一、对微博页面的分析
(一)对微博网页端的分析
- 首先,我们打开微博,发现从电脑端打开微博,网址为:Sina Visitor System
- 我们搜索关键字:巴以冲突,会发现其对应的 URL:巴以冲突
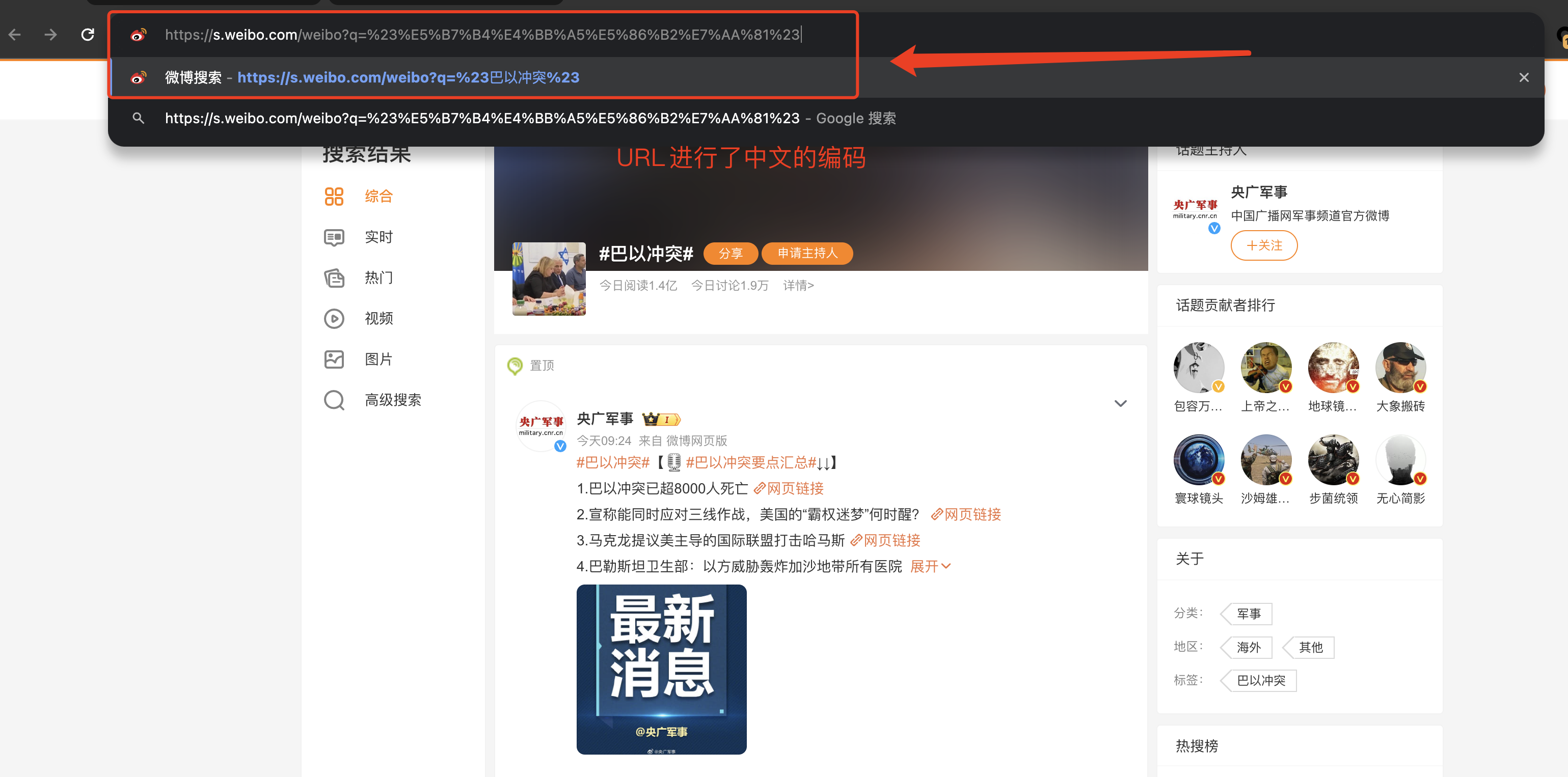
(1)URL 编码/解码
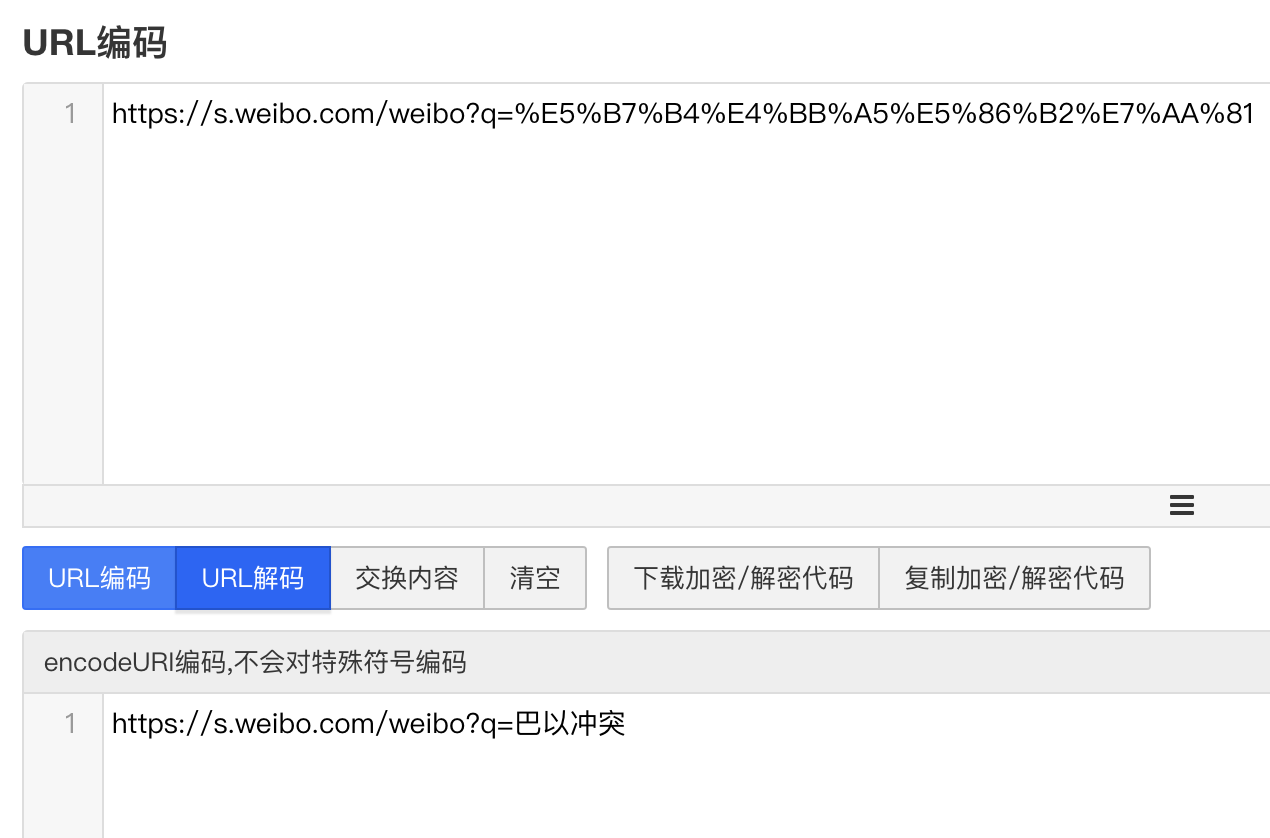
通过对 URL 进行分析,不难发现我们输入的是中文“巴以冲突”,但是真实的链接却不含中文,这是因为链接中的中文被编码了。我们将复制来的 URL 进行解码操作便可以得知。
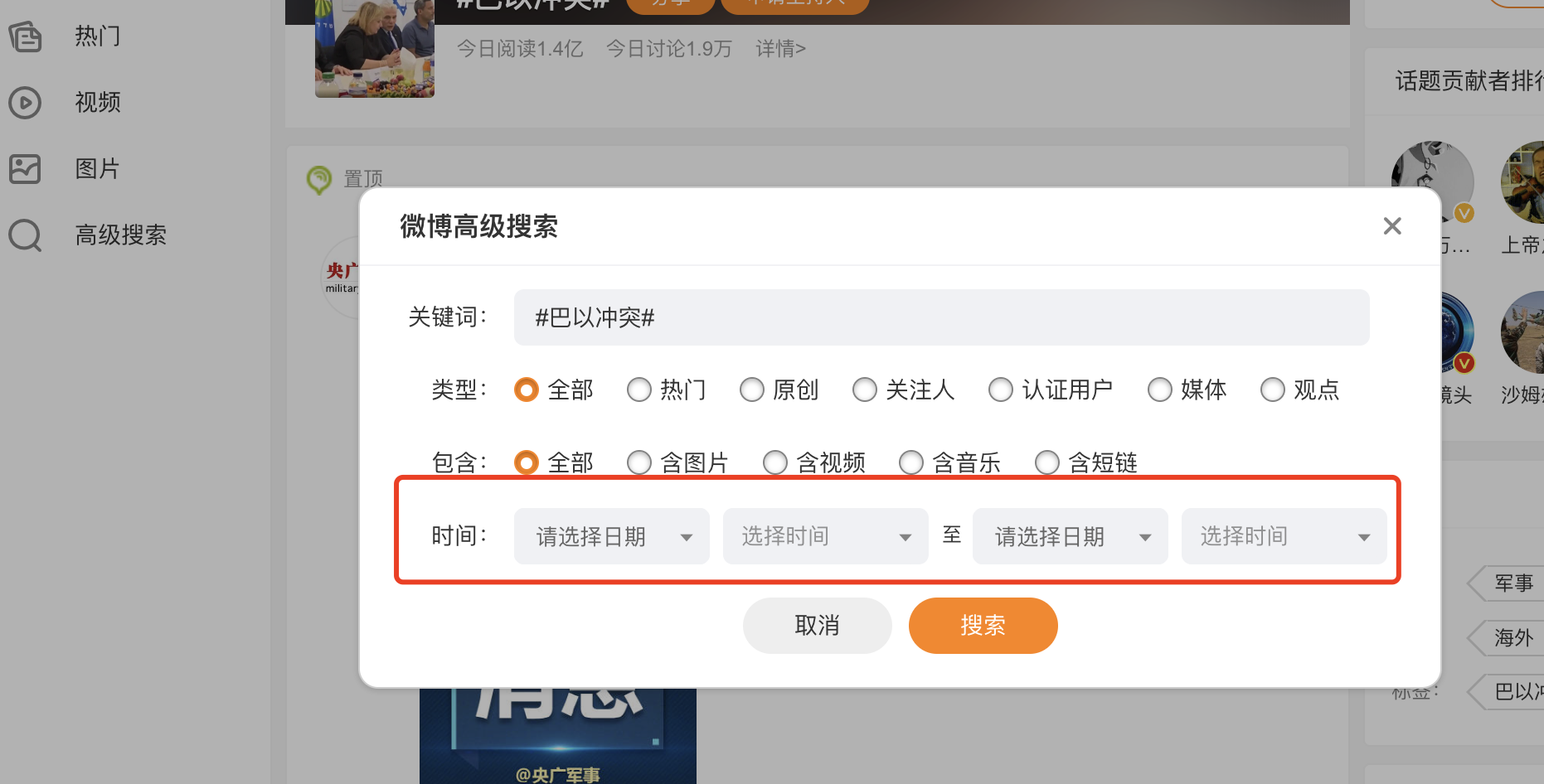
