一种超参数,需要人工选择。学习率的选择极为重要,不能过大/过小

②-1:随机梯度下降法:在每次迭代时只采集一个样本,当经过足够次数的迭代时,也可以收敛到一个局部最优解。
优点:每次计算开销小,支持在线学习
缺点:无法充分利用计算机的并行算法
②-2:小批量随机梯度下降法:随机选取一小部分训练样本来计算梯度并更新参数
五、泛化和正则化
机器学习拟合中可能出现的问题:欠拟合、过拟合

机器学习≠优化(期望风险≠经验风险)
1.泛化误差
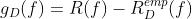 (期望风险和经验风险的差值)
(期望风险和经验风险的差值)2.正则化
降低模型复杂度以减少泛化误差
所有损害优化的方法
如:增加约束(L1/L2优化、数据增强)
干扰优化过程(权重衰减、随机梯度下降、提前停止)
提前停止:使用一个验证集,每次迭代后使用参数在验证集上进行测试,如错误率不再下降则停止迭代

-
相关阅读:
python 打包可执行文件-pyinstaller详解
Siddhi cep
【Overload游戏引擎细节分析】视图投影矩阵计算与摄像机
小米路由器青春版R1CL刷入OpenWrt
create-react-app创建Electron应用,打包
DM3730 uboot 分析
Stable Diffusion插件(翻译)
加密货币熊市导致收入骤降,穆迪将Coinbase降级
Java实现桥接模式(设计模式 五)
Redis内存回收
- 原文地址:https://blog.csdn.net/weixin_37878740/article/details/126340642