-
pytorch深度学习单卡训练和多卡训练
单机单卡训练模式
# 设置GPU参数,是否使用GPU,使用那块GPU if config.use_gpu and torch.cuda.is_available(): device=torch.device('cuda',config.gpu_id) else: device=torch.device('cpu') # 检查一下GPU是否可以使用 print('GPU是否可用:'+str(torch.cuda.is_available()))- 1
- 2
- 3
- 4
- 5
- 6
- 7
单机多卡训练模式
- Single Machine Data Parallel(单机多卡模式)这个版本已经淘汰
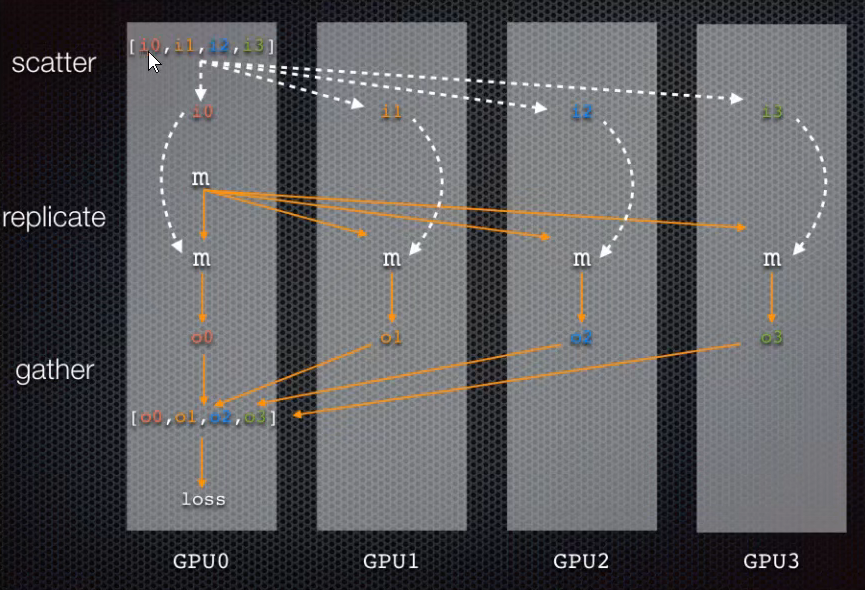
from torch.nn.parallel import DataParallel device_id=[0,1,2,3] device=torch.device('cuda:{}'.format(device_id[0])) # 设置0号GPU是主GPU model=model.to(device) model=DataParallel(model,device_ids=device_id,output_device=device)- 1
- 2
- 3
- 4
- 5
- 6
首先会把所有数据分发到列表上的GPU进行训练,然后再gather到主GPU计算loss
- DistributedParallel(简称DDP,多进程多卡训练)

代码变成流程: - 1.初始化进程组
torch.distributed.init rocess_group(backend="nccl", world_size=n_gpus,rank=args.local_rank) # backend:进程方式 # word_size:当前这个GPU上有多少张卡 # rank:指定当前进程是在那个GPU上- 1
- 2
- 3
- 4
- 2.设置CUDA_VISIBLE_DEVICES环境变量
torch.cuda.set_device(args.local_rank)- 1
- 3.对模型进行包裹
model = DistributedDataParallel(model.cuda(args.local_rank), device_ids=[args.local_rank]) ~~~Python * 4.对每张卡的数据进行分配- 1
- 2
- 3
train_sampler = DistributedSampler(train_dataset)
源码位于torch/utils/data/distributed.py
* 5.将数据传递到dataload中,传递进来的数据就不需要suffer了 * 6.将数据复制到cuda上 ~~~Python data=data.cuda(args.local_rank)- 1
- 2
- 3
- 4
- 7.执行命令(在使用ddp这种方式训练的时候,需要使用命令执行)
python -m torch.distributed.launch--nproc_per_node=n_gpu train.py- 1
- 8.保存模型
torch.save在local_rank=O的位置进行保存,同样注意调用model.module.state_dict() torch.load 注意map_location- 1
- 2
注意事项:
- train.py中要有接受local_rank的参数选项,launch会传入这个参数
- 每个进程的batch_size应该是一个GPU所需要的batch_size大小
- 在每个周期开始处,调用train_sampler.set_epoch(epoch)可以使得数据充分打乱
- 有了sampler,就不要在DataLoader中设置shuffle=True了
完整代码
# 系统相关的 import argparse import os # 框架相关 import torch from torch.utils.data import DataLoader import torch.optim as optim import torch.nn as nn import os # 自定义包 from BruceNRE.config import config from BruceNRE.utils import make_seed,load_pkl from BruceNRE.process import process from BruceNRE.dataset import CustomDataset,collate_fn from BruceNRE import models from BruceNRE.trainer import train,validate # 导入分布式训练依赖 import torch.distributed as dist from torch.utils.data.distributed import DistributedSampler from torch.nn.parallel import DistributedDataParallel __Models__={ "BruceCNN":models.BruceCNN } parser=argparse.ArgumentParser(description="关系抽取") parser.add_argument("--model_name",type=str,default='BruceCNN',help='model name') parser.add_argument('--local_rank',type=int,default=1,help='local device id on current node') if __name__=="__main__": # ====================关键代码================================== os.environ["CUDA_VISIBLE_DEVICES"]="0,1,2,3" # 分布式训练初始化 torch.distributed.init_process_group(backend="nccl") # 设置当前的设备只用这张卡 torch.cuda.set_device(args.local_rank) # 单机多卡:代表有几块GPU args.word_size=int(os.getenv("WORLD_SIZE",'1')) # 获取当前进程的序号,用于进程间的通信 args.global_rank=dist.get_rank() #============================================================= model_name=args.model_name if args.model_name else config.model_name # 为了保证模型每次训练的时候都一样的,设置了一个初始化种子 make_seed(config.seed) # 数据预处理 process(config.data_path,config.out_path,file_type='csv') # 