-
Python数据分析与机器学习3-Pandas
文章目录
一. Pandas简介
Pandas官方文档: https://pandas.pydata.org/pandas-docs/stable/
Pandas 是 Python 语言的一个扩展程序库,用于数据分析。
Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
Pandas 名字衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析)。
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征二. 数据源介绍
2.1 food_info.csv
这个是食品包含各种营养物质及卡路里的数据

2.2 titanic_train.csv
泰坦尼克号的数据集

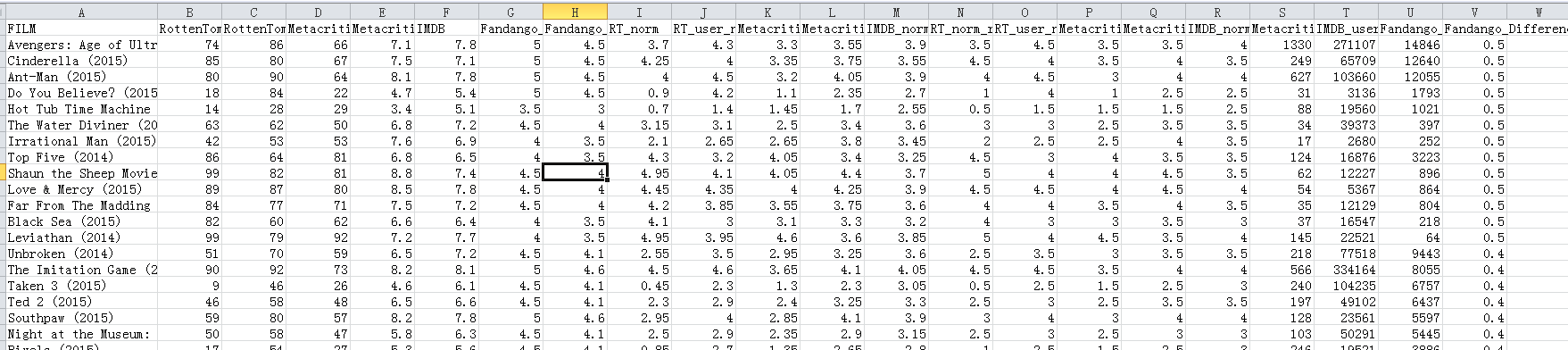
2.3 fandango_score_comparison.csv
电影评分的数据集
三. pandas之DataFrame数据结构实操
pandas中最常使用的就是DataFrame数据结构了,例如从csv等文件格式读取到的内容就是DataFrame数据格式。
3.1 pandas读取csv文件数据
pandas读取csv文件是实际工作中使用得非常多的。
如果需要查看帮助文档,可以使用print (help(pandas.read_csv))命令。object - For string values int - For integer values float - For float values datetime - For time values bool - For Boolean values- 1
- 2
- 3
- 4
- 5
代码:
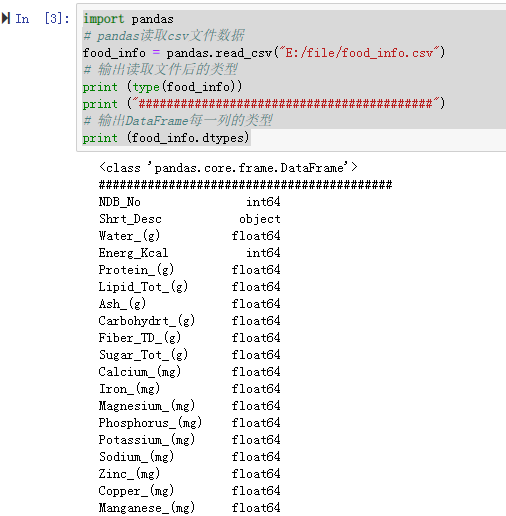
import pandas # pandas读取csv文件数据 food_info = pandas.read_csv("E:/file/food_info.csv") # 输出读取文件后的类型 print (type(food_info)) print ("##########################################") # 输出DataFrame每一列的类型 print (food_info.dtypes)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
测试记录:
3.2 pandas数据展示
3.2.1 输出读取到的数据
代码:
import pandas # pandas读取csv文件数据 food_info = pandas.read_csv("E:/file/food_info.csv") # 输出读取到的数据 print (food_info)- 1
- 2
- 3
- 4
- 5
测试记录:
可以看到比原本的数据多了一个数组的下标,从0开始,依次递增
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4TRJuQ3w-1657070939337)(https://upload-images.jianshu.io/upload_images/2638478-8950867a859b5fb1.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)]
数据太多了,中间进行了隐藏

