-
《推荐系统实践》读书笔记
目录
第一章 好的推荐系统
1.1 什么是推荐系统
推荐算法的本质是用一定方式把物品和用户联系起来,这里的方式可以是基于人与人之间的社会联系(社会化推荐)、历史物品属性(基于内容的推荐)、网站中行为模式相似用户(协同过滤推荐)等等。以上的推荐方式基于人类社会常识的先验常识,即相似关系。
1.2 个性化推荐系统的应用
在实际工业应用中,大体上由前端展示、后台日志系统与推荐算法三部分组成。
前端除了展示推荐数据,还可以收集用户对当前推荐的反馈。然后将得到的用户活动数据传输给后台日志系统,经过清洗、分析等操作后,由推荐算法再产生新的推荐。
第二章 利用用户行为数据
基于用户行为分析的算法被称为协同过滤算法,即用户通过与网站互动,一同过滤掉自己不感兴趣的物品。
2.2 用户行为分析
研究表明,用户活跃度和物品活跃度基本都符合长尾分布(Power Law),关系包括用户数量和用户活跃度、产品数量和产品流行度、新旧用户和产品是否热门等。
协同过滤算法有基于邻域的方法(neighborhood-based)、隐语义模型(latent factor model)、基于图的随机游走算法(random walk on graph)等,基于邻域的方法是最广泛应用的。主要包含:基于用户的协同过滤算法、基于物品的协同过滤算法。
2.3 实验设计和算法评估
对用户u推荐N个物品为R(u),令用户u在测试集上喜欢的物品为T(u),定义有:
召回率
 即押中的占用户全部喜欢的比例
即押中的占用户全部喜欢的比例准确率
 即押中的占所有预测的比例
即押中的占所有预测的比例覆盖率
 即推荐物品的总范围为占所有物品的比例
即推荐物品的总范围为占所有物品的比例2.4 基于邻域的算法
主要分为两大类,基于用户的协同过滤算法和基于物品的协同过滤算法。
2.4.1 基于用户的协同过滤算法
1. 基础算法UserCF
该算法的思想主要包括两个步骤:
① 找到和目标用户兴趣相似的用户集合
② 找到这个用户集合喜欢的物品,且目标用户没有听说过,推荐给目标用户。
用数学的方式来实现这一过程:
① 假设有用户u和v,N(u)和N(v)为两用户喜欢的物品集合,有Jaccard公式来计算两人的兴趣相似度:
 或用余弦相似度
或用余弦相似度 来计算
来计算通过上述方程,取相似度最大的前K位,找到K个和用户兴趣最为相似的其他用户
② S(u, K)为和用户u兴趣最接近的K个用户,P(i)为对物品i有行为的用户集合,r_{vi}代表用户v对物品i的兴趣,这里v属于与用户最K相似且接触过i的用户群体,可以推测用户u对他没接触过的物品i的兴趣程度为:

UserCF只有一个超参即K。
2. UserCF算法改进——User-IIF
根据经验来看,两个用户对冷门物品采取过同样的行为更能说明他们兴趣的相似度。如John S.Breese提出的相似度计算:
 通过1/(log(1+|N(i)|))惩罚了热门物品相似度影响,N(i)为物品i的热门程度(对物品i有正反馈的用户总数)
通过1/(log(1+|N(i)|))惩罚了热门物品相似度影响,N(i)为物品i的热门程度(对物品i有正反馈的用户总数)2.4.2 基于物品的协同过滤算法
1. 基础算法ItemCF
ItemCF不是利用物品的内容属性计算物品之间的相似度,而是通过分析用户的行为,计算物品之间的相似度。并且能给出推荐的解释(基于哪个物品所以推荐了这个物品)。
即假设每个用户的兴趣分布于有限的某几个方面,如果一对物品同时属于很多用户的兴趣列表,那么它们很可能属于同一个领域,因此有很大的相似度。
思想上也主要分为两步:
① 计算物品之间的相似度
② 根据物品的相似度和用户的历史行为给用户生成推荐列表
数学上:
① N(i)为喜欢物品i的用户数,物品i和物品j的相似度定义(喜欢物品i的用户中有多少也喜欢物品j)为:

为了避免热门物品让wij趋近于1,可以用
 来惩罚
来惩罚② N(u)是用户u感兴趣的物品集合,S(j, K)是和物品j最相似的K个物品集合,r_{ui}是用户u对物品i的兴趣。通过如下公式计算用户u对物品j的兴趣:
 ,即对于任意一个物品j,找到j最相似的K个物品,且这K个物品在用户u的兴趣中的交集元素i,计算j和i相似度与用户对i兴趣程度的乘积。
,即对于任意一个物品j,找到j最相似的K个物品,且这K个物品在用户u的兴趣中的交集元素i,计算j和i相似度与用户对i兴趣程度的乘积。2. ItemCF改进算法ItemCF-IUF
与之前在UserCF出现的流行物品的惩罚有相似之处,活跃用户的贡献也需要惩罚,称为IUF(Inverse User Frequence):

在实际应用中,对于过于活跃的用户可以直接忽略其兴趣列表,避免相似度矩阵过于稠密。
3. 物品相似度归一化ItemCF-Norm
Karypis发现如果把相似度矩阵归一化,可以提高推荐准确率,覆盖率和多样性,得到ItemCF-Norm算法:

