-
Spring 源码笔记(二),核心概念的理解
💡 根据 遗忘曲线:如果没有记录和回顾,6天后便会忘记75%的内容
读书笔记正是帮助你记录和回顾的工具,不必拘泥于形式,其核心是:记录、翻看、思考章节名 核心概念的理解 作者 将墨子 时间 2022/07/30 简介 Spring 源码笔记(二),核心概念的理解 文章目录
思维导图
本章节思维导图
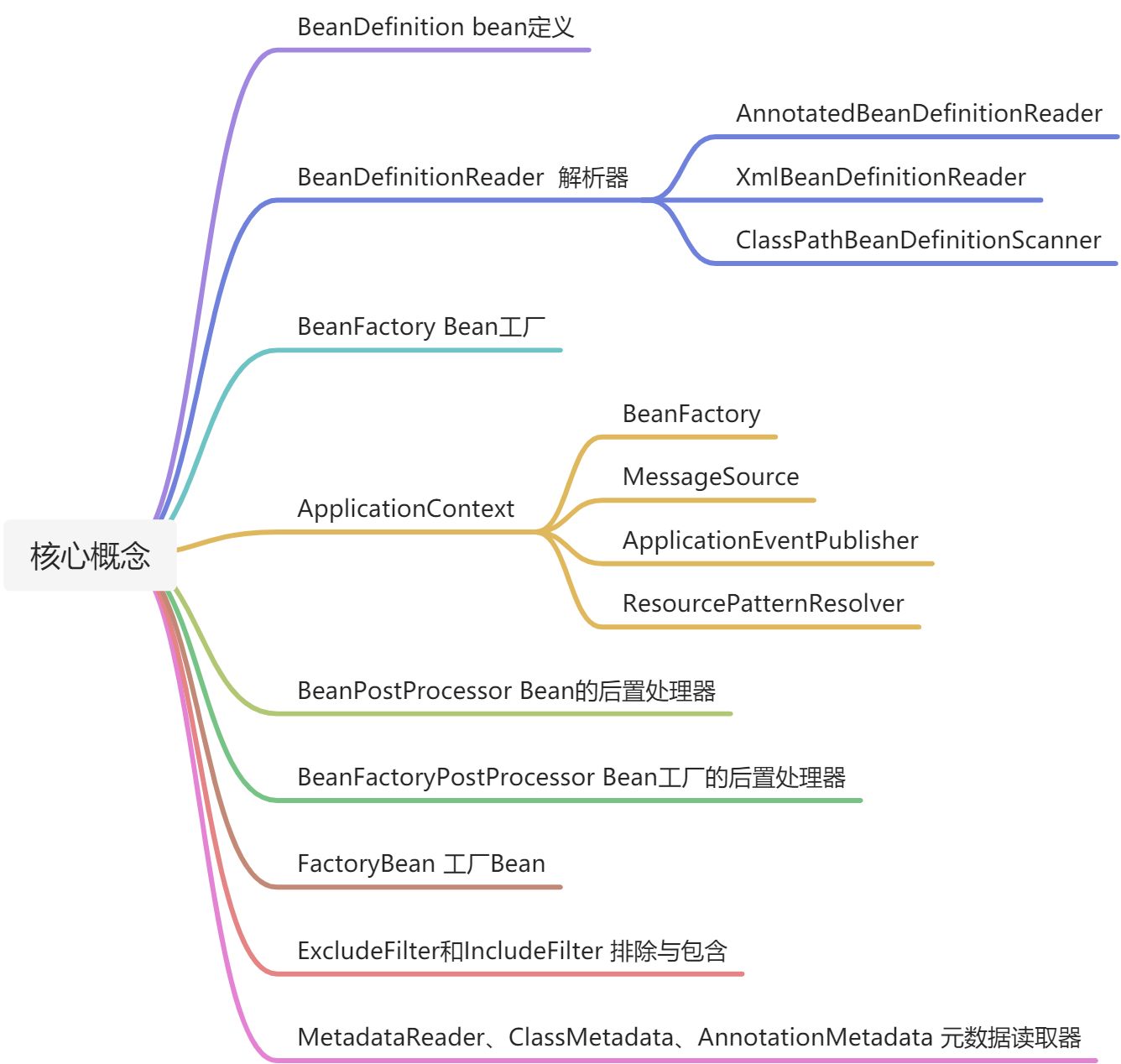
一、BeanDefinition
Bean定义,理解为Bean创建的模板,房屋的蓝图
BeanDefinition表示Bean定义,BeanDefinition中存在很多属性用来描述一个Bean的特点。比如:
其中比较常见的属性有:void setScope(@Nullable String scope); //Bean的作用域 void setLazyInit(boolean lazyInit); // 是否懒加载- 1
- 2
在Spring中,我们经常会通过以下几种方式来定义Bean:
- @Bean
- @Component(@Service,@Controller)
这些,我们可以称之申明式定义Bean。
解析出来的BeanDefinition 都会被存放到一个Map中存放
/** Map of bean definition objects, keyed by bean name. */ private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256);- 1
- 2
二、BeanDefinitionReader
BeanDefinition读取器(BeanDefinitionReader),解析特定内容转化为BeanDefinition
1)AnnotatedBeanDefinitionReader
可以直接把某个类转换为BeanDefinition,并且会解析该类上的注解,它能解析的注解是:@Conditional,@Scope、@Lazy、@Primary、@DependsOn、@Role、@Description
2)XmlBeanDefinitionReader
可以解析标签,转化为BeanDefinition
3)ClassPathBeanDefinitionScanner
ClassPathBeanDefinitionScanner是扫描器,但是它的作用和BeanDefinitionReader类似,它可以进行扫描,扫描某个包路径,对扫描到的类进行解析,比如,扫描到的类上如果存在@Component注解,那么就会把这个类解析为一个BeanDefinition,比如:
protected Set<BeanDefinitionHolder> doScan(String... basePackages) { Assert.notEmpty(basePackages, "At least one base package must be specified"); Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>(); for (String basePackage : basePackages) { Set<BeanDefinition> candidates = findCandidateComponents(basePackage); for (BeanDefinition candidate : candidates) { // Bean 的作用域 单例的还是原型的。。。 ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate); candidate.setScope(scopeMetadata.getScopeName()); // 生成bean 的名字 String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry); if (candidate instanceof AbstractBeanDefinition) { // 初始化一些 beanDefinittion不常用的默认值 postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName); } if (candidate instanceof AnnotatedBeanDefinition) { // 解析@Lazy、@Primary、@DependsOn、@Role、@Description AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate); } // 检查Spring容器中是否已经存在该beanName if (checkCandidate(beanName, candidate)) { BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName); definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry); beanDefinitions.add(definitionHolder); // 注册 registerBeanDefinition(definitionHolder, this.registry); } } } return beanDefinitions; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
三、BeanFactory
BeanFactory表示Bean工厂,所以很明显,BeanFactory会负责创建Bean,并且提供获取Bean的API。
四、ApplicationContext
ApplicationContext是个接口,实际上也是一个BeanFactory,不过比BeanFactory更加强大,比如:
- HierarchicalBeanFactory:拥有获取父BeanFactory的功能
- ListableBeanFactory:拥有获取beanNames的功能
