-
【深度学习理论】(6) 循环神经网络 RNN
大家好,今天和各位分享一下处理序列数据的循环神经网络RNN的基本原理,并用 Pytorch 实现 RNN 层和 RNNCell 层。
之前的博文中已经用过循环神经网络做过许多实战案例,感兴趣的可以看我这个专栏:https://blog.csdn.net/dgvv4/category_11712004.html
1. 序列的表示方法
在循环神经网络中,序列数据的 shape 通常是 [batch, seq_len, feature_len],其中 seq_len 代表特征的个数,feature_len 代表每个特征的表示方法。
对于自然语言任务: 以 shape=[b, 5, 100] 为例,其中 5 代表每句话有 5 个单词,而 100 代表每个单词使用一个长度为 100 的向量来表示。
对于时间序列任务: 以 shape=[b, 100, 1] 为例,其中 100 代表每个 batch 统计了 100 天的数据,每天有 1 个气温值。
下面以语言的情感分析任务为例,向大家介绍处理序列数据的传统方法,如下图:

现在有一个句子 The flower is so beautiful 作为输入,通过 wordembedding 将每个单词用一个长度为 100 的向量来表示,然后将每个单词输入至线性层提取特征,每个单词的输出结果是一个长度为 2 的向量,最后将所有单词聚合起来,经过一个线性层输出得到分类结果。
传统的序列处理方法存在许多缺陷:
(1)计算量庞大。现实生活中的单词量巨大,对每个单词生成一个线性层 x@w+b 提取特征,然后再对线性层输出结果做聚合,模型非常复杂,参数量极其庞大。
(2)没有考虑上下文语境。传统方法只是针对一句话中的每个单词做单独的分析,没有联系前后单词之间的信息。如:i do not think the flower is beautiful 句子中,不能看到 beautiful 就说这句话一定是好评,要联系到上文的 not 再做分析。
2. RNN 原理解析
针对传统序列任务模型存在的问题,RNN做出了改进:
(1)优化参数量。通过权值共享,把每个单词的 w1、w2、w3... 用一个张量 W 来表示,一个RNN层就处理一整个句子。
(2)联系上下文语境。使用一个时序单元处理上下文信息,当前时刻的输入一定要考虑到上一时刻的输出。
下面仍以语言的情感分析任务为例,向大家介绍RNN的基本原理。
RNN单元的计算公式为:
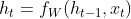
其中,
 代表当前时刻的输入特征;
代表当前时刻的输入特征; 代表上一时刻的输出,也是上一时刻聚合后的语境信息;
代表上一时刻的输出,也是上一时刻聚合后的语境信息;接下来把公式展开:

其中,
 代表对当前时刻输入的特征提取,
代表对当前时刻输入的特征提取, 代表对之前语境信息的特征提取,然后对计算结果使用 tanh 激活函数,得到本时刻更新后的语境信息
代表对之前语境信息的特征提取,然后对计算结果使用 tanh 激活函数,得到本时刻更新后的语境信息 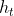

3. RNN 的梯度推导
下面以时间序列预测任务为例,向大家介绍一下 RNN 的梯度更新方式,如下图。
取 RNN 层的最后一个语境信息 ht 作为预测结果输出。predict 代表前向传播得出的预测值,target 代表真实值,损失函数为预测值和真实值的均方误差MSE。
前向传播:
线性变换:

损失函数:


通过损失函数值更新每个时刻的语境的梯度信息
反向传播公式:

分别对每个分式计算偏微分:




其中:

4. 模型结构
下面向大家介绍一下 RNN 层的结构,各个输入和输出张量的 shape
首先,网络输入的 shape 为 [seq_len, batch, feature_len]。其中 seq_len 代表特征的个数,batch 代表有多少个句子,feature_len 代表每个特征的向量表示,hidden_len 代表 RNN 单元的隐含层神经元个数。

