-
最小均方算法(lsm)-python代码实现
最小均方算法(lsm)-python代码实现
算法简述:
最小均方算法,简称LMS算法,是一种最陡下降算法的改进算法, 是在维纳滤波理论上运用速下降法后的优化延伸,最早是由 Widrow 和 Hoff 提出来的。 该算法不需要已知输入信号和期望信号的统计特征,“当前时刻”的权系数是通过“上一 时刻”权系数再加上一个负均方误差梯度的比例项求得。 其具有计算复杂程度低、在信号为平稳信号的环境中收敛性好、其期望值无偏地收敛到维纳解和利用有限精度实现算法时的平稳性等特性,使LMS算法成为自适应算法中稳定性最好、应用最广的算法算法实现步骤:
(1)设置变量和参量:
X(n)为输入向量,或称为训练样本
W(n)为权值向量
b(n)为偏差
d(n)为期望输出
y(n)为实际输出
η为学习速率
n为迭代次数
(2)初始化,赋给w(0)各一个较小的随机非零值,令n=0
(3)对于一组输入样本x(n)和对应的期望输出d,计算
e(n)=d(n)-X^T(n)W(n)
W(n+1)=W(n)+ηX(n)e(n)
(4)判断是否满足条件,若满足算法结束,若否n增加1,转入第(3)步继续执行实际上我本身是在帮别人做一个题目,题目如下:

lsm算法实现如下:
def lsm_fit(theta,sample_num,learn_rating): dim=len(theta) noise=np.random.normal(0,0.1,(sample_num,dim)) X=np.random.randint(0,100,(sample_num,dim)) Y=X*theta+noise theta_fit=np.random.normal(0,0.1,(dim)) # print(theta,noise,theta_fit) loss=[] for i in range(50): p=0 for x in X: e=Y[p]-np.dot(x,theta_fit) theta_fit=theta_fit+learn_rating*x*e p=p+1 # print("(theta,theta_fit",theta,theta_fit) return theta_fit- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
还是很有趣的一个题目,感兴趣的,可以学习一下
上述题目解决如下:
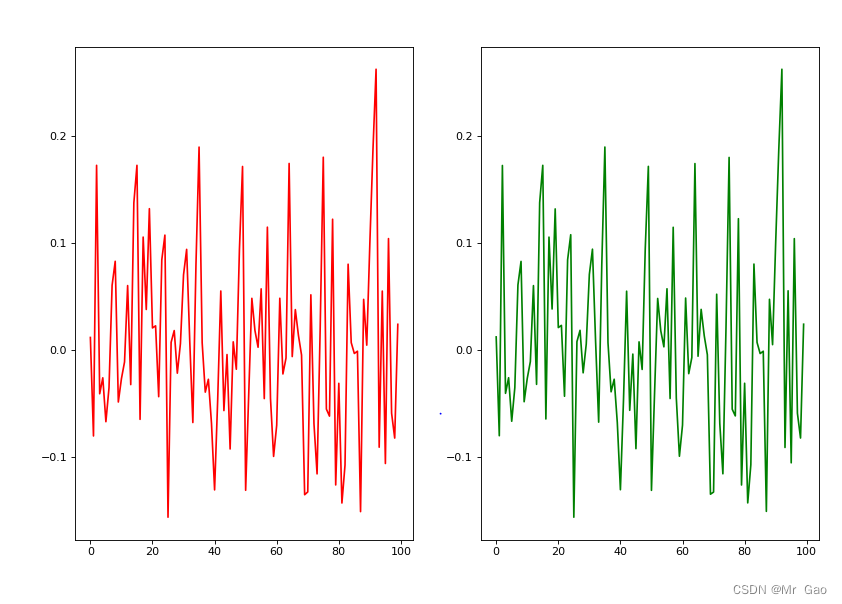
import numpy as np import os import matplotlib.pyplot as plt def lsm_fit(theta,sample_num,learn_rating): dim=len(theta) noise=np.random.normal(0,0.1,(sample_num,dim)) X=np.random.randint(0,100,(sample_num,dim)) Y=X*theta+noise theta_fit=np.random.normal(0,0.1,(dim)) # print(theta,noise,theta_fit) loss=[] for i in range(50): p=0 for x in X: e=Y[p]-np.dot(x,theta_fit) theta_fit=theta_fit+learn_rating*x*e p=p+1 # print("(theta,theta_fit",theta,theta_fit) return theta_fit sample_num=100 theta_list=[] theta_fit_list=[] x=np.arange(0,100,1) x.reshape(100,1) print(x) for i in range(100): theta=np.random.normal(0,0.1,(1)) theta_fit=lsm_fit(theta,sample_num,0.00001) # print("(theta,theta_fit",theta,theta_fit) theta_list.append(theta) theta_fit_list.append(theta_fit) figure, axes = plt.subplots( nrows=1, ncols=2, figsize=(12,8), dpi=80 ) axes[0].plot(x, theta_list, color='r', label = 'theta_list') axes[1].plot(x, theta_fit_list, color='g', label = 'theta_fit_list') plt.show() os.system("pause")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
下面是我做的一个实验结果图:
-
相关阅读:
11. Container With Most Water
CTF-sql注入(X-Forwarded-For)【简单易懂】
浅谈6种流行的API架构风格
Python实现BOA蝴蝶优化算法优化支持向量机分类模型(SVC算法)项目实战
【网络服务&数据库教程】05 LAMP 部署
基于Vue实现模拟微信聊天气泡效果
zabbix监控
嵌入式Linux应用开发-驱动大全-同步与互斥③
书签收藏难整理?这款书签工具管理超方便
C语言-流程控制
- 原文地址:https://blog.csdn.net/weixin_43327597/article/details/126075622