在巴以冲突这个页面里面可以看到高级搜索,打开高级搜索后发现可以对微博的发布时间进行筛选,还可以对微博类型、微博包含的内容进行筛选。 一开始,想的便是从这下手,非常方便爬取指定时间内指定话题下的微博内容。
(2)抓包分析请求网址/请求方法/响应内容
接着,打开开发者工具,对抓包进行分析,我们可以看到请求网址发生了变化, 请求网址为: https://weibo.com/ajax/side/search?q=%E5%B7%B4%E4%BB%A5%E5%86%B2%E7%AA%81, 请求方法是: GET
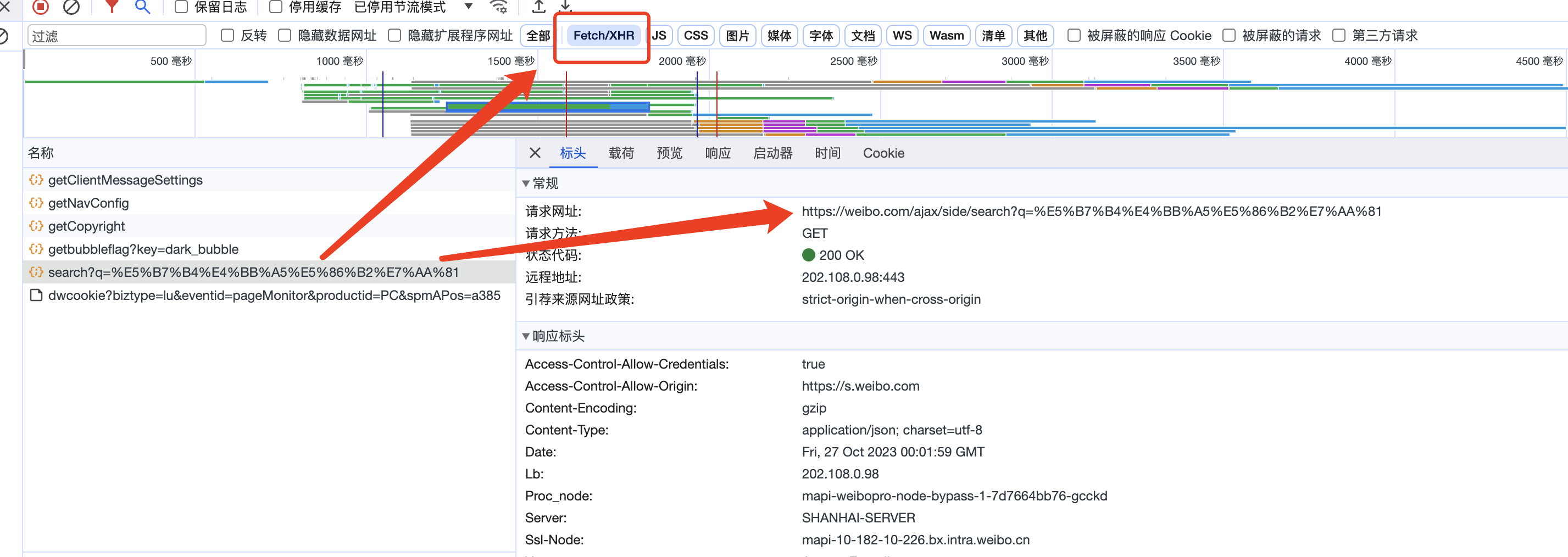
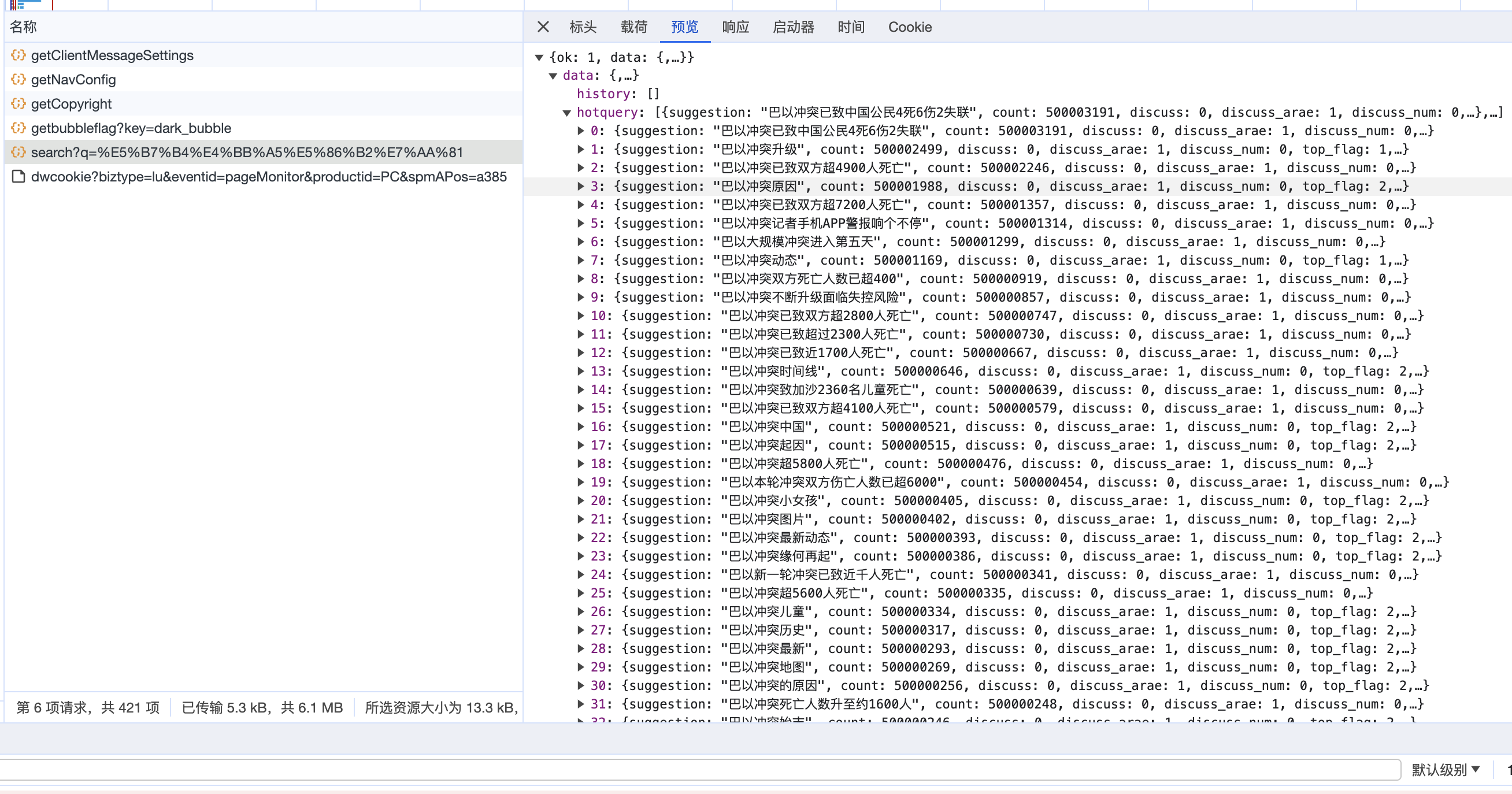
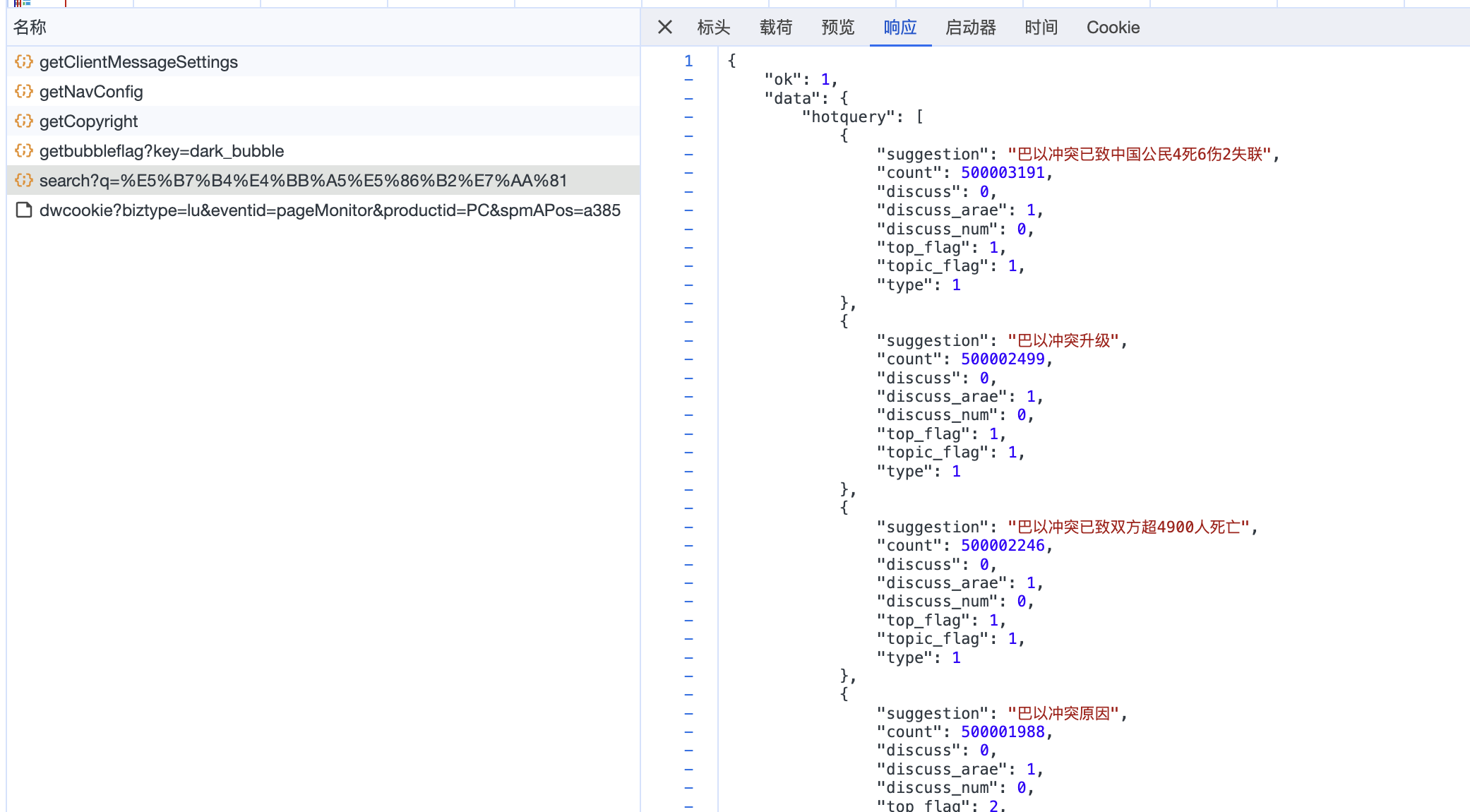