因为列太多了,这边也是分开进行展示数据

3.2.2 输出列信息及行数列数
代码:
import pandas # pandas读取csv文件数据 food_info = pandas.read_csv("E:/file/food_info.csv") print ("##########################################") # 输出dataframe的列信息 print (food_info.columns) print ("##########################################") # 输出dataframe的行数和列数 print (food_info.shape)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
测试记录:

3.2.3 输出前几行和最后几行
代码:
import pandas # pandas读取csv文件数据 food_info = pandas.read_csv("E:/file/food_info.csv") print ("##########################################") # 输出前3行 print(food_info.head(3)) print ("##########################################") # 输出最后3行 print(food_info.tail(3))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
测试记录:

3.3 索引的方法
索引的方法是输出指定的行的数据
代码:import pandas # pandas读取csv文件数据 food_info = pandas.read_csv("E:/file/food_info.csv") print ("##########################################") # 输出第0行 print (food_info.loc[0]) # 输出第3到6行 print ("##########################################") print (food_info.loc[3:6]) print ("##########################################") # 输出第 2,5,10行 two_five_ten = [2,5,10] print(food_info.loc[two_five_ten]) print ("##########################################") print(food_info.loc[[2,5,10]])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3.4 输出指定的列
代码1:
import pandas # pandas读取csv文件数据 food_info = pandas.read_csv("E:/file/food_info.csv") print ("##########################################") # 输出指定列 print (food_info["NDB_No"])- 1
- 2
- 3
- 4
- 5
- 6
- 7
测试记录1:

代码2:
import pandas # pandas读取csv文件数据 food_info = pandas.read_csv("E:/file/food_info.csv") print ("##########################################") # 输出包含 (g) 的列 col_names = food_info.columns.tolist() #print col_names gram_columns = [] for c in col_names: if c.endswith("(g)"): gram_columns.append(c) gram_df = food_info[gram_columns] print (gram_df.head(3))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
测试记录2:

3.5 group by函数的用法
函数 用途 min 最小值 max 最大值 sum 求和 mean 均值 median 中位数 std 标准差 var 方差 count 计数 我们现在想求泰坦尼克号每个等级的仓位 票价的总和以及年龄的平均值。
代码:
import pandas as pd import numpy as np titanic_survival = pd.read_csv("E:/file/titanic_train.csv") a = titanic_survival.groupby('Pclass').agg({'Fare':'sum','Age':'mean'}) print(a)- 1
- 2
- 3
- 4
- 5
- 6
测试记录:

3.6 过滤数据
实际生产中,我们也经常使用pandas来过滤数据,实现sql语句中类似where的操作
3.6.1 过滤null值数据
例如我要提取 泰坦尼克号 数据集中 Cabin 列为空的数据,显示前3行
代码:import pandas as pd import numpy as np titanic_survival = pd.read_csv("E:/file/titanic_train.csv") a = titanic_survival[ titanic_survival['Cabin'].isnull() ] print(a.head(3))- 1
- 2
- 3
- 4
- 5
测试记录:

3.6.2 过滤数据-单条件
例如我要提取 泰坦尼克号 数据集中 Pclass为1的数据,显示前3行
代码:import pandas as pd import numpy as np titanic_survival = pd.read_csv("E:/file/titanic_train.csv") a = titanic_survival[ titanic_survival['Pclass'] == 1 ] print(a.head(3))- 1
- 2
- 3
- 4
- 5
测试记录:

3.6.3 过滤数据-组合条件
- 过滤条件可以进行 与或非
- 过滤的条件超过一个时,需要在每个条件的外面加()
- 运算符不能用 and,or,not 而是用 &,|,!
例如我要提取 泰坦尼克号 数据集中 Pclass为1且Age > 35 的数据,显示前3行
代码:
import pandas as pd import numpy as np titanic_survival = pd.read_csv("E:/file/titanic_train.csv") a = titanic_survival[ (titanic_survival['Pclass'] == 1) & (titanic_survival['Age'] > 35) ] print(a.head(3))- 1
- 2
- 3
- 4
- 5
测试记录:

