-
Spark实现TopN
申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计3132字,阅读大概需要3分钟1. 实验室名称:
大数据实验教学系统
2. 实验项目名称:
练习 Spark实现TopN
3. 实验学时:
4. 实验原理:
因为Spark RDD是分区并行计算的,因此要排序的话,需要指定一个分区。
使用sortByKey算子,按key排序,然后再使用take算子,取前几个元素,就得到了 Top N 的结果。5. 实验目的:
掌握抓取文本中最大的前几位数字。
掌握排序算子的使用。6. 实验内容:
1、使用Spark RDD实现 Top N。
假设我们有以下输入文件top.txt:1. 2 2. 6 3. 3 4. 67 5. 23 6. 45 7. 78 8. 12 9. 234- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
编写RDD代码,获取值最大的三个数(Top 3)。
2、使用Spark RDD实现分组 Top N。
假设我们有以下输入文件classdata.txt:1. class1 90 2. class2 56 3. class3 87 4. class1 76 5. class2 88 6. class1 95 7. class1 74 8. class2 87 9. class2 67 10. class2 77- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
编写RDD代码,获取每个班级的前三名(分组Top 3)。
7. 实验器材(设备、虚拟机名称):
硬件:x86_64 ubuntu 16.04服务器
软件:JDK 1.8,Spark-2.3.2,Hadoop-2.7.3,zeppelin-0.8.1,Scala-2.11.118. 实验步骤:
8.1 启动Spark集群
在终端窗口下,输入以下命令,启动Spark集群:
1. $ cd /opt/spark 2. $ ./sbin/start-all.sh- 1
- 2
然后使用jps命令查看进程,确保Spark的Master进程和Worker进程已经启动。
8.2 启动zeppelin服务器
在终端窗口下,输入以下命令,启动zeppelin服务器:
1. $ zeppelin-daemon.sh start- 1
然后使用jps命令查看进程,确保zeppelin服务器已经启动。
8.3 创建notebook文档
1、首先启动浏览器,在地址栏中输入以下url地址,连接zeppelin服务器。
http://localhost:9090
2、如果zeppelin服务器已正确建立连接,则会看到如下的zeppelin notebook首页。
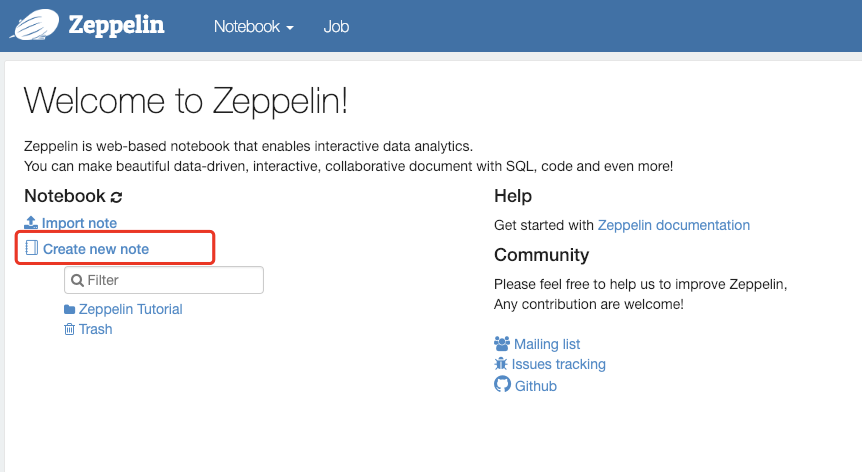
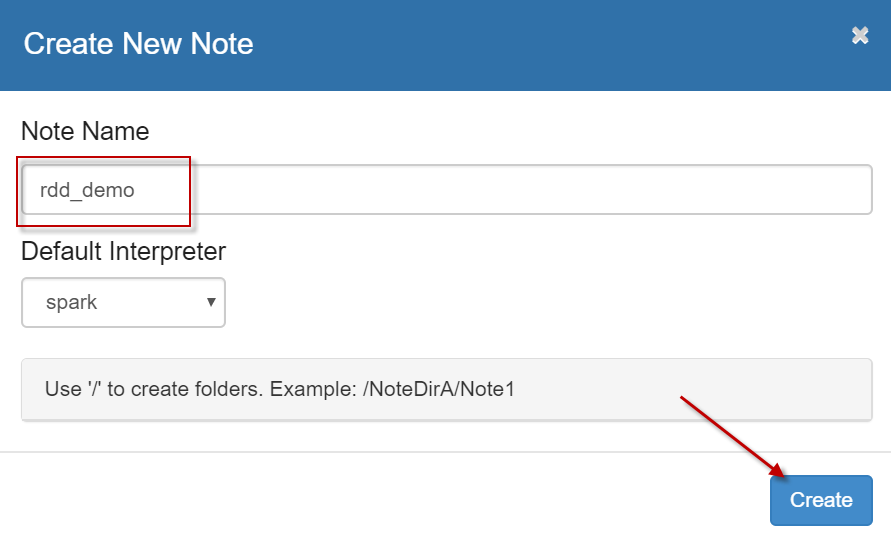
3、点击【Create new note】链接,创建一个新的笔记本,并命名为”rdd_demo”,解释器默认使用”spark”,如下图所示。
8.4 Top N 实现
1、加载数据集。在zeppelin中执行如下代码。
1. val inputPath = "file:///data/dataset/top.txt" 2. val inputRDD = sc.textFile(inputPath)- 1
- 2
将光标放在代码单元中任意位置,然后同时按下【shift+enter】键,执行以上代码。
2、实现Top N,方法是先将每行的数字转换为元组,然后再执行sortByKey降序排序,最后使用take(3)方法取最前面的3个。在zeppelin中执行如下代码。1. // 读取文件。注意,这里指定一个RDD分区,以便全局排序 2. val lines = sc.textFile("file:///data/dataset/top.txt",1) 3. 4. // 对linesRDD进行map操作 5. val pairs = lines.map { line => (line.toInt,line) } 6. 7. // 对pairsRDD进行降序sortByKey操作 8. val sortedPairs = pairs.sortByKey(false) 9. 