点开预览、查看相应内容,可以发现该请求网址返回的 json 文件内容对应的就是页面中加载的微博内容。
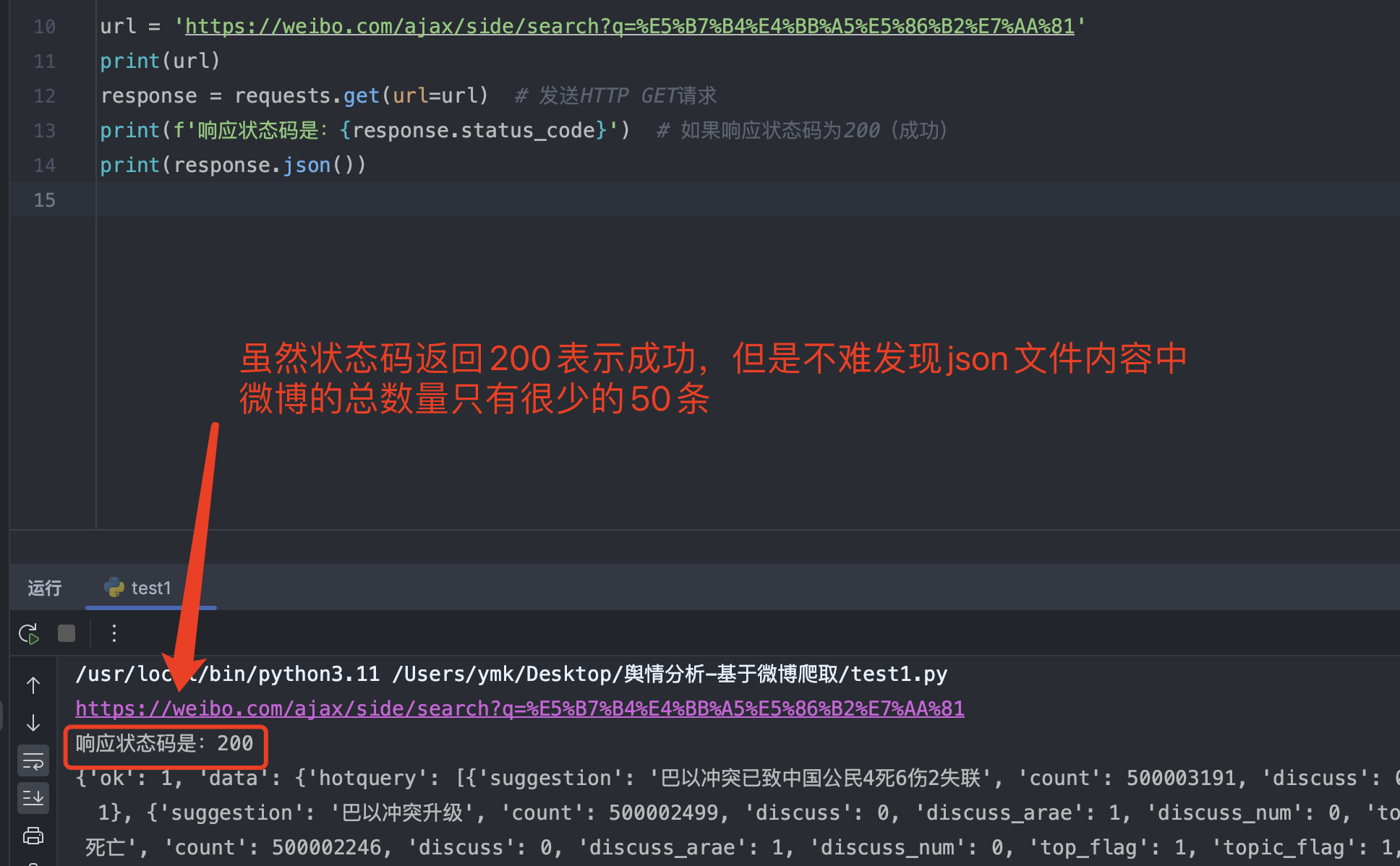
于是,便开始在 pycharm 中编写请求代码
(二)网页端的局限性(cookie 、微博数量问题)
虽然状态码返回 200 表示成功,但是 json 文件里面只有很少的 50 条微博数据,这对于爬虫而言是非常少的数据。但是,当我们向下滑动想要进一步探究、查看更多数据时,会发现这时候微博官方不给我们查看,要求我们登陆账号后才能查看。
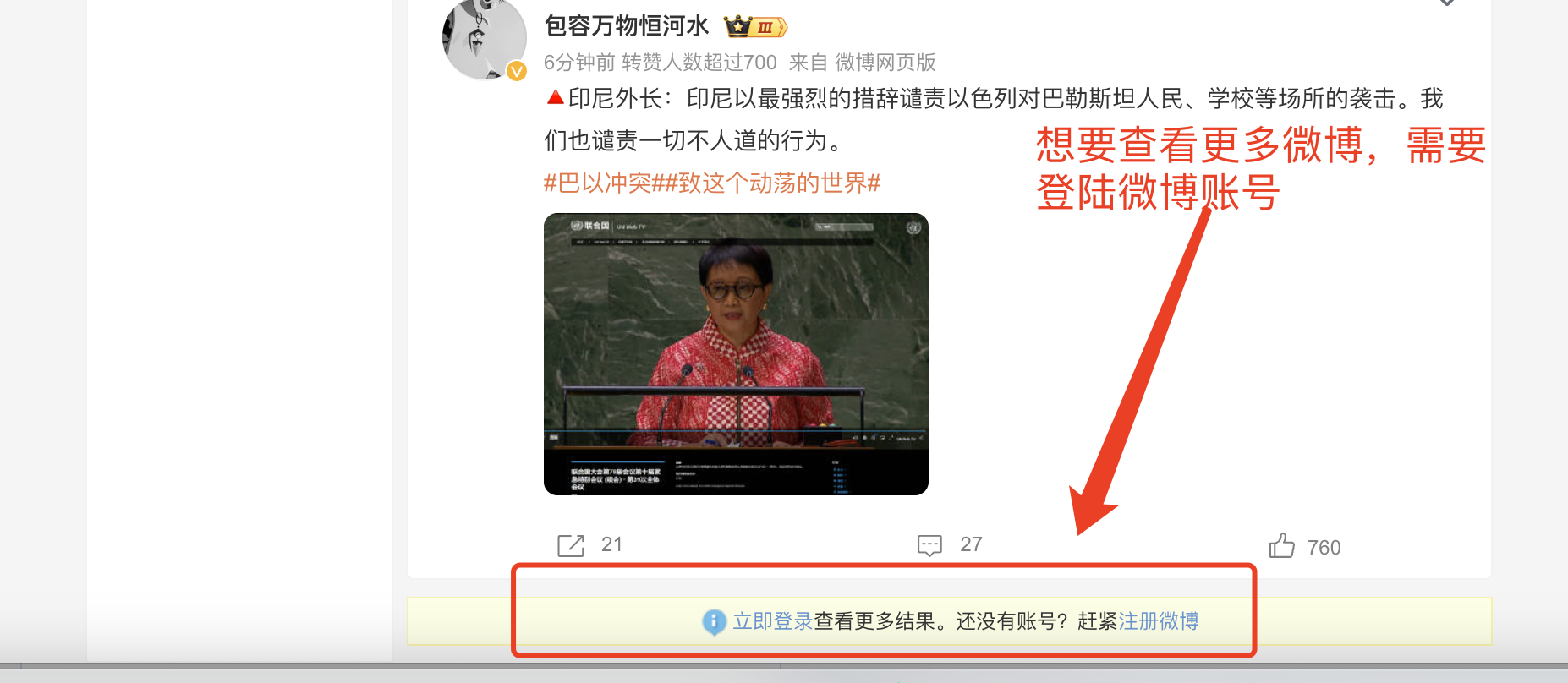
如果需要登陆账号才能查看更多微博内容,那么意味着在爬虫里面发送 http 请求时需要使用到账号的 cookie,又考虑到网站肯定存在对爬虫的检测,如果使用 cookie 的话,肯定会被封禁的,这不仅仅会影响爬取微博数据的效率,还会造成短时间内无法打开网站。