3.7 数据计算
pandas中具有大量的数据计算函数,比如求和、求平均值、求最大值、最小值、中位数、众数、方差、标准差等。
3.7.1 求和(sum)函数
语法:
DataFrame.sum(axis = None,skipna = None,level = None,numeric_only = None,min_count = 0,**kwargs)- 1
参数说明:
- axis:axis = 1表示行,axis = 0表示列,默认为None(无)
- skipna:布尔型,表示计算结果是否排除NaN/Null值,默认值为None
- level:表示索引层级,默认为None
- numeric_only:仅数字,布尔型,默认值为None
- min_count:表示执行操作所需的数目,整型,默认为0
- **kwargs:要传递给函数的附加关键字参数。
- 返回值:返回Series对象或DataFrame对象。行或列求和数据
代码:
import pandas as pd pd.set_option('display.unicode.east_asian_width',True) data = [[110,105,99],[105,88,115],[109,120,130]] index = [1,2,3] columns =['语文','数学','英语'] df = pd.DataFrame(data = data,index = index,columns=columns) df['总成绩']= df.sum(axis = 1) print(df)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
测试记录:

3.7.2 求均值(mean函数)
语法:
mean(axis=None, skipna=None, level=None, numeric_only=None, **kwargs)- 1
参数说明:
- axis:axis = 1表示行,axis = 0表示列,默认为None(无)
- skipna:布尔型,表示计算结果是否排除NaN/Null值,默认值为None
- level:表示索引层级,默认为None
- numeric_only:仅数字,布尔型,默认值为None
- min_count:表示执行操作所需的数目,整型,默认为0
- **kwargs:要传递给函数的附加关键字参数。
- 返回值:返回Series对象或DataFrame对象。行或列平均值数据
代码:
import pandas as pd pd.set_option('display.unicode.east_asian_width',True) data = [[110,105,99],[105,88,115],[109,120,130],[112,115]] columns =['语文','数学','英语'] df = pd.DataFrame(data = data,columns=columns) new = df.mean() #增加一行数据(语文、数学和英语的平均值,忽略索引) df = df.append(new,ignore_index=True) print(df)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
测试记录:

3.7.3 最大值(max函数)
语法:
max(axis=None, skipna=None, level=None, numeric_only=None, **kwargs)- 1
参数说明:
- axis:axis = 1表示行,axis = 0表示列,默认为None(无)
- skipna:布尔型,表示计算结果是否排除NaN/Null值,默认值为None
- level:表示索引层级,默认为None
- numeric_only:仅数字,布尔型,默认值为None
- min_count:表示执行操作所需的数目,整型,默认为0
- **kwargs:要传递给函数的附加关键字参数。
- 返回值:返回Series对象或DataFrame对象。行或列最大值数据
代码:
import pandas as pd pd.set_option('display.unicode.east_asian_width',True) data = [[110,105,99],[105,88,115],[109,120,130],[112,115]] columns =['语文','数学','英语'] df = pd.DataFrame(data = data,columns=columns) new = df.max() #增加一行数据(语文、数学和英语的最大值,忽略索引) df = df.append(new,ignore_index=True) print(df)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
测试记录:

3.7.4 最小值(min函数)
语法:
min(axis=None, skipna=None, level=None, numeric_only=None, **kwargs)- 1
参数说明:
- axis:axis = 1表示行,axis = 0表示列,默认为None(无)
- skipna:布尔型,表示计算结果是否排除NaN/Null值,默认值为None
- level:表示索引层级,默认为None
- numeric_only:仅数字,布尔型,默认值为None
- min_count:表示执行操作所需的数目,整型,默认为0
- **kwargs:要传递给函数的附加关键字参数。
- 返回值:返回Series对象或DataFrame对象。行或列最小值数据
代码:
import pandas as pd pd.set_option('display.unicode.east_asian_width',True) data = [[110,105,99],[105,88,115],[109,120,130],[112,115]] columns =['语文','数学','英语'] df = pd.DataFrame(data = data,columns=columns) new = df.min() #增加一行数据(语文、数学和英语的最小值,忽略索引) df = df.append(new,ignore_index=True) print(df)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
测试记录:

3.7.5 中位数(median函数)
中位数又叫作中值,按顺序排列的一组数据中位于中间位置的数,其不受异常值的影响。
语法:
median(axis=None, skipna=None, level=None, numeric_only=None, **kwargs)- 1
参数说明:
- axis:axis = 1表示行,axis = 0表示列,默认为None(无)
- skipna:布尔型,表示计算结果是否排除NaN/Null值,默认值为None
- level:表示索引层级,默认为None
- numeric_only:仅数字,布尔型,默认值为None
- min_count:表示执行操作所需的数目,整型,默认为0
- **kwargs:要传递给函数的附加关键字参数。
- 返回值:返回Series对象或DataFrame对象。行或列中位数数据
代码:
import pandas as pd pd.set_option('display.unicode.east_asian_width',True) data = [[110,105,99],[105,88,115],[109,120,130],[112,115]] columns =['语文','数学','英语'] df = pd.DataFrame(data = data,columns=columns) new = df.median() #增加一行数据(语文、数学和英语的中位数,忽略索引) df = df.append(new,ignore_index=True) print(df)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
测试记录:

