-
Linux【yum】【git】【gdb】
目录
一、yum
什么是软件包?
在Linux下安装软件, 一个通常的办法是下载到程序的源代码, 并进行编译, 得到可执行程序.
但是这样太麻烦了, 于是有些人把一些常用的软件提前编译好, 做成软件包(可以理解windows上的安装程序)放在一个服务器上, 通过包管理器可以很方便的获取到这个编译好的软件包, 直接进行安装.
软件包和软件包管理器, 就好比 "App" 和 "应用商店" 这样的关系.
yum(Yellow dog Updater, Modified)是Linux下非常常用的一种包管理器. 主要应用Fedora, RedHat,Centos等发行版上.1.你要下载安装的软件是在你的电脑上吗?
不是。
2.如果不在,你怎么知道在哪里的?
搜索经历。
3.谁放的?
它内部的工作人员。
4.手机上下载软件是谁放的呢?
应用商店和app的提供者放的。
5.Linux上的软件是谁放的呢?
Linux社区或者对应的开发人员。
所以Linux上下载软件和Windows,手机APP上下载软件是相同的。
yum可以帮助我们从Linux的一些软件发布平台下载到我们所需的对应的软件,所以yum可以等同于我们手机的应用市场。
yum的功能
1.搜索,下载,安装
2.解决依赖关系
一般原生的Linux系统,内置的下载链接基本都是自己配套的国外的网站。
我们国内的一些学术机构或者企业会将国外的一些网站上发布的软件以镜像的方式拷贝下来,并定期提供更新,从而满足国内的软件下载的使用。这些是属于官方的软件平台。
这些官方的软件经过了时间的检验,与系统的契合度高。
还有一些非官方的预备平台,提供一些非官方的命令。
yum是一个用Python写的工具
yum源:就是一个配置文件,告诉系统具体软件的安装路径
ls /etc/yum.repos.d
如果没有epel库的话,执行下面的代码安装源
sudo yum install -y epel-release将我们能够在Linux上下载的软件全部罗列出来
yum list我们可以查看到大量的软件

查找软件
但是由于上面查找出来的软件太多了,我们需要补充一些查找命令。如使用下面的代码我们就能查找全部的含有sl的软件
yum list | grep sl每个软件后面的el7代表的是能够在centos7上跑的平台。
最后一列的epel,base之类的是软件的提供者。
base是属于标准源,epel属于扩展源。

安装软件
使用yum install +对应的软件名就可以安装对应的软件
yum install sl但是我们在Linux下安装软件的时候是需要root的权限的。因为这个时候我们是从网络上将软件拷贝到我们的电脑中。

这个时候我们需要给我们的软件前面加上sudo来提升权限
sudo yum install sl加上-y选项可以阻止系统提示你是否要安装的一些提问。

如果我们之前加上-y系统就不会提示这个了。

卸载软件
yum remove +对应的软件
sudo yum remove sl
links加上网址能访问对应的网站,links可以采用上面的方式安装
什么是解决依赖关系?
有时候我们一个软件单独是不能运行的,需要多个软件相互配合起来才能更好地运行,比方说我们的Python,pycharm如果是进行一些科学运算和数据统计的话,需要依赖于anaconda所配置的环境。同样,我们的yum会将我们所要运行的软件和其相互依赖关系的软件一同下载。
所以软件在更新的时候,可以通过更改其中的某些动静态库来达到更新的效果,从而达到功能的迭代。
二、Git
git是版本管理器。实际上,这是一种多人协作开发工具。当然如果是咱一个人写的话就仅仅是相当于一个“百度云盘”的功能。
1.什么是版本控制?
打个比方:我们毕业的时候写毕业论文。我们写完毕业论文就给我们的导师去看,导师给我们提意见,然后我们就会改出第二版、第三版、等等版本。但是万一老师说还是第一个版本好,那么我们如果没有版本控制,每一次就是对着我们的原稿修改,我们很难还原回我们的最初的版本。这个时候我们就需要版本控制。
这个老师我们可以类比为程序经理,这个学生就可以理解为是程序员,这个毕业论文就可以理解为是代码。所以我们的git就是实现了我们的代码的版本的管理。(git是开源的,svn是商业化的,一般企业里用)
其中我们如果是从新版本倒回老版本就称为回滚v3->v1
如果是从v2版本改出v2.1版本,就是分支版本。
git既是客户端也是服务器
2.Git的历史
雷纳斯·托瓦兹(Linus Benedict Torvalds)在写出了Linux内核之后。由于Linux是开源的,就有非常多的人给他发代码,告诉他在哪些地方可以优化,在哪些地方可以设计新的功能。他就需要手动将这些代码和Linux内核所组成的代码将其合并为一个完整的版本发布出来。但是这种方式非常繁琐,对于多人共同开发软件版本来说非常不友好。当然当时也可以花钱买版本管理工具,但是Linux是免费的,而却用花钱的软件,这和开源精神不符合。但这个版本控制器的老板听闻了他们的故事,免费提供给所有Linux的社区的人使用这个版本管理器。而在Linux社区中的人有想破解这个版本控制器的想法。这个消息被之前这个版本控制的老板知道了,就停止了对于Linux社区的授权。但是随着Linux的发展,版本管理的任务变得越来越复杂,所以雷纳斯·托瓦兹(Linus Benedict Torvalds)就写了一款版本控制工具,也就是我们现在的Git,并且进行了开源。随着越来越多的工程师的涌入,Git经过版本迭代变得越来越全面。而GitHub,Gitee就是在底层利用Git的逻辑,然后编写了网页,提供代码托管服务。
安装
如何在Linux上安装Git
sudo yum install git然后我们可以使用下面代码来查看我们Git的版本
git --version
Gitee
点击这里新建仓库,