- ResourcePatternResolver:资源加载器,可以一次性获取多个资源(文件资源等等)
- EnvironmentCapable:可以获取运行时环境(没有设置运行时环境功能)
- ApplicationEventPublisher:拥有广播事件的功能(没有添加事件监听器的功能)
- MessageSource:拥有国际化功能
我们先来看ApplicationContext两个比较重要的实现类:
- AnnotationConfigApplicationContext
- ClassPathXmlApplicationContext


而ApplicationContext是BeanFactory的一种,在Spring源码中,是这么定义的:
public interface ApplicationContext extends EnvironmentCapable, ListableBeanFactory, HierarchicalBeanFactory, MessageSource, ApplicationEventPublisher, ResourcePatternResolver { ... }- 1
- 2
- 3
- 4
- 5
- MessageSource 国际化功能
- ApplicationEventPublisher 事件发布功能
先定义一个事件监听器
// 先定义一个事件监听器 @Bean public ApplicationListener applicationListener() { return new ApplicationListener() { @Override public void onApplicationEvent(ApplicationEvent event) { System.out.println("接收到了一个事件"); } }; } // 然后容器发布一个事件: context.publishEvent("kkk");- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- ResourcePatternResolver 资源加载功能
ApplicationContext还拥有资源加载的功能,比如,可以直接利用ApplicationContext获取某个文件的内容:
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class); Resource resource = context.getResource("file://D:\\...\\UserService.java"); System.out.println(resource.contentLength());- 1
- 2
- 3
- 4
五、BeanPostProcessor
BeanPostProcess表示Bena的后置处理器,我们可以定义一个或多个BeanPostProcessor,比如通过以下代码定义一个BeanPostProcessor:
@Component public class tesetBeanPostProcessor implements BeanPostProcessor { @Override public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException { if ("userService".equals(beanName)) { System.out.println("初始化前"); } return bean; } @Override public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException { if ("userService".equals(beanName)) { System.out.println("初始化后"); } return bean; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
一个BeanPostProcessor可以在任意一个Bean的初始化之前以及初始化之后去额外的做一些用户自定义的逻辑,当然,我们可以通过判断beanName来进行针对性处理(针对某个Bean,或某部分Bean)。
我们可以通过定义BeanPostProcessor来干涉Spring创建Bean的过程。
六、BeanFactoryPostProcessor
BeanFactoryPostProcessor表示Bean工厂的后置处理器,其实和BeanPostProcessor类似,BeanPostProcessor是干涉Bean的创建过程,BeanFactoryPostProcessor是干涉BeanFactory的创建过程。比如,我们可以这样定义一个BeanFactoryPostProcessor:
@Component public class testBeanFactoryPostProcessor implements BeanFactoryPostProcessor { @Override public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException { System.out.println("加工beanFactory"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
七、FactoryBean
如果我们想一个Bean完完全全由我们来创造,也是可以的,比如通过FactoryBean:
@Component public class testFactoryBean implements FactoryBean { @Override public Object getObject() throws Exception { UserService userService = new UserService(); return userService; } @Override public Class<?> getObjectType() { return UserService.class; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