3.7.6 求众数(mode函数)
众数就是一组数据中出现最多的数,代表了数据的一般水平。
语法:
mode(axis=0, numeric_only=False, dropna=True)- 1
参数说明:
- axis:axis = 1表示行,axis = 0表示列,默认为None(无)
- numeric_only:仅数字,布尔型,默认值为None
- drop_na:是否删除缺失值,布尔型,默认为True
- 返回Series对象或DataFrame对象。
代码:
import pandas as pd data = [[110,120,110],[130,130,130],[130,120,130]] columns = ['语文','数学','英语'] df = pd.DataFrame(data = data ,columns=columns) print(df.mode())#三科成绩的众数 print(df.mode(axis = 1))#每一行的众数 print(df['数学'].mode())#'数学'成绩的众数- 1
- 2
- 3
- 4
- 5
- 6
- 7
测试记录:

3.7.7 方差(var函数)
方差是用来反映数据的离散程度的,是各组数据与他们平均数的差的平方,方差越小越稳定。
语法:
var(axis=None, skipna=None, level=None, ddof=1, numeric_only=None, **kwargs)- 1
参数说明:
- axis:axis = 1表示行,axis = 0表示列,默认为None(无)
- skipna:布尔型,表示计算结果是否排除NaN/Null值,默认值为None
- level:表示索引层级,默认为None
- ddof:整型,默认值为1.自由度,计算中使用的除数是N-ddof,其中N表示元素的数量。
- numeric_only:仅数字,布尔型,默认值为None
- **kwargs:要传递给函数的附加关键字参数。
- 返回值:返回Series对象或DataFrame对象。
代码:
import pandas as pd data = [[110,113,102,105,108],[118,98,119,85,118]] index = ['小黑','小白'] columns = ['物理1','物理2','物理3','物理4','物理5'] df = pd.DataFrame(data = data,index = index,columns=columns) print(df.var(axis = 1))- 1
- 2
- 3
- 4
- 5
- 6
测试记录:

3.7.8 标准差(std函数)
标准差是方差的平方根,用来表示数据的离散程度。
语法:
std(axis=None, skipna=None, level=None, ddof=1, numeric_only=None, **kwargs)- 1
参数与var一样。
代码:
import pandas as pd data = [[110,120,110],[130,130,130],[130,120,130]] columns = ['语文','数学','英语'] df = pd.DataFrame(data = data ,columns=columns) print(df.std())- 1
- 2
- 3
- 4
- 5
测试记录:

3.7.9 分位数(quantile函数)
分位数是以概率依据将数据分割为几个等分,常用的有中位数(即二分位数)、四分位数、百分位数等。
语法:
quantile(q=0.5, axis=0, numeric_only=True, interpolation='linear')- 1
参数说明:
-
q:浮点型或数组,默认为0.5(50%分位数),其值为0~1
-
axis:axis = 1表示行,axis = 0表示列,默认为None(无)
-
numeric_only:仅数字,布尔型,默认值为True
-
interpolation:内插值,可选参数,用于指定要使用的插值方法,当期望的分位数为数据点i~j时。
4.1 线性:i+(j-i)*分数,其中分数是指数被i和j包围的小数部分。
4.2 较低:i
4.3 较高:j
4.4 最近:i或j二者以最近者为准
4.5 中点:(i+j)/2
4.6 返回值:返回Series对象或DataFrame对象。
代码:
import pandas as pd #创建DataFrame数据(数学成绩) data = [120,89,98,78,65,102,112,56,79,45] columns = ['数学'] df = pd.DataFrame(data = data,columns=columns) #计算35%的分位数 x = df['数学'].quantile(0.35) #输出淘汰 print(df[df['数学']<=x])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
测试记录:

3.7.10 相关系数(corr)函数
#计算任意两列之间的相关系数 data.corr() # 计算某一列与其它所有列的相关系数 data.corr()['col_name'] #计算两个列之间的相关系数 data['col1'].corr( data['col2'])- 1
- 2
- 3
- 4
- 5
- 6
需求:
我们现在需要知道 泰坦尼克号 所有列与 是否生还的相关性代码:
测试记录:
可以看到只显示了 数值列