但是两个不同领域的最热门物品往往具有比较高的相似度,这时仅靠用户行为数据不能解决问题。
2.4.3 UserCF和ItemCF的综合比较
UserCF基于物品找相似用户,取前K个相似用户计算该物品的评分, 推荐更社会化,反映用户所在小型兴趣群体中物品热门程度;
ItemCF基于用户找相似物品,取前K个相似物品计算该物品的评分,更个性化,反映用户自己的兴趣传承。
UserCF需要维护用户相似性表,ItemCF需要维护物品相关度表,可以考虑不同网站中用户与物品不同的更新速度、数量级来选择合适的算法。
2.5 隐语义模型
隐语义模型缩写LFM(latent factor model),处于文本挖掘领域,用于找到文本的隐含语义。相关词有LSI、pLSA、LDA,Topic Model,隐含类别模型(latent class model),隐含主题模型(latent topic model)和矩阵分解(matrix factorization)。
2.5.1 基础算法
核心思想是通过隐含特征联系用户兴趣和物品。原理与UserCF类似,默认物品都是属于有限的类别,UserCF只是挑选K个与已读书籍最近似的而并不特别指明类别,隐语义显式从每个分类中挑选物品。
采用隐语义分析技术(latent variable analysis),基于用户行为统计的自动聚类。
(1)LFM公式计算用户u对物品i的兴趣如下:
 其中p_{u,k}度量用户u和第k个隐类间的关系,q_{i,k}度量第k个隐类和物品i之间的关系。详见《one-class collaborative filtering》
其中p_{u,k}度量用户u和第k个隐类间的关系,q_{i,k}度量第k个隐类和物品i之间的关系。详见《one-class collaborative filtering》LFM在显性反馈数据上表现不错,在隐形反馈数据上需要解决如何生成负样本问题。采样应遵循原则:① 正负样本数目相似 ② 负样本采取热门但用户无行为的物品。
(2)根据损失函数和梯度下降法来计算p和q,损失函数定义为:
 (与吴恩达老师课程中提到的推荐系统算法一致)
(与吴恩达老师课程中提到的推荐系统算法一致)实验测评得到的结果与预期一致,每个隐类中qik的top-n电影确实符合实际情况。超参有:
① 隐特征个数F ② 学习速率alpha ③ 正则化参数lambda ④ 正负样本比例ratio
其中ratio对结果影响最大。
2.5.2 基于LFM的实际系统例子
LFM在实际中很难实时推荐,因为每次训练生成用户隐类向量和物品隐类向量,需要扫描所有用户的行为记录,非常耗时,冷启动问题明显。雅虎人员提出了一个解决方案,详见第八章。
2.5.3 LFM和基于邻域的方法的比较
LFM 基于邻域 较好的理论基础,学习方法 统计方法 空间复杂度小 时间复杂度偏小,但区别不大
不能实时更新 能实时更新 2.6 基于图的模型
可以把基于领域的模型看做基于图的模型的简单形式。通过二分图表示用户行为,可以用图的算法给用户个性化推荐。
2.6.1 用户行为二分图表示
令G(V,E)为用户物品二分图,V为顶点V = Vu ∪ Vi;E为边,每个二元组(u, i)都有对应的边e(vu, vi),vu是用户顶点,vi是物品定点。
2.6.2 基于图的推荐算法
给用户推荐物品的任务在二分图中,可以转换为度量用户vu与不与vu直连物品节点在图上的相关性。相关性一般取决于:两顶点之间的路径数目;路径长度;路径经过的顶点。
主要学习PersonalRank算法,详见《Topic-Sensitive PageRank》
缺点是时间复杂度很高,解决方案有两种:①减少迭代次数 ② 从矩阵出发重新设计算法
第三章 推荐系统冷启动问题
3.1 冷启动问题简介
主要分为三类:用户冷启动、物品冷启动、系统冷启动
解决方案有:非个性化推荐(top-n),粗粒度用户信息个性化,社交账号导入,收集用户信息问卷,物品内容信息相似
3.2 利用用户注册信息
新用户不存在历史行为记录,可以通过用户注册时填写的年龄、性别等人口统计信息给用户提供粗粒度的个性化推荐:
① 获取用户注册信息 ② 根据注册信息对用户进行分类 ③ 给用户推荐该类别中用户喜欢的物品
其核心问题在于如何计算不同类别的用户喜欢什么物品,或者说喜欢物品i的用户中含有f特征的比例:
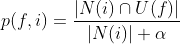
N(i) ∩ U(f)是用户群f中喜欢物品i的用户数,加上α是为了过滤无统计意义的信息(刚好只有一个用户喜欢i且它在类f中,若不加α得到的比例为1)
3.3 选择合适的物品启动用户的兴趣
用户注册后,先让用户对物品进行评分来收集用户兴趣,然后再做推荐。一般来说,评分物品需要具有特点:热门(用户有所了解才能有所反馈)、有区分度、多样性。
通过决策树来生成这些评分物品,详见论文《Adaptive Bootstrapping of Recommender Systems Using Decision Trees》
3.4 利用物品的内容信息
3.5 发挥专家的作用
通过人力手工给部分物品打标签,结合一些机器学习与自然语言技术给剩下的物品自动生成标签。
第四章 利用用户标签数据
第五章 利用上下文信息
第六章 利用社交网络数据
第七章 推荐系统实例
第八章 评分预测问题
-
相关阅读:
Day20.1:关于this、super的解析
命令模式,命令 Command 类对象的设计(设计模式与开发实践 P9)
文字太多时给文本框添加滑动条——text + ContentSizeFitter + Scroll View
flutter webrtc搭建1v1通信服务
苹果IOS安装IPA, plist形式 Safari 浏览器点击安装
Docker命令
Go-Python-Java-C-LeetCode高分解法-第十周合集
02.相关术语MVC、MTV、ORM介绍
蓝牙芯片香薰机智能化方案
1016 部分 A+B 【PAT (Basic Level) Practice (中文)】
- 原文地址:https://blog.csdn.net/SofiaT/article/details/125840515