-
机器学习实战读书笔记——机器学习概览
机器学习的应用示例
- 分析生产线上的产品图像来对产品进行自动分类
- 图像分类问题,使用卷积神经网络CNN
- 通过脑部扫描发现肿瘤
- 语义分割,图像中的每个像素都需要被分类,也是用CNN
- 自动分类新闻、恶意评论标记、长文总结
- 自然语言处理(NLP),更具体的是文本分类,可以使用循环神经网络(RNN)、CNN或者Transformer
- 基于很多性能指标预测来年收入
- 回归问题,需要回归模型进行处理,例如线性回归或多项式回归、SVM回归、随机森林回归或i在人工神经网络;如果考虑过去的性能指标,可以使用RNN、CNN或者Transformer
- 让应用对语音命令做出反应
- 语音识别,一般使用RNN、CNN或者Transformer处理
- 检测信用卡欺诈
- 异常检测
- 基于客户的购买记录对客户分类,针对每一类客户设定不同的市场策略
- 聚类问题
- 基于以前的购买记录给客户推荐可能感兴趣的产品
- 推荐系统,可以使用人工神经网络训练
- 为游戏建造智能机器人
- 通常通过强化学习(RL)解决
机器学习系统的类型
- 是否在人类的监督下训练
- 有监督学习
- 无监督学习
- 半监督学习
- 强化学习
- 是否可以动态地进行增量学习
- 在线学习
- 批量学习
- 是简单的将新数据点和已知数据点进行匹配还是对训练数据进行模式检测然后建立一个预测模型
- 基于实例的学习
- 基于模型的学习
有监督学习
在该类学习中,提供给算法的包含所需解决方案的训练集称为标签,分类任务和回归问题是典型的有监督学习。有一些重要的有监督学习算法:
- K近邻算法
- 线性回归
- 逻辑回归
- 支持向量机SVM
- 决策树和随机森林
- 神经网络


无监督学习
无监督学习的训练数据都是未经标记的,有以下重要算法:
- 聚类算法
- K均值算法
- DBSCAN
- 分类聚类分析HCA
- 异常检测和新颖性检测
- 单类SVM
- 孤立森林
- 可视化和降维
- 主成分分析PCA
- 核主成分分析
- 局部线性嵌入
- T分布随机近邻嵌入
- 关联规则学习
- Apriori
- Eclat


半监督学习
由于通常给数据做标记是非常耗时和昂贵的,因此会有很多未标记的数据而很少有已经标记的数据。这称为半监督学习。大部分半监督学习算法是无监督算法和有监督算法的结合。
强化学习
其学习系统能够观察环境、做出选择,执行动作并获得回报。所以必须自行学习什么是最好的策略,从而随着时间的推移获得最大的回报。

批量学习
在批量学习中,系统无法进行增量学习——即必须使用所有可用数据进行训练。因此通常都是离线完成:先训练系统然后投入其生产环境。
如果希望批量学习系统学习新数据,只能在之前的训练数据集的基础上加上新数据重新训练系统的新版本,然后取代旧系统。
在线学习
可用循序渐进的给系统提供训练数据,逐步累积学习成果,这种提供数据的方式可以是单独的,也可以是小批量的小组数据进行训练。在线学习中,模型经过训练并投入生产环境,然后随着新数据的进入而不断学习。

在线学习系统的一个重要参数是其适应不断变化的数据的速度,即学习率。如果学习率过高,系统会迅速适应新数据,但同时会更快忘记旧数据。反过来如果学习率过低,系统会有更高的惰性,面对新数据中的噪声和离群值更不敏感。
基于实例的学习
系统用心学习给好的示例,然后通过使用相似度度量来比较新实例和已经学习的实例(或其子集),从而泛化新实例。
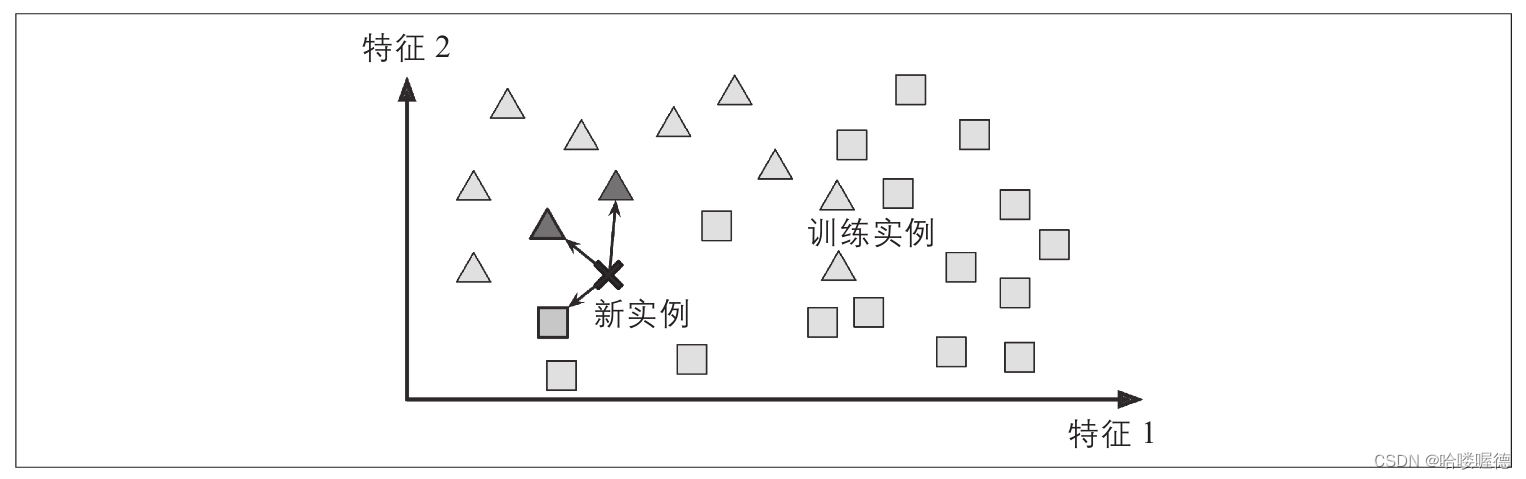
基于模型的学习
从一组示例集中实现泛化的另一种方法就是构建这些示例的模型,然后使用该模型进行预测。

- 分析生产线上的产品图像来对产品进行自动分类
-
相关阅读:
VS2022 性能提升:更快的 C++ 代码索引
[附源码]SSM计算机毕业设计疫情期间物资分派管理系统JAVA
使用纯c#在本地部署多模态模型,让本地模型也可以理解图像
基于显扬科技自主研发3D机器视觉HY-M5在物流行业包裹分拣中的应用
干洗店洗鞋店线上下单小程序方便快捷
C++之多态
创建型-建造者模式
许可分析 license分析 第十六章
正版软件 | DupInOut Duplicate Finder:智能清理,让数据井然有序
射频微波芯片设计2:滤波器芯片
- 原文地址:https://blog.csdn.net/YCF8746/article/details/125488226