由于Gitee之前在清理一些质量不高的软件,所以不能直接创建开源的仓库,我们可以进行简单的配置,然后创建我们的仓库

从这里复制我们的仓库的链接

转到我们的Linux,克隆我们的Git仓库,然后输入我们的Gitee的账号和密码
git clone 你的git仓库
返回到我们的上一级目录,然后使用tree +我们刚刚的目录

我们从下面的代码中可以看到有一个.git文件,这就是我们的版本管理文件。

添加代码到本地仓库
将代码添加到我们的本地仓库
git add 你的文件这里我们创建了一个hello.c文件

然后将我们的代码提交到我们的本地仓库

将代日志交到仓库当中
提交日志是你这一次代码的改动主要修改了哪些地方的记录
git commit -m "这里必须写提交日志"
提交代码到远端仓库
如何将Git与网络仓库同步
首先输入下面的代码
git push然后进行Gitee账号的认证。

输入完成之后就能够提交上git了。

这里我们就可以看到我们刚刚在Linux端提交的文件了,也就是我们的hello.c文件

其他情况
可能是第一次使用,需要你配置用户名和邮箱
- git config --global user.email "you@example"
- git config --global user.name "Your Name"

为什么要配置邮箱和用户名呢?
有时候你的代码出现了一些问题或者是别人想和代码的创始人交流一下,就可以通过邮箱的方式进行联系。
查看提交记录
查看提交记录
git log
在进行了一定的操作时候,再次查看我们的日志,我们越上面的日志是举例我们现在最近的日志

多人开发时的同步问题
如果我们多人开发的时候我们的本地仓库和远程的仓库可能会不同步,或者是出现冲突,会出现代码无法提交的情况,我们直接
git pull来讲我们的仓库同步一下,就可以重新提交了
.gitignore
.gitignore有时候你不想将某些后缀的文件同步到远程的git仓库中,就可以添加到.gitignore,就相当于是将文件加入到了黑名单中。(.gitingore就是一个文件)
下面的是.gitignore中本来的文件,我们只需要仿照下面的格式就可以了。

如何删除文件
使用我们下面的代码删除我们的文件git rm +文件名
git rm下面就是像将刚刚我们的测试文件hello.c文件删除

提交我们的日志

使用git push将我们的远程的仓库与我们的本地同步,再输入我们的账号和密码

输入完就提交完成了

这时我们再查看我们的仓库就没有刚刚的hello.c文件了

三、gdb
如果没有安装gdb我们需要执行下面的代码来安装gdb
sudo yum install gdb如果出现如下的代码就是安装成功了。

我们如何看待gdb这个代码调试器?
要会操作,知道怎么用gdb调试。很多情况下我们面对的问题根本不是调试器的问题,而是调试思路的问题。
1.背景认识
这里我们先写了一个一到一百的累加程序

然后我们使用我们的gcc编译一下,可以看到我们的程序正确地输出了一到100的累加的结果。

我们试图使用gdb +我们的生成的文件也就是mytest

我们发现我们的gdb提示我们(no debugging symbols found)
(输入q再按回车就可以退出gdb)
这是因为gcc &&g++默认形成的可执行程序时release版本的,故没有办法直接被调试
生成debug版本
给我们的gcc编译的时候添加-g选项的时候,该程序执行之后就是以debug版本发布的,
gcc mytest.c -o mytest-debug -g
其文件比我们的发布版大,因为其中加入了大量的调试信息

这时,我们就生成了我们的调试的文件,注意这里的debug适合mytest连在一起的,是一个文件的名称,不是什么选项。
读取我们程序的可执行段
使用下面的代码就可以读取我们程序的可执行段,就是将一个可执行程序中的结构给读取了出来
-S表示读取程序的各个段
readelf -S mytest
其中.text文件也就是文本,也就是我们的代码。
rodata就是read only data也就是只读数据
对于我们一开始的mytest文件,我们通过grep帅选出debug文件,发现并没有debug文件
readelf -S mytest | grep -i debug
而对于我们之前生成的debug版的文件,我们执行下面的代码,
我们从中可以找到与debug相关的文件
readelf -S mytest-debug
我们再使用下面的代码,将我们含有debug的文件筛选出来
readelf -S mytest-debug | grep -i debug
如何使用gdb
我们需要先生成一个debug版本的测试文件,然后使用gdb加上文件名来调试该程序

