-
1.1) Hadoop单机环境安装与部署测试服务器免密登录
1.准备工作
1.1准备三台服务,我这边目前已经准备好啦。

我这边配置了三台服务器ip分别是
192.168.10.51
192.168.10.52
192.168.10.531.2配置workers(这个必须配)
现在51服务器配置
vim /etc/hosts

配置完ping 下自己配置的域名解析对的话就对了。

1.3脚本分发配置
cd /root/bin #在目录下执行 vim xsync #!/bin/bash #1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in 192.168.10.51 192.168.10.52 192.168.10.53 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
脚本赋值权限
chmod +x xsync 查看下自己环境变量 echo $PATH- 1
- 2
- 3

我是把脚本文件丢掉了root/bin下面自己配也可以
然后在每台服务器执行yum install rsync
然后在/opt/model/hadoop-3.1.3/etc
执行xsync hadoop/- 1
2.1安装hadoop
在/opt/下创建两个目录
mkdir model mkdir software- 1
- 2
2.2把需要的软件拉到software上

2.1 解压jdk
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/model
解压之后记住这个解压到的目录地址/opt/model/jdk1.8.0_212
cd /etc/profile.d/
vim my_env.sh#JAVA_HOME export JAVA_HOME=/opt/model/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin- 1
- 2
- 3
执行这个
source /etc/profile3.1解压hadoop
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/model
同上把hadoop的环境变量配到刚刚2.1里面的my_env.sh里面#JAVA_HOME export JAVA_HOME=/opt/model/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin #HADOOP_HOME export HADOOP_HOME=/opt/model/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
执行这个
source /etc/profile
然后执行hadoop 出现这个表示已经配置好拉。

2.Hadoop目录结构

最常用的目录/bin /etc /sbin2.1 hadoop的常见三种部署模式
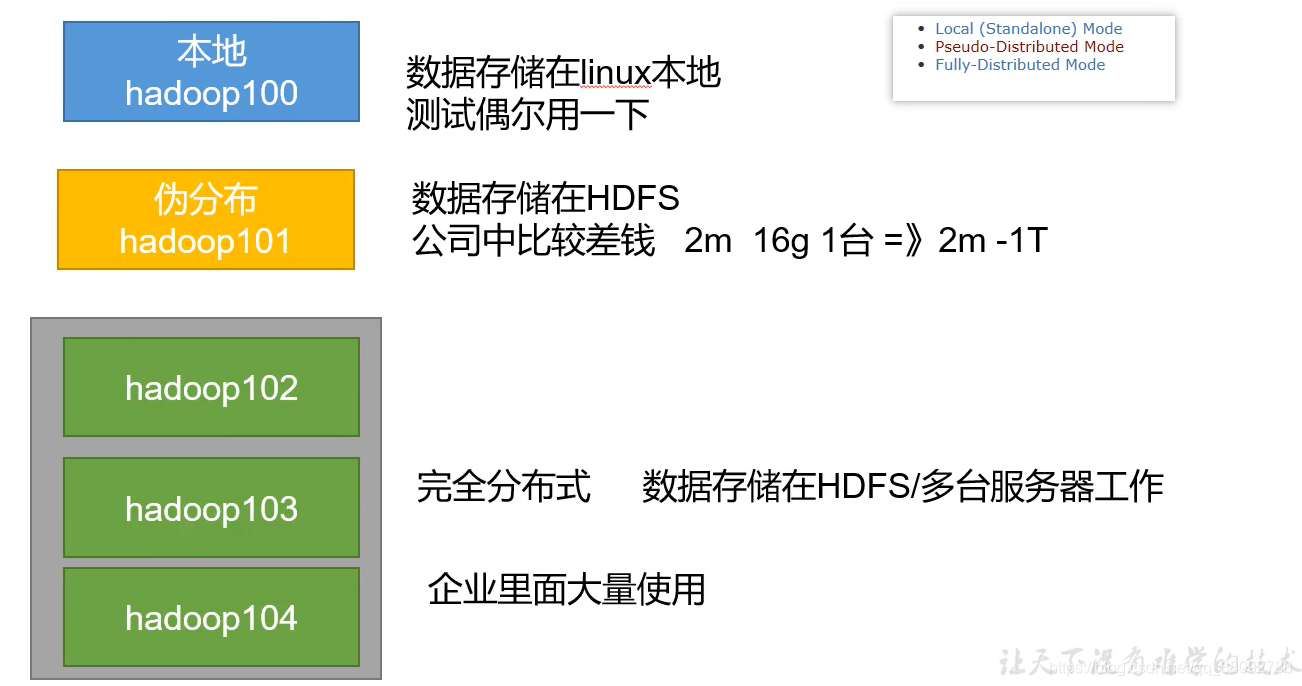
2.2 hadoop单机测试
首先在hadoop目录下面创建一个文件夹
wciput输入目录
在里面创建一个word.txt随便 写点内容
然后执行# 运行jar 这个是指定jar所在的地址 wordcount 指定jar包中方法 ../wcinput/ 这个是统计文件输入路径 ../wcoutput输入路径(输入路径不能存在,存在会报错) hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount ../wcinput/ ../wcoutput- 1
- 2
执行完之后打开输入路径
/opt/model/hadoop-3.1.3/wcoutput

里面会有两个文件 _SUCCESS是空就是一个标识 统计的文件是在part-r-00000里面我们打开part-r-00000

统计出个单词出现的数量3.服务器免密登录配置
3.1免密登录原理

3.2公钥私钥生成
cd ~ ls -la cd .ssh/ ssh-keygen -t rsa- 1
- 2
- 3
- 4

生成的私钥 公钥类似于git 配置里面的

#把公钥拷贝过去 第一次需要输入密码 ssh-copy-id 192.168.10.52 #ssh 然后就不需要密码拉 ssh 192.168.10.52- 1
- 2
- 3
- 4
各个机器都要copy一份不然后期用脚本启动yarn 的时候会启动不起来 hadoop51 hadoop52 hadoop53 都生成一个密钥拷贝到相应机器上
-
相关阅读:
吴恩达机器学习-可选实验:使用ScikitLearn进行线性回归(Linear Regression using Scikit-Learn)
Java--MybatisPlus Wrapper构造器;分页;MP代码生成器(四)
设计模式学习笔记 - 规范与重构 - 1.什么情况下要重构?重构什么?又该如何重构?
数据湖还没玩明白,就别想着湖仓一体了! by 傅一平
Django 做migrations时出错,解决方案
【C++】map和set的封装
【重识云原生】第六章容器6.1.7.2节——cgroups原理剖析
模板的特化(具体化)
Java终止线程的三种方式
关闭mysql,关闭redis服务
- 原文地址:https://blog.csdn.net/m0_52789121/article/details/126325322