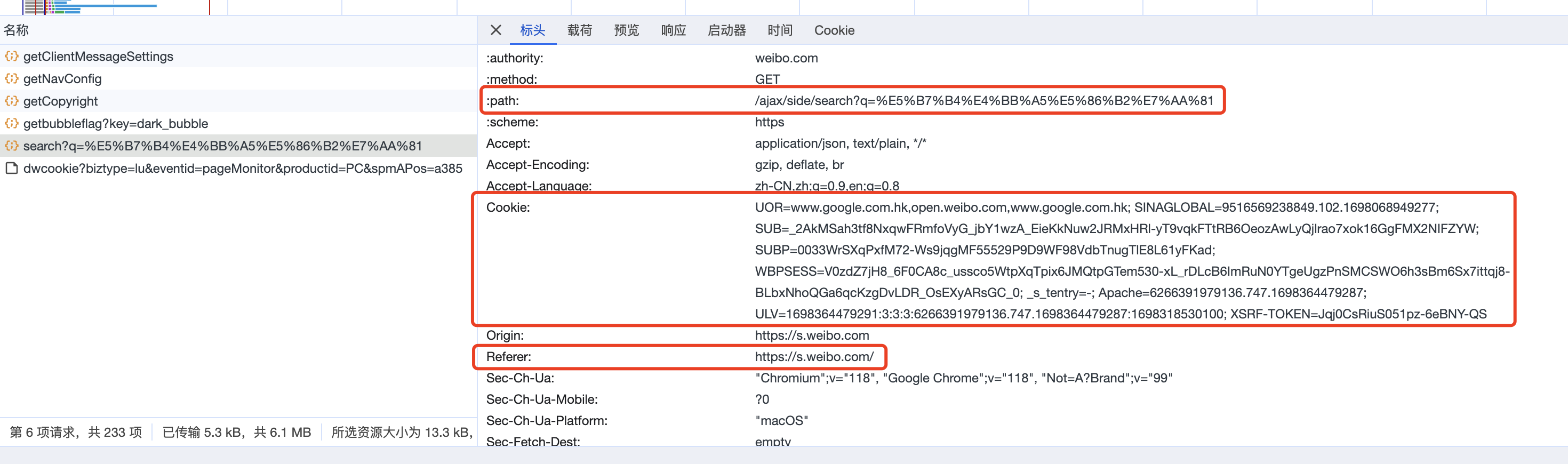
因此,这时候便不再尝试从当前网址下手爬取数据。
(三)微博手机端的分析
便开始在网上查阅相关的资料,想要找到一个无需 cookie 便能爬取微博数据内容,同时又能突破只能查看 50 条数据的局限性。最终,在某网页上面有网友提了一嘴,说:“在手机端界面爬取微博数据,比在网页端爬取更加方便、局限性相对来说更小”。 于是,便开始准备从手机端网址开始下手,先尝试着验证下网友说的是否正确。 手机端的网址是:https://m.weibo.cn
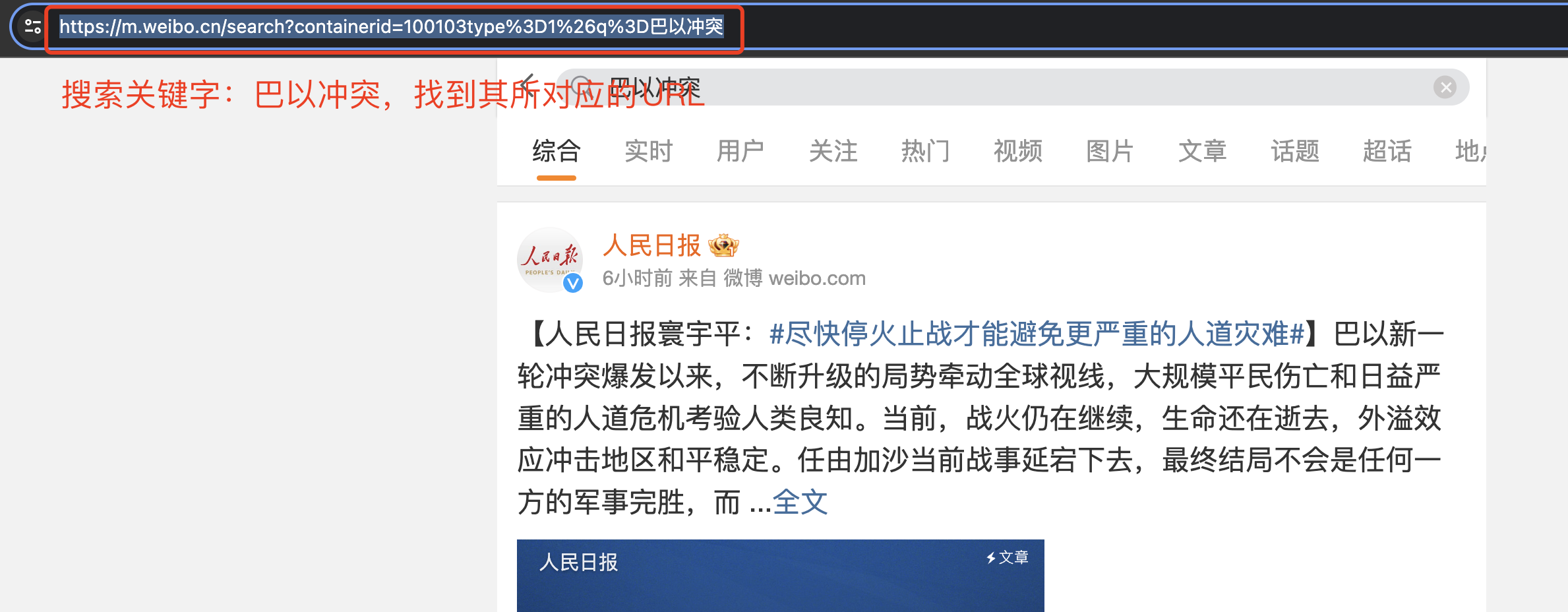