以 batch=3,seq_len=10,feature_len=100,hidden_len=20 为例,向大家介绍网络的输入和输出的特征的 shape 变化
RNN 层的公式:

shape 变化为:
![[batch, feature len] @ [hidden len, feature len]^{T} + [batch, hidden len ] @ [hidden len, hidden len]^{T}](https://1000bd.com/contentImg/2022/06/25/234427728.gif)
带入具体数值:
![[3, 100] @ [20, 100]^{T} + [3, 20] @ [20, 20]^{T} = [3,20] + [3,20] = [3,20]](https://1000bd.com/contentImg/2022/06/25/234432258.gif)
下面在Pytorch中展示单个RNN层的参数的shape
- import torch
- from torch import nn
- # 100代表feature_len每个单词的向量表示的长度
- # 20代表hidden_len经过RNN层之后每个单词的向量表示长度变成20
- rnn = nn.RNN(100, 20)
- # 查看RNN单元的参数
- print(rnn._parameters.keys())
- # 查看每个参数的shape
- print('W_xh:', rnn.weight_ih_l0.shape,
- 'bias_xh:', rnn.bias_ih_l0.shape,
- 'W_hh:', rnn.weight_hh_l0.shape,
- 'bias_hh:', rnn.bias_hh_l0.shape)
- '''
- 输出结果:
- odict_keys(['weight_ih_l0', 'weight_hh_l0', 'bias_ih_l0', 'bias_hh_l0'])
- W_xh: torch.Size([20, 100])
- bias_xh: torch.Size([20])
- W_hh: torch.Size([20, 20])
- bias_hh: torch.Size([20])
- '''
5. Pytorch 代码实现
5.1 单层 RNN 实现
首先需要实例化一个RNN层
input_size:用多少长的向量来表示一个单词。
hidden_size:经过RNN层特征提取后
,每个单词用多少长的向量表示。num_layers:共有多少层RNN。
rnn = nn.RNN(input_size, hidden_size, num_layers)前向传播函数
x:当前时刻的输入特征,shape = [seq_len, batch, feature_len]
h0:上一时刻的语境信息,shape = [num_layers, batch, hidden_size]
out:最后一个时刻的输出结果,shape = [seq_len, batch, hidden_len]
h:所有时刻的语境状态,shape = [num_layers, batch, hidden_size]
out, h = rnn(x, h0)以 batch=3,seq_len=10,feature_len=100,hidden_len=20 为例,单个RNN层的代码如下:
- import torch
- from torch import nn
- # input_size:代表每个单词的向量表示的长度
- # hidden_size:代表特征提取后,每个单词的向量表示长度
- # num_layers:代表RNN的层数
- rnn = nn.RNN(input_size=100, hidden_size=20, num_layers=1) # 实例化单层的RNN层
- # 构造输入层shape=[seq_len, batch, feature_len]
- x = torch.randn(10, 3, 100)
- # 构造上一时刻的语境shape=[num_layers, batch, hidden_size]
- h0 = torch.randn(1, 3, 20)
- # 前向传播的返回值如下
- # out:代表每个时刻的h的输出结果shape=[seq_len, batch, hidden_len]
- # h:代表最后一个时刻的输出结果shape=[num_layers, batch, hidden_size]
- out, h = rnn(x, h0)
- print('out:', out.shape, 'h:', h.shape)
- '''
- 输出结果
- out: torch.Size([10, 3, 20])
- h: torch.Size([1, 3, 20])
- '''
5.2 多层 RNN 实现
参数和上面相同,这里要注意的就是在前向传播的输出结果中,h 代表在最后一个时刻上看之前的所有语境信息,而 out 代表每个RNN层的输出结果。
4层的RNN代码如下:
- import torch
- from torch import nn
- # input_size:代表每个单词的向量表示的长度
- # hidden_size:代表特征提取后,每个单词的向量表示长度
- # num_layers:代表RNN的层数
- rnn = nn.RNN(input_size=100, hidden_size=20, num_layers=4) # 实例化4层的RNN层
- # 构造输入层shape=[seq_len, batch, feature_len]
- x = torch.randn(10, 3, 100)
- # 构造初始时刻的语境shape=[num_layers, batch, hidden_size]
- h0 = torch.randn(4, 3, 20)
- # out:代表每个时刻的h的输出结果shape=[seq_len, batch, hidden_len]
- # h:代表最后一个时刻的输出结果shape=[num_layers, batch, hidden_size]
- out, h = rnn(x, h0)
- print('out:', out.shape, 'h:', h.shape)
- '''
- out: torch.Size([10, 3, 20])
- h: torch.Size([4, 3, 20])
- '''
5.3 单层 RNNCell 实现
nn.RNN 是将所有句子全部都输入至RNN层中,而 nn.RNNCell 需要手动输入每个句子,并且当前时刻的输出状态不会自动进入到下一时刻。单个RNNCell结构如下。