10. // 对降序的RDD再次进行map操作,获取每一行的第一个数 11. val sortedNumbers = sortedPairs.map(sortedPair => sortedPair._1) 12. 13. // 取前3个数 14. val top3Number = sortedNumbers.take(3) 15. 16. // 打印输出 17. for(num <- top3Number){ 18. println(num) 19. }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
将光标放在代码单元中任意位置,然后同时按下【shift+enter】键,执行以上代码。输出结果如下所示。
1. 234 2. 78 3. 67- 1
- 2
- 3
8.5 分组 Top N 实现
1、加载数据集。在zeppelin中执行如下代码。
1. val inputPath = "file:///data/dataset/classdata.txt" 2. val inputRDD = sc.textFile(inputPath)- 1
- 2
将光标放在代码单元中任意位置,然后同时按下【shift+enter】键,执行以上代码。
2、实现Top N,方法是先将每行的数字转换为元组,然后再执行sortByKey降序排序,最后使用take(3)方法取最前面的3个。在zeppelin中执行如下代码。1. // 对获取的元素进行按空格切割成两部分 2. val pairs = inputRDD.map { line => (line.split(" ")(0),line.split(" ")(1).toInt) } 3. 4. // 对pairs中的每个元素进行按键分组操作 5. val grouped=pairs.groupByKey 6. 7. // 对分组的元素按分数取前3 8. val groupedTop3=grouped.map(grouped=> { 9. (grouped._1,grouped._2.toList.sortWith(_>_).take(3)) 10. }) 11. 12. // 进行降序排列(默认是降序) 13. val groupedKeySorted = groupedTop3.sortByKey() 14. 15. // 打印输出 16. groupedKeySorted 17. .collect 18. .foreach(pair=>{ 19. println(pair._1+":") 20. pair._2.foreach { println } 21. })- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
将光标放在代码单元中任意位置,然后同时按下【shift+enter】键,执行以上代码。输出结果如下所示。
1. class1: 2. 95 3. 90 4. 76 5. class2: 6. 88 7. 87 8. 77 9. class3: 10. 87- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
9. 实验结果及分析:
实验结果运行准确,无误
10. 实验结论:
经过本节实验的学习,通过练习 Spark实现TopN,进一步巩固了我们的Spark基础。
11. 总结及心得体会:
使用sortByKey算子,按key排序,然后再使用take算子,取前几个元素,就得到了 Top N 的结果。

-
相关阅读:
开发问题总结
发现区块链世界的新大门——AppBag.io DApp导航网站全面解析
开源大模型RAG企业本地知识库问答机器人-ChatWiki
LLaMA参数微调方法
学好C语言需要一定的学习和实践
CleanMyMacX4.11.3最新版mac电脑磁盘清理工具功能
JavaFx自定义事件
常用的git命令(实用)
Java入门基础第5天Java程序的执行流程/运行过程
Android:利用sdk中的build-tools对包进行签名
- 原文地址:https://blog.csdn.net/qq_44807756/article/details/125570212