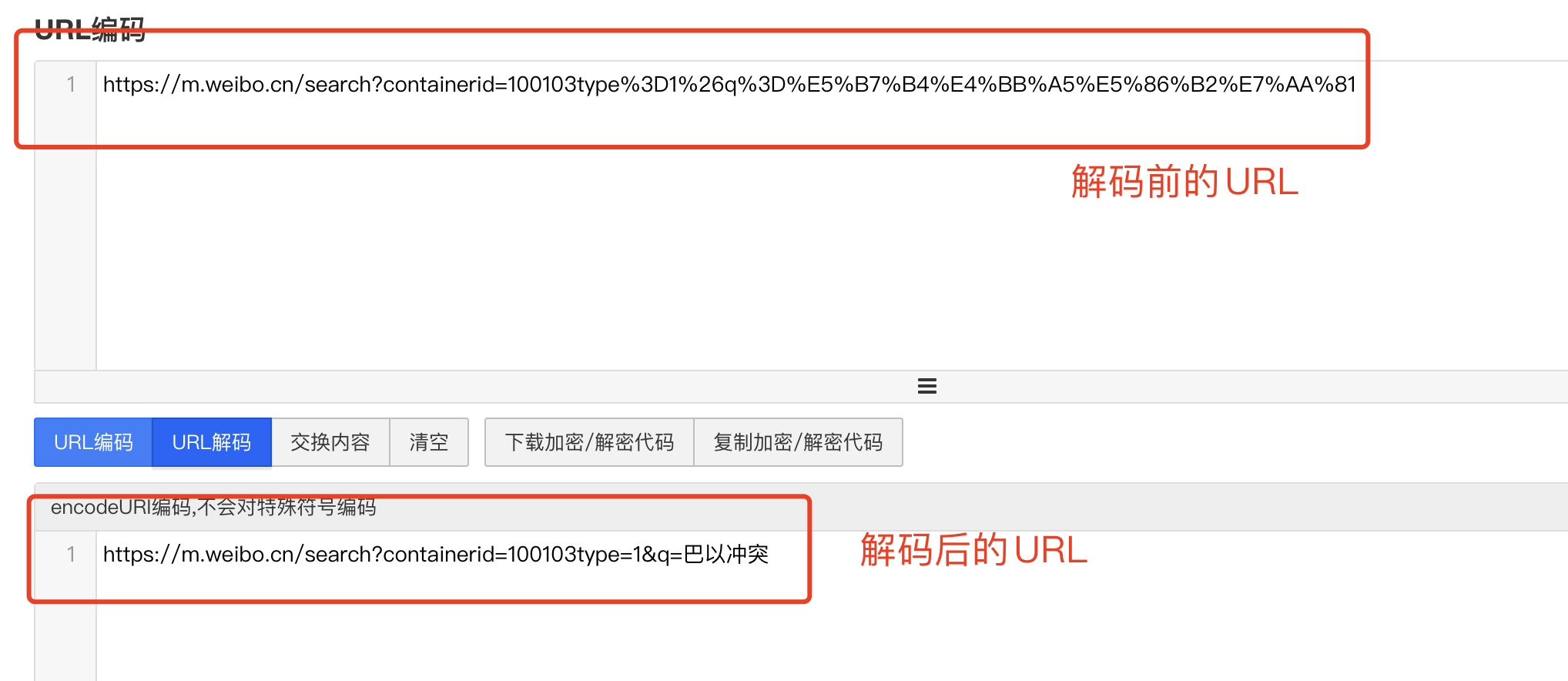
在搜索框内搜索巴以冲突,找到其对应的 URL:https://m.weibo.cn/search?containerid=100103type%3D1%26q%3D%E5%B7%B4%E4%BB%A5%E5%86%B2%E7%AA%81
(1)URL 编码/解码
不难发现,此处的中文仍然进行了编码操作,我们需要对链接进行解码查看是否为原来的 URL。
(2)抓包分析
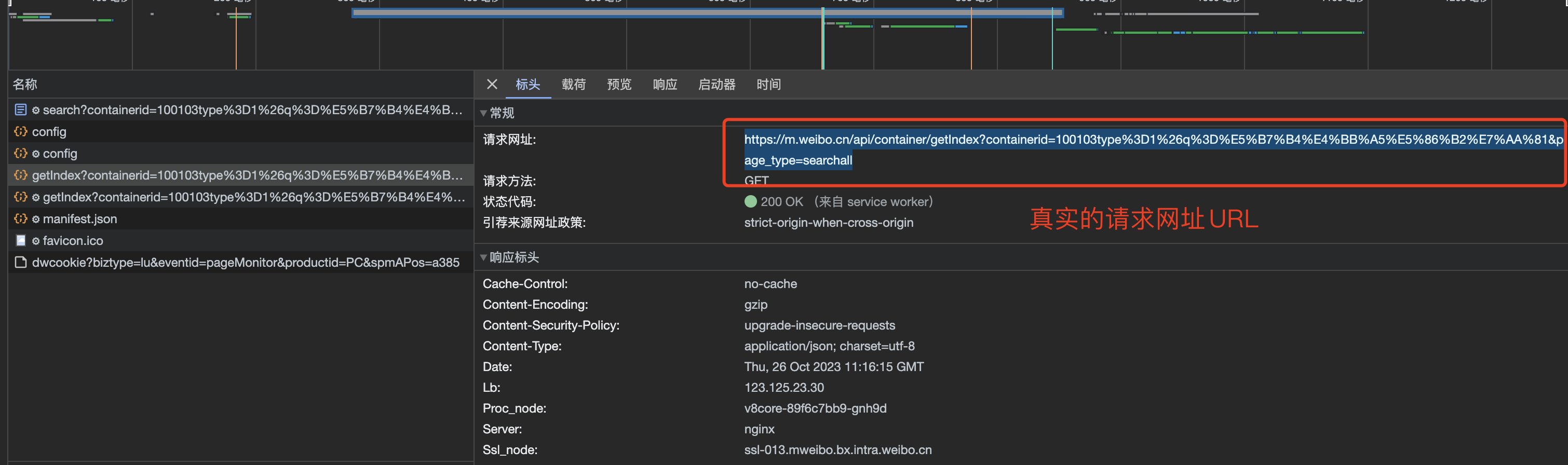
打开开发者工具,开始对网页抓包进行分析,我们在 Fetch/XHR 里面可以找到 https 请求, 