实现过程如下:
- import torch
- from torch import nn
- # input_size:代表每个单词的向量表示的长度
- # hidden_size:代表特征提取后,每个单词的向量表示长度
- rnncell = nn.RNNCell(input_size=100, hidden_size=20) # 实例化单层的RNNcell层
- # 构造输入层shape=[seq_len, batch, feature_len]
- inputs = torch.randn(10, 3, 100)
- # 构造初始时刻的语境shape=[batch, hidden_size]
- h0 = torch.randn(3, 20)
- # RNNCell的输入shape=[batch, feature_len]
- for x in inputs:
- # h0:代表当前时刻的语境信息shape=[batch, hidden_len]
- h0 = rnncell(x, h0)
- print('h0:', h0.shape)
- '''
- h0: torch.Size([3, 20])
- '''
5.4 多层的 RNNCell 实现
以两层的 RNNCell 实现为例

第一个 RNNCell 层将每个单词的向量表示长度从 100 变成 20,第二个 RNNCell 层将每个单词的向量表示长度从 20 变成 15。
第一个 RNNCell 的输入是当前时刻的单词和上一时刻的语境状态h0,第二个 RNNCell 的输入是第一个 RNNCell 的输出和上一时刻的语境状态h1。
代码实现如下:
- import torch
- from torch import nn
- # input_size:代表每个单词的向量表示的长度
- # hidden_size:代表特征提取后,每个单词的向量表示长度
- rnncell1 = nn.RNNCell(input_size=100, hidden_size=20) # 实例化单层的RNNcell层
- rnncell2 = nn.RNNCell(input_size=20, hidden_size=15)
- # 构造输入层shape=[seq_len, batch, feature_len]
- inputs = torch.randn(10, 3, 100)
- # 构造初始时刻的语境shape=[batch, hidden_size]
- h0 = torch.randn(3, 20)
- h1 = torch.randn(3, 15)
- # RNNCell的输入shape=[batch, feature_len]
- for x in inputs:
- # h0:代表当前时刻的语境信息shape=[batch, hidden_len]
- h0 = rnncell1(x, h0)
- h1 = rnncell2(h0, h1)
- print('h1:', h1.shape)
- '''
- h1: torch.Size([3, 15])
- '''
-
相关阅读:
【Java基础(六)】面向对象与类的基础知识
Vue简介,模板语法,mvvm模型
双目视觉实战--单视图测量方法
通过配置文件(.htaccess)实现文件上传
overflow: auto滚动条跳到指定位置
端口探测技术总结
[晕事]今天做了件晕事26;gcc对strcmp/strncmp的优化
Treap 原理详解和实战
YOLO对象检测算法也这么卷了吗——基于YOLOv8的人体姿态检测
Roson的Qt之旅#108 QML ListView的布局、方向和堆叠顺序
- 原文地址:https://blog.csdn.net/dgvv4/article/details/125424902