3.8 merge合并操作
Pandas 提供的 merge() 函数能够进行高效的合并操作,这与 SQL 关系型数据库的 MERGE 用法非常相似。从字面意思上不难理解,merge 翻译为“合并”,指的是将两个 DataFrame 数据表按照指定的规则进行连接,最后拼接成一个新的 DataFrame 数据表。
merge() 函数的法格式如下:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,left_index=False, right_index=False, sort=True,suffixes=('_x', '_y'), copy=True)- 1
- 2
- 3
参数说明,如下表所示:

3.8.1 在单个键上进行合并操作
代码:
import pandas as pd left = pd.DataFrame({ 'id':[1,2,3,4], 'Name': ['Smith', 'Maiki', 'Hunter', 'Hilen'], 'subject_id':['sub1','sub2','sub4','sub6']}) right = pd.DataFrame({ 'id':[1,2,3,4], 'Name': ['William', 'Albert', 'Tony', 'Allen'], 'subject_id':['sub2','sub4','sub3','sub6']}) print ("########################################") print (left) print ("########################################") print (right) #通过on参数指定合并的键 print ("########################################") print(pd.merge(left,right,on='id'))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
测试记录:

3.8.2 在多个键上进行合并操作
代码:
import pandas as pd left = pd.DataFrame({ 'id':[1,2,3,4], 'Name': ['Smith', 'Maiki', 'Hunter', 'Hilen'], 'subject_id':['sub1','sub2','sub4','sub6']}) right = pd.DataFrame({ 'id':[1,2,3,4], 'Name': ['Bill', 'Lucy', 'Jack', 'Mike'], 'subject_id':['sub2','sub4','sub3','sub6']}) print(pd.merge(left,right,on=['id','subject_id']))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
测试记录:

3.8.3 使用how参数合并
通过how参数可以确定 DataFrame 中要包含哪些键,如果在左表、右表都不存的键,那么合并后该键对应的值为 NaN。为了便于大家学习,我们将 how 参数和与其等价的 SQL 语句做了总结:

代码:
import pandas as pd left = pd.DataFrame({ 'id':[1,2,3,4], 'Name': ['Smith', 'Maiki', 'Hunter', 'Hilen'], 'subject_id':['sub1','sub2','sub4','sub6']}) right = pd.DataFrame({ 'id':[1,2,3,4], 'Name': ['Bill', 'Lucy', 'Jack', 'Mike'], 'subject_id':['sub2','sub4','sub3','sub6']}) #以left侧的subject_id为键 print(pd.merge(left,right,on='subject_id',how="left"))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
测试记录:

3.9 pivot数据透视表
pandas作为编程领域最强大的数据分析工具之一,自然也有透视表的功能。
在pandas中,透视表操作由pivot_table()函数实现,不要小看只是一个函数,但却可以玩转数据表,解决大麻烦。
pivot_table使用方法:
pandas.pivot_table(*data*, *values=None*, *index=None*, *columns=None*, *aggfunc='mean'*, *fill_value=None*, *margins=False*, *dropna=True*, *margins_name='All'*, *observed=False*)- 1
参数解释:
- data:dataframe格式数据
- values:需要汇总计算的列,可多选
- index:行分组键,一般是用于分组的列名或其他分组键,作为结果DataFrame的行索引
- columns:列分组键,一般是用于分组的列名或其他分组键,作为结果DataFrame的列索引
- aggfunc:聚合函数或函数列表,默认为平均值
- fill_value:设定缺失替换值
- margins:是否添加行列的总计
- dropna:默认为True,如果列的所有值都是NaN,将不作为计算列,False时,被保留
- margins_name:汇总行列的名称,默认为All
- observed:是否显示观测值
代码:
import pandas as pd import numpy as np titanic_survival = pd.read_csv("E:/file/titanic_train.csv") port_stats = titanic_survival.pivot_table(index="Embarked", values=["Fare","Survived"], aggfunc=np.sum) print(port_stats)- 1
- 2
- 3
- 4
- 5
- 6
测试记录:

3.10 时间操作
时间类型的列 dt操作 object类型的列str操作 data['日期'] =df['交易时间'].dt.date data['时间'] =df['交易时间'].dt.time data['年'] = df['交易时间'].dt.year data['季节'] = df['交易时间'].dt.quarter data['月'] = df['交易时间'].dt.month data['周']=df['交易时间'].dt.week data['日'] = df['交易时间'].dt.day data['小时'] =df['交易时间'].dt.hour data['分钟'] =df['交易时间'].dt.minute data['秒'] = df['交易时间'].dt.second data['一年第几天'] =df['交易时间'].dt.dayofyear data['一年第几周'] = df['交易时间'].dt.isocalendar().week data['一周第几天'] = df['交易时间'].dt.dayofweek data['一个月含有多少天'] = df['交易时间'].dt.days_in_month data['星期名称'] =df['交易时间'].dt.day_name()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
代码:
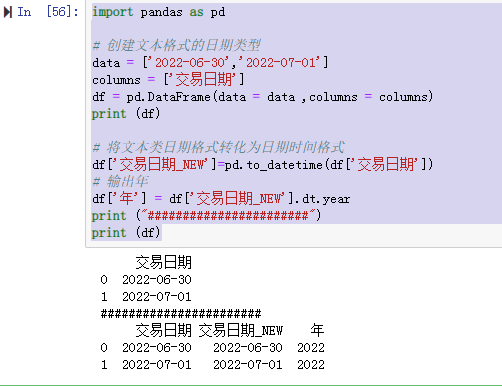
import pandas as pd # 创建文本格式的日期类型 data = ['2022-06-30','2022-07-01'] columns = ['交易日期'] df = pd.DataFrame(data = data ,columns = columns) print (df) # 将文本类日期格式转化为日期时间格式 df['交易日期_NEW']=pd.to_datetime(df['交易日期']) # 输出年 df['年'] = df['交易日期_NEW'].dt.year print ("#######################") print (df)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
测试记录:
3.11 apply 自定义函数
代码:
import pandas as pd import numpy as np titanic_survival = pd.read_csv("E:/file/titanic_train.csv") def which_class(row): pclass = row['Pclass'] if pd.isnull(pclass): return "Unknown" elif pclass == 1: return "First Class" elif pclass == 2: return "Second Class" elif pclass == 3: return "Third Class" classes = titanic_survival.apply(which_class, axis=1) print (classes)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
测试记录:

3.12 字符串操作
3.12.1 字符串大小写及长度
代码:
import pandas as pd import numpy as np s = pd.Series(['A', 'c', 'AGeR', 'SEW', np.nan]) print (s) print ("#####################################") # 大写 print (s.str.upper()) print ("#####################################") # 小写 print (s.str.lower()) print ("#####################################") # 字符串长度 print (s.str.len())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
测试记录:

3.12.2 字符串的替换操作
代码:
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(3, 2), columns=['A a', 'B b'], index=range(3)) print (df) # 将属性名中的空格去除 print ("##########################################") df.columns = df.columns.str.replace(' ', '') print (df)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
测试记录:

3.12.3 字符串切分
代码:
import pandas as pd import numpy as np se = pd.Series(['a_b_c', 'x_y_z', 'p_q_t']) print (se) print ("###############################################") # 按指定字符切分 全切 不计次数 print (se.str.split('_')) print ("###############################################") # 只能切分一次 print (se.str.split('_', 1))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
测试记录:

3.12.4 包含关系
代码:
import pandas as pd import numpy as np ser = pd.Series(['A', 'c', 'AGeR', 'SEW', np.nan]) print (ser.str.contains('A'))- 1
- 2
- 3
- 4
- 5
测试记录:

四. pandas之Series数据结构实操
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)- 1
参数说明:
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从 0 开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
代码:
import pandas as pd a = [1, 2, 3] myvar = pd.Series(a) print(myvar)- 1
- 2
- 3
- 4
- 5
- 6
测试记录:

参考:
- https://study.163.com/course/introduction.htm?courseId=1003590004#/courseDetail?tab=1
- https://www.jianshu.com/p/3b2c3876691b
- https://blog.csdn.net/ccc369639963/article/details/124270988
- https://blog.csdn.net/D_Low/article/details/123768282
-
相关阅读:
c++实现键盘hook
安卓讲课笔记6.1 共享参数
“萝卜快跑”仍然存在出现多处高危网络安全问题
职场题:有一件特别紧急的事,群众要办理,且联系不上领导,你怎么办?(1)
搜索。。。
【数据结构】双向带头循环链表的实现
雪莱的式子武汉2023(分析+快速幂)
解决 webpack 配置 sass-loader后报错,无法正常build
反编译正常回编译出现问题自己解决办法
基于STM32的智能家居控制系统设计与实现(带红外遥控控制空调)
- 原文地址:https://blog.csdn.net/u010520724/article/details/125632890