通过上面这段代码,我们自己创造了一个UserService对象,并且它将成为Bean。但是通过这种方式创造出来的UserService的Bean,只会经过初始化后,其他Spring的生命周期步骤是不会经过的,比如依赖注入。
其中getBena(“testFactoryBean”) 拿到的是UserService对象
getBena(“&testFactoryBean”) 拿到的是testFactoryBean对象八、ExcludeFilter和IncludeFilter
这两个Filter是Spring扫描过程中用来过滤的。ExcludeFilter表示排除过滤器,IncludeFilter表示包含过滤器
排除UserService类,也就是就算它上面有@Component注解也不会成为Bean @ComponentScan(value = "com.test", excludeFilters = {@ComponentScan.Filter( type = FilterType.ASSIGNABLE_TYPE, classes = UserService.class)}.) public class AppConfig { }- 1
- 2
- 3
- 4
- 5
- 6
- 7
就算UserService类上没有@Component注解,它也会被扫描成为一个Bean。 @ComponentScan(value = "com.test", includeFilters = {@ComponentScan.Filter( type = FilterType.ASSIGNABLE_TYPE, classes = UserService.class)}) public class AppConfig { }- 1
- 2
- 3
- 4
- 5
- 6
- 7
FilterType分为:
- ANNOTATION:表示是否包含某个注解
- ASSIGNABLE_TYPE:表示是否是某个类
- ASPECTJ:表示否是符合某个Aspectj表达式
- REGEX:表示是否符合某个正则表达式
- CUSTOM:自定义
在Spring的扫描逻辑中,默认会添加一个AnnotationTypeFilter给includeFilters,表示默认情况下Spring扫描过程中会认为类上有@Component注解的就是Bean。
protected void registerDefaultFilters() { // 注册@Component对应的AnnotationTypeFilter this.includeFilters.add(new AnnotationTypeFilter(Component.class)); ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
九、MetadataReader、ClassMetadata、AnnotationMetadata
在Spring中需要去解析类的信息,比如类名、类中的方法、类上的注解,这些都可以称之为类的元数据,所以Spring中对类的元数据做了抽象,并提供了一些工具类。通过注册一个BeanDefinition都能看见他的身影
MetadataReader表示类的元数据读取器,默认实现类为SimpleMetadataReader。比如:
public class Test { public static void main(String[] args) throws IOException { SimpleMetadataReaderFactory simpleMetadataReaderFactory = new SimpleMetadataReaderFactory(); // 构造一个MetadataReader MetadataReader metadataReader = simpleMetadataReaderFactory.getMetadataReader("com.test.service.UserService"); // 得到一个ClassMetadata,并获取了类名 ClassMetadata classMetadata = metadataReader.getClassMetadata(); System.out.println(classMetadata.getClassName()); // 获取一个AnnotationMetadata,并获取类上的注解信息 AnnotationMetadata annotationMetadata = metadataReader.getAnnotationMetadata(); for (String annotationType : annotationMetadata.getAnnotationTypes()) { System.out.println(annotationType); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
需要注意的是,SimpleMetadataReader去解析类时,使用的ASM技术。
为什么要使用ASM技术,Spring启动的时候需要去扫描,如果指定的包路径比较宽泛,那么扫描的类是非常多的,那如果在Spring启动时就把这些类全部加载进JVM了,这样不太好,所以使用了ASM技术。
-
相关阅读:
Vue前端模板框架--vue-admin-template
Web学习笔记-CSS
ubuntu 解决pip/pip3安装库各种报错问题
神经痛分类图片大全,神经病理性疼痛分类
【无标题】
K8S部署时IP问题
千梦网创:你现在赚的钱是三年前选择的结果
U-net网络学习记录
我写了本开源书:《3D编程模式》
Java8实战-总结19
- 原文地址:https://blog.csdn.net/weixin_40864434/article/details/126070918