请求网址是:https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E5%B7%B4%E4%BB%A5%E5%86%B2%E7%AA%81&page_type=searchall, 请求方法是:GET, 请求参数是:containerid=100103type%3D1%26q%3D%E5%B7%B4%E4%BB%A5%E5%86%B2%E7%AA%81&page_type=searchall
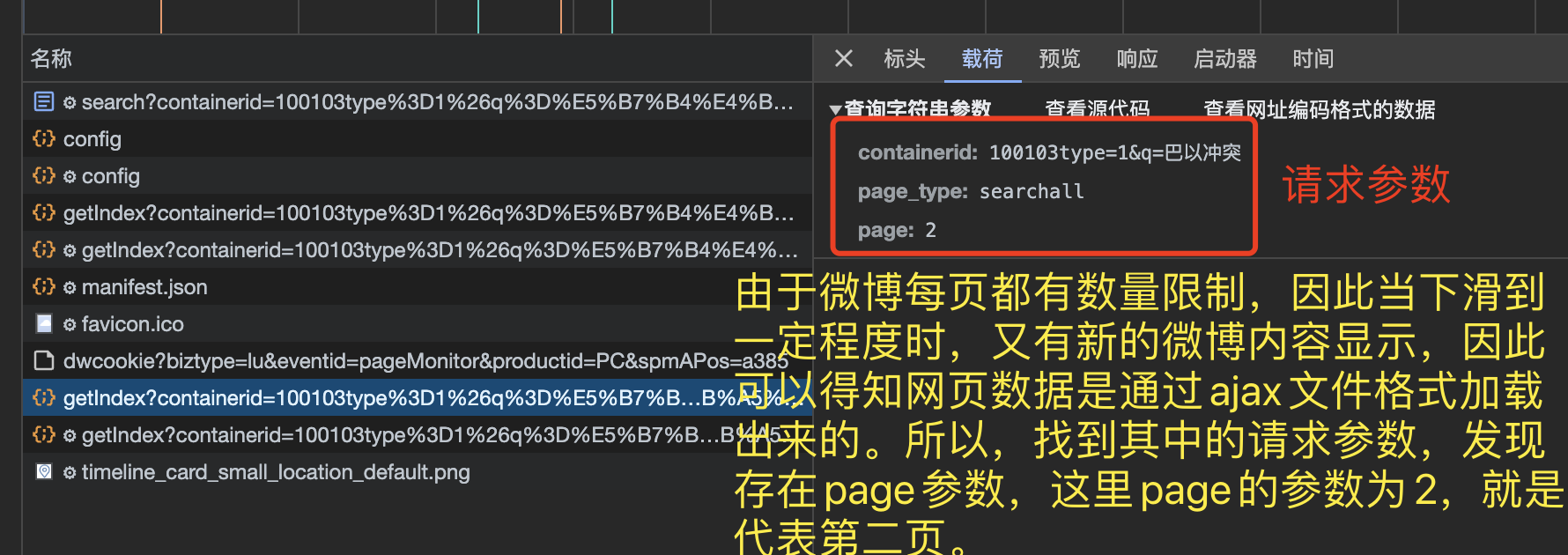
(3)请求参数分析

由于微博每页都有数量限制,因此当下滑到一定程度时,又有新的微博内容显示,因此可以得知网页数据是通过ajax文件格式加载出来的。所以,找到其中的请求参数,发现存在page参数,这里 page的参数为 2,就是代表第二页。这个时候不难猜测出从本页面下手,并不存在微博内容数量的限制,我们只需要设置好 page 参数即可。