加载数据 vocab_path=os.path.join(config.out_path,'vocab.pkl') train_data_path=os.path.join(config.out_path,'train.pkl') test_data_path=os.path.join(config.out_path,'test.pkl') vocab=load_pkl(vocab_path,'vocab') vocab_size=len(vocab.word2idx) #CustomDataset是继承了torch.util.data的Dataset类的一个类,用于数据加载,详情见Dataset train_dataset = CustomDataset(train_data_path, 'train-data') test_dataset = CustomDataset(test_data_path, 'test-data') # 测试CNN模型 model=__Models__[model_name](vocab_size,config) print(model) #=====================关键代码================================= # 定义,并且把模型放到GPU上 local_rank = torch.distributed.get_rank() torch.cuda.set_device(local_rank) global device device = torch.device("cuda", local_rank) # 拷贝模型,将模型放入DistributedDataParallelAPI model.to(device) # 加载多GPU model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank, find_unused_parameters=True) # 构建一个train-sample train_sample = DistributedSampler(train_dataset) test_sample=DistributedSampler(test_dataset) # 使用分布式训练,一定要把suffle设置为False,因为DistributedSampler会吧数据打乱 train_dataloader = DataLoader( dataset=train_dataset, batch_size=config.batch_size, shuffle=False, drop_last=True, collate_fn=collate_fn, sampler=train_sample ) test_dataloader = DataLoader( dataset=test_dataset, batch_size=config.batch_size, shuffle=False, drop_last=True, collate_fn=collate_fn, sampler=test_sample ) # ============================================= # 构建优化器 optimizer=optim.Adam(model.parameters(),lr=config.learing_rate) scheduler=optim.lr_scheduler.ReduceLROnPlateau(optimizer,'max',factor=config.decay_rate,patience=config.decay_patience) # 损失函数:交叉熵 loss_fn=nn.CrossEntropyLoss() # 评价指标,微平均,宏平均 best_macro_f1,best_macro_epoch=0,1 best_micro_f1,best_micro_epoch=0,1 best_macro_model,best_micro_model='','' print("***************************开始训练*******************************") for epoch in range(1,config.epoch+1): train_sample.set_epoch(epoch) # 让每张卡在每个周期中得到的数据是随机的 train(epoch,device,train_dataloader,model,optimizer,loss_fn,config) macro_f1,micro_f1=validate(test_dataloader,device,model,config) model_name=model.module.save(epoch=epoch) scheduler.step(macro_f1) if macro_f1>best_macro_f1: best_macro_f1=macro_f1 best_macro_epoch=epoch best_macro_model=model_name if micro_f1>best_micro_f1: best_micro_f1=micro_f1 best_micro_epoch=epoch best_micro_model=model_name print("=========================模型训练完成==================================") print(f'best macro f1:{best_macro_f1:.4f}',f'in epoch:{best_macro_epoch},save in:{best_macro_model}') print(f'best micro f1:{best_micro_f1:.4f}',f'in epoch:{best_macro_epoch},save_in:{best_micro_model}')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
最后在shell后台使用的下面语句运行(暂时我只发现这种方法运行,其他方法还需要寻找)
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py- 1
其中
- torch.distributed.launch表示以分布式的方式启动训练,
- nproc_per_node指定一共就多少个节点,可以设置成显卡的个数
-
相关阅读:
28岁功能测试被辞,最后结局令人感慨...
js前端获取农历日期
计算机中的数据表示
Temu是否需要压货?Temu售后政策——站斧浏览器
TAMRA-NHS 荧光素-活性酯
Day 48 | 198.打家劫舍 & 213.打家劫舍II & 337.打家劫舍 III
思科防火墙高级应用
效果最大化的所需素材
Web3 参考架构
利用Python进行数据分析系列之:数组和矢量计算
- 原文地址:https://blog.csdn.net/qq_35653657/article/details/126003505