显示源代码
list/l 行号:显示binFile源代码,接着上次的位置往下列,每次列10行。
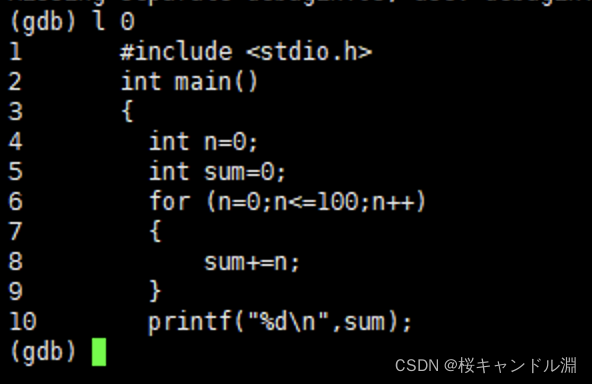
再按一下l再往后10行

list/l 函数名:列出某个函数的源代码。运行程序
r或run:运行程序。
逐过程执行
n 或 next:单条执行。也就是逐过程,等同于vs的F10

逐语句调试
s或step:进入函数调用,逐语句 ,等同于我们vs中的f11

设置断点
break(b)+行号:在某一行设置断点
break 函数名:在某个函数开头设置断点查看断点信息
info break :查看断点信息。
finish:执行到当前函数返回,然后挺下来等待命令
print(p):打印表达式的值,通过表达式可以修改变量的值或者调用函数打印变量值
p 变量:打印变量值。

修改变量
set var:修改变量的值
这里我们的n循环从0到100,调试起来如果想要直接进行到n=10的时候,就直接set var n=10就可以了。

从一个断点跳到下一个断点
continue(或c):从当前位置开始连续而非单步执行程序,运行至下一个断点处停下来
这是我们所设置的断点

这是我们已经运行到第10行了,使用一下continue就能从第10行运行到12行。

开始运行
run(或r):从开始连续而非单步执行程序

打断点
delete breakpoints:删除所有断点
delete breakpoints n:删除序号为n的断点
info(或i) breakpoints:参看当前设置了哪些断点,以下就是我们打的断点

disable breakpoints:禁用断点下面我们的断点一开始都是全部打开的,看end那一列是y还是n,y就是yes,n就是no
运行disable之后y就会变成n
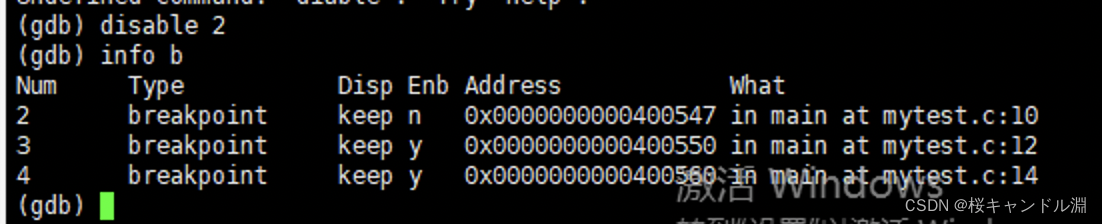
enable breakpoints:启用断点
我们看到我们的2号断点从n变成了y。

删断点和打断点不同,我们的后面跟的breakpoints不是行号,而是gdb给我们的断点的编号。下面是我们试图使用一开始的行号删除断点,结果失败了

查看一下我们断点的编号

使用d+断点编号就能删掉了
不过要注意后面的其他断点的编号是不会发生变化的。

常显示某个变量
display 变量名:跟踪查看一个变量,每次停下来都显示它的值

取消常显示
undisplay:取消对先前设置的那些变量的跟踪,后面跟着的数字是之前常显示的编号

跳转到指定行
until X行号:跳至X行

查看函数调用堆栈
breaktrace(或bt):查看各级函数调用及参数

info(i) locals:查看当前栈帧局部变量的值
退出gdb
quit:退出gdb

gdb会记录最近一条命令,如果命令无变化,可以直接回车
-
相关阅读:
安全狗云眼的主要功能有哪些?
通讯网关软件028——利用CommGate X2Modbus实现Modbus RTU访问PI服务器
【linux】安装openjdk8
CUDA编程基础:如何实现c++事实绘制曲线,采用的绘图工具箱是:gnuplot
Panda3D如何加载obj格式的3D模型文件
opencv实现模块化图像处理管道
任务分配——斜率优化dp——运输小猫
使用软引用实现缓存机制
第一百零八篇:最常用的基本数据类型(Number类型)
记一次 .NET 某工控视觉系统 卡死分析
- 原文地址:https://blog.csdn.net/weixin_62684026/article/details/126034798