于是便开始写相关的代码,首先写好请求参数 params
(4)json 内容分析
接着我们打开请求网址https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E5%B7%B4%E4%BB%A5%E5%86%B2%E7%AA%81&page_type=searchall,发现下面微博数据仍然是以 json 格式显示的,因此我们需要对 json 文件内容进行分析。
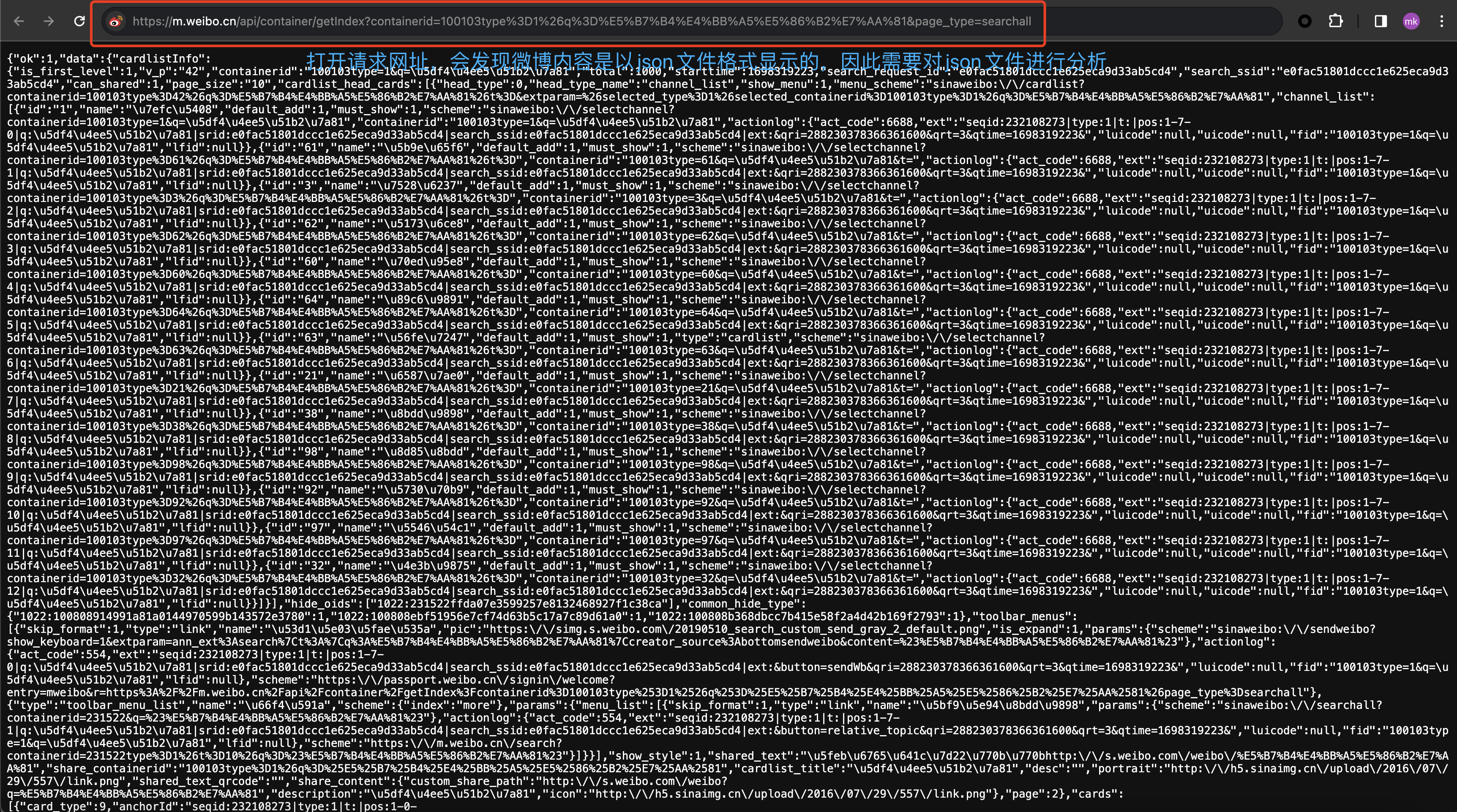
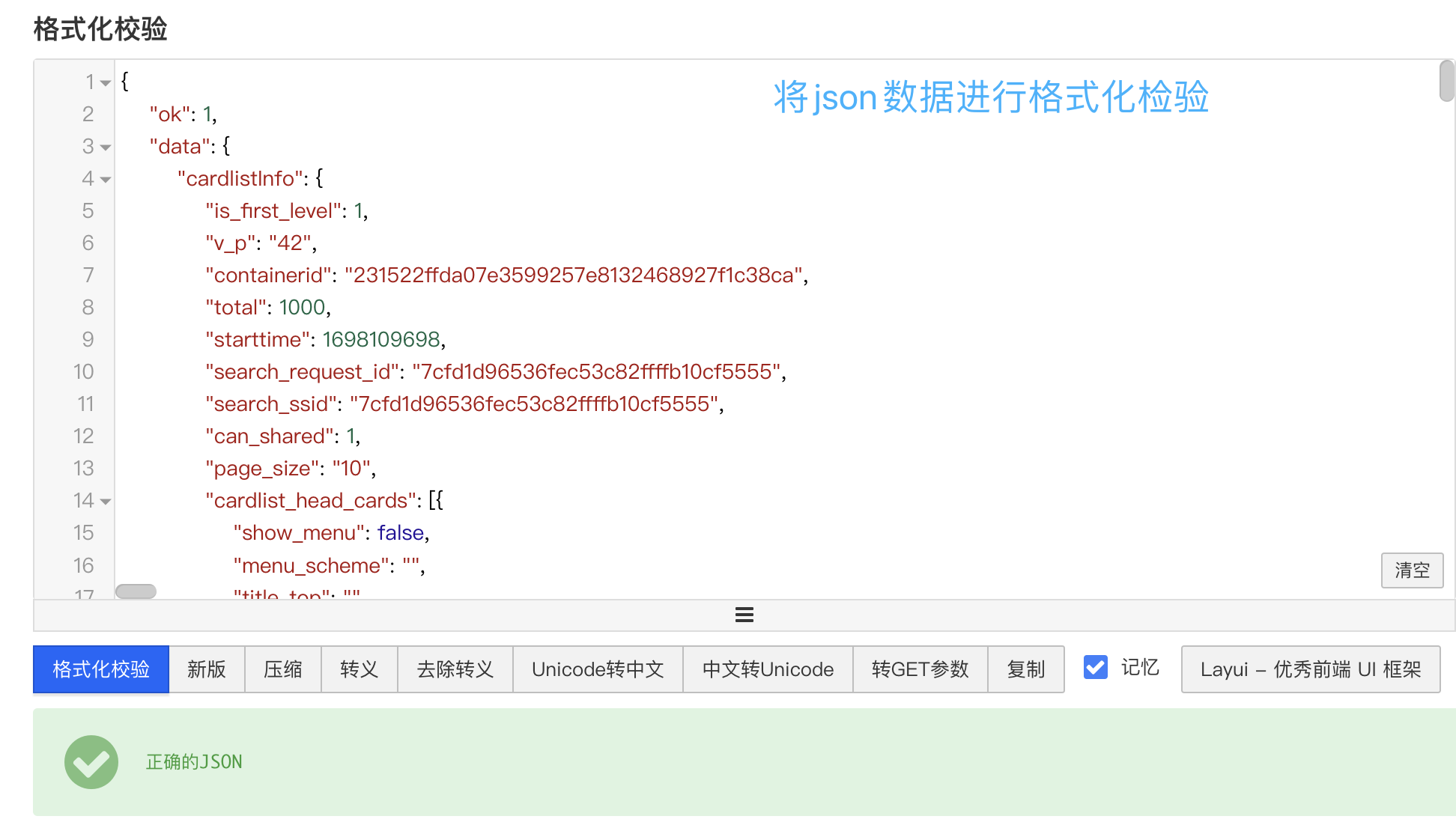
首先,我们将 json 文件内容复制到 json 格式化检验里,发现 返回的 json 是正确的 json 文件
