-
Elasticsearch 入门到精通-ElasticSearch技术原理之倒排索引的数据结构
1、Elasticsearch倒排索引的精髓
倒排索引压缩储存空间,减少磁盘读取次数;严格储存结构,节省搜索时间。
简单的来说,Elasticsearch将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用极其苛刻的态度使用内存。
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地来讲,正向索引是通过key找value,反向索引则是通过value找key。
Elasticsearch能够通过倒排索引来达到实时、高效的搜索是怎么实现的呢?下面我从时间和空间的概念来谈谈倒排索引的原理。
先来回忆一下我们是怎么插入几条索引记录的:
- POST _bulk
- {
- "index": {
- "_index": "school",
- "_id": "1"
- }
- }
- {
- "stuName": "Rose",
- "age": 24,
- "gender": "Male"
- }
- {
- "index": {
- "_index": "school",
- "_id": "2"
- }
- }
- {
- "stuName": "John",
- "age": 24,
- "gender": "Female"
- }
- {
- "index": {
- "_index": "school",
- "_id": "3"
- }
- }
- {
- "stuName": "Bill",
- "age": 29,
- "gender": "Female"
- }
其实就是直接PUT一个JSON的对象,这个对象有多个字段,在插入这些数据到索引的同时,Elasticsearch还为这些字段建立索引——倒排索引,因为Elasticsearch最核心功能是搜索。
创建了如下三条数据
ID stuName age gender 1 Rose 24 Male 2 John 24 Female 3 Bill 29 Female 每个字段对于的倒排索引的信息
stuName
Term Posting List Rose 1 John 2 Bill 3 age
Term Posting List 24 [1,2] 29 [3] gender
Term Posting List Female 1 Male [2,3] 那么,倒排索引是个什么样子呢?

Posting List
Posting List是Elasticsearch中为每个字段field自动提供的索引集合,比方说24,29 这些叫做 term,而 [1,2] 就是 posting list。Posting list 就是一个 int 的数组,存储了所有符合某个 term 的文档 id。Term Dictionary
Elasticsearch中为了能够快速的找到某个term,也就是我们经常用某个字段来快速查询,为了实现这一功能,Term Dictionary就产生了。Term Dictionary的实现底层就是B+Tree,使用二分法进行查询term, logN 次磁盘查找效率,就像字典查询一样,首字母是什么,就先检索什么,然后再看第二个字母是什么,检索第二个字母,…,一直到检索到这个term为止。Term Index
由于磁盘随机读的存在,就必须将一部分数据存在缓存内存中,但是Term Dictionary磁盘存储空间的巨大,又不能将Term Dictionary完整的放到内存里。因此就有了Term Index,它就像字典里一个更大的章节一样,每个大的章节再对应着多个小的章节Term Dictionary,这样就能实现速的找到某个term。Term Index、Term Dictionary和Posting List个关系
如下图 所示:“A”, “to”, “tea”, “ted”, “ten”, “i”, “in”, 和 “inn” 这些单词是如何储存在Elasticsearch里的呢?Term Index就像一棵倒挂的树一样,它就是这棵树的根节点,也就是这本字典;Term Dicitionary是根节点的子节点,存放着“t”、“A”、“i”,也就是所储存单词的前缀;然后Posting List就是相同前缀的单词(term)集合,里面装着我们要检索的单词(term)。因此通过 term index能够快速精确的检索到我们所需要的term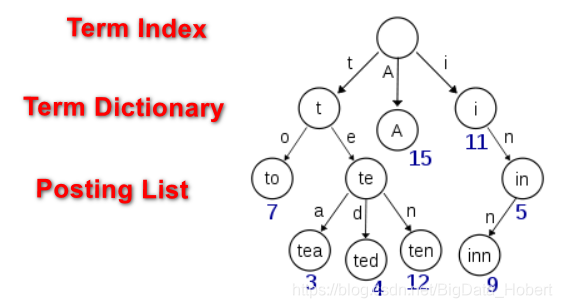
-
相关阅读:
mysql中的between边界问题
绍兴市越城区人大常委会主任徐荻一行莅临迪捷软件调研指导
猿创征文|为了练习自己的Python基础语法,我用pygame写了一个打砖块闯关的游戏
重构之美:Java Swing中 如何对指定行文本进行CSS样式渲染,三种实现思路分享
DBCO-PEG3-Maleimide,Mal-PEG3-DBCO,二苯并环辛炔-三聚乙二醇-马来酰亚胺
YOLOv5改进 | 独家创新篇 | 利用DCNv3结合DLKA形成全新的注意力机制(全网独家创新)
使用 C++ 部署深度学习模型快速上手方案
基于ZYNQ的PCIE高速数据采集卡的设计(一)
【生信分析】基于TCGA肿瘤数据进行基因共表达网络分析
C语言笔记(六)
- 原文地址:https://blog.csdn.net/wangguoqing_it/article/details/125362267