为了方便对 json 文件内容的分析,我们选取 json 视图对 json 进行可视化分析。 不难发现,微博内容存在于 json/data/cards/里面,下图中的 0~22 均代表一条条微博内容等等数据。 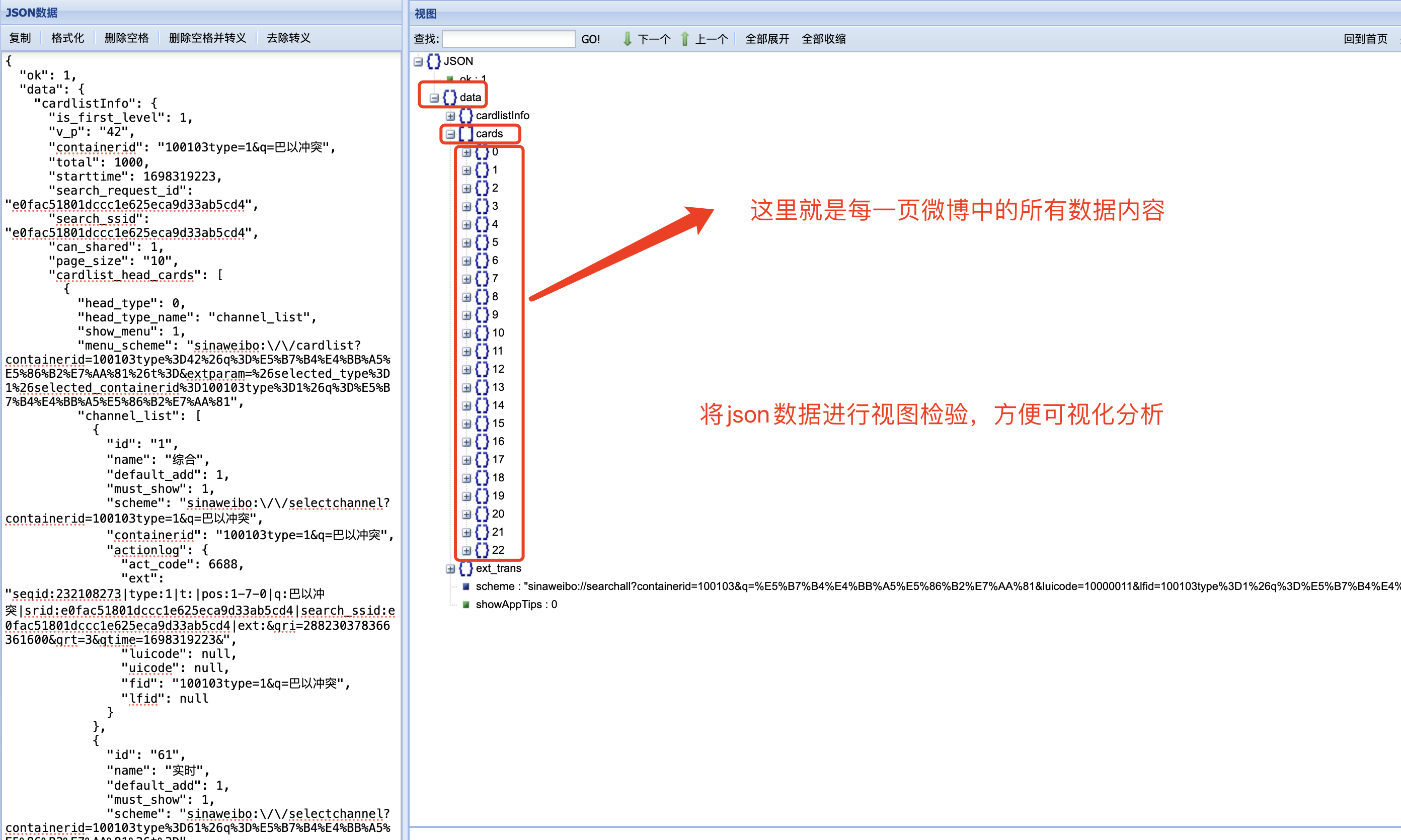
(5)查看/提取 json 有效信息
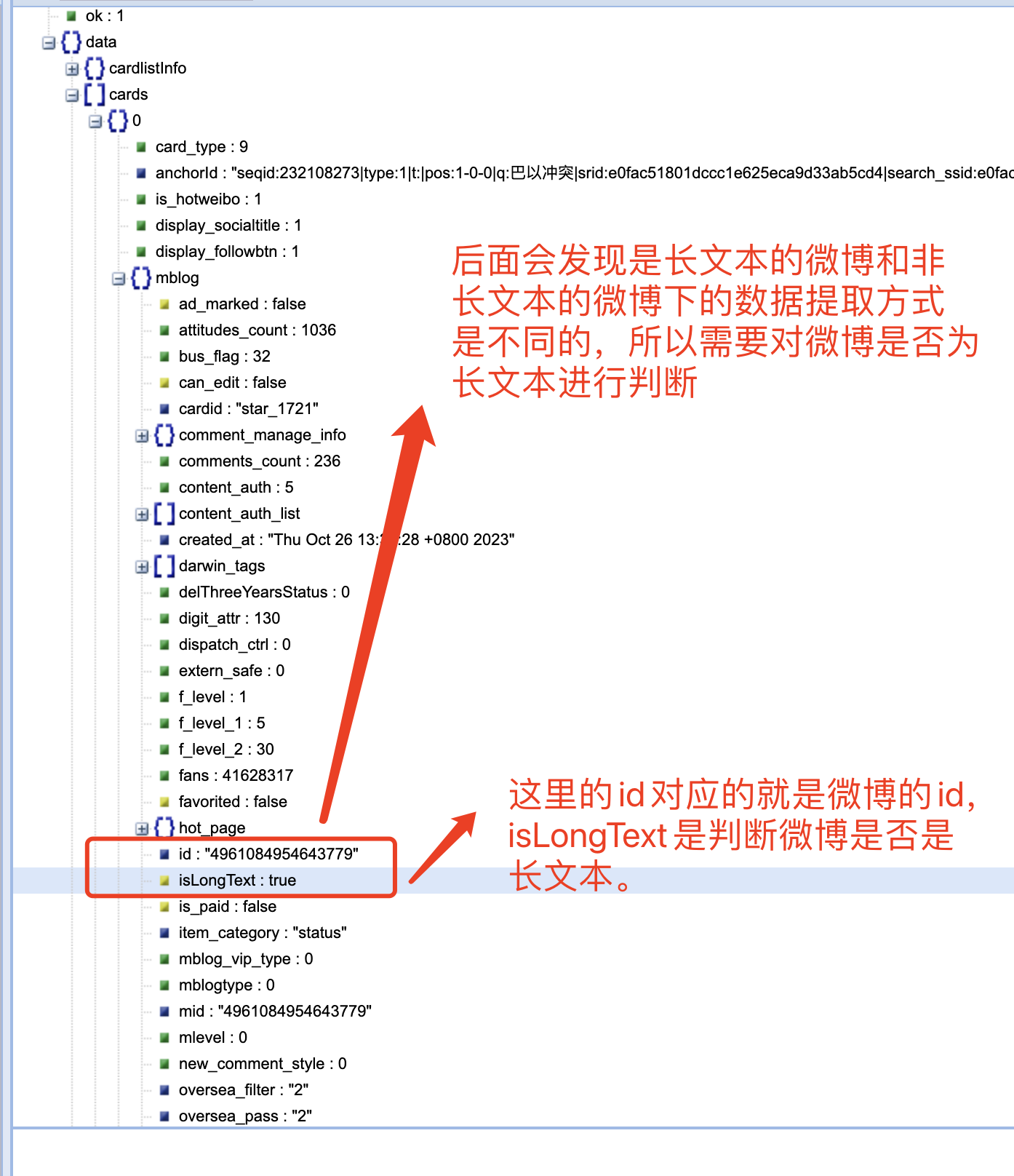
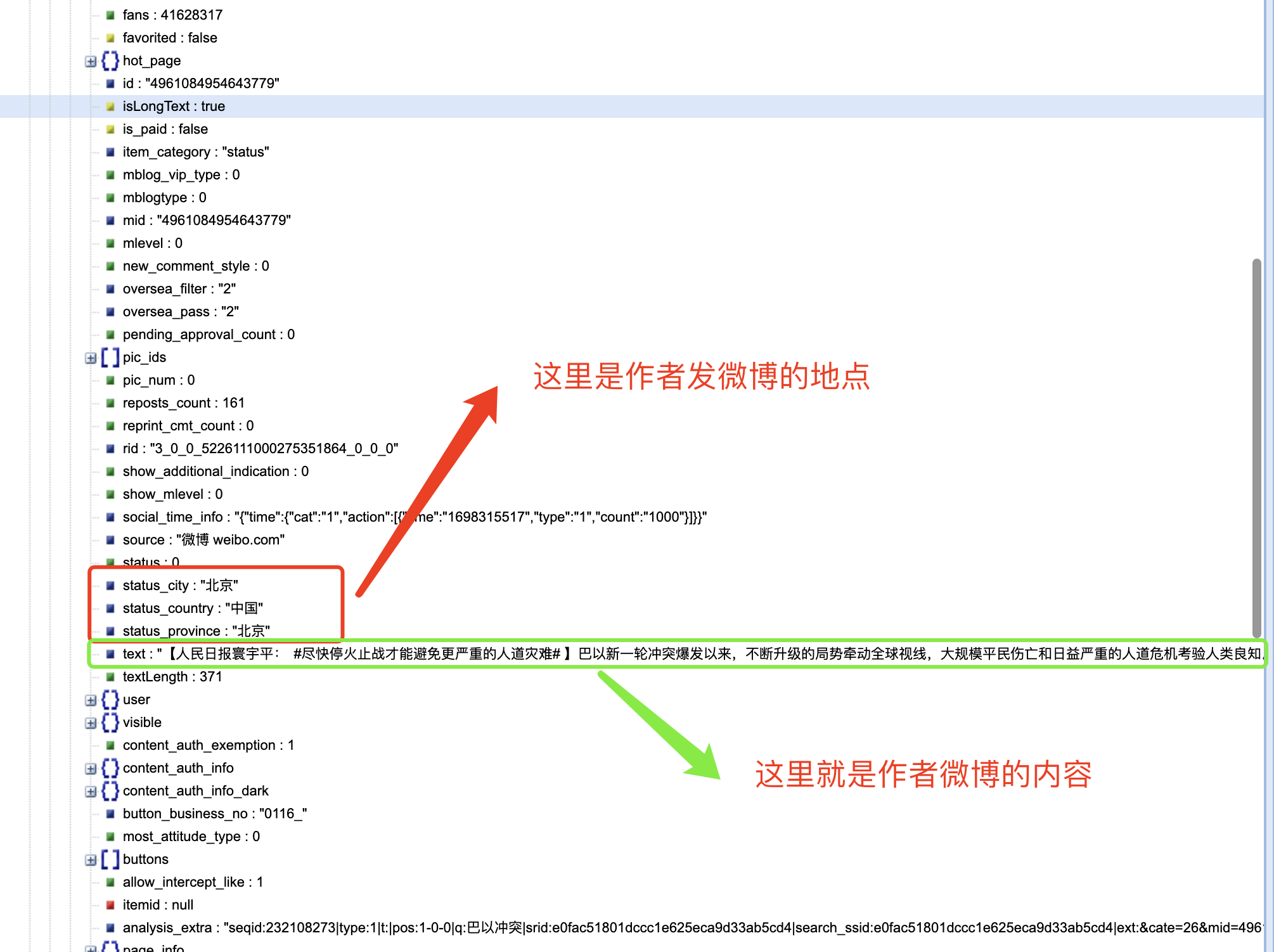
结合网页内容对 cards 下面的内容进行分析,我们可以发现: -->在 mblog 中存在判断微博是否为长文本一项 isLongText : true 其他有用内容如下:
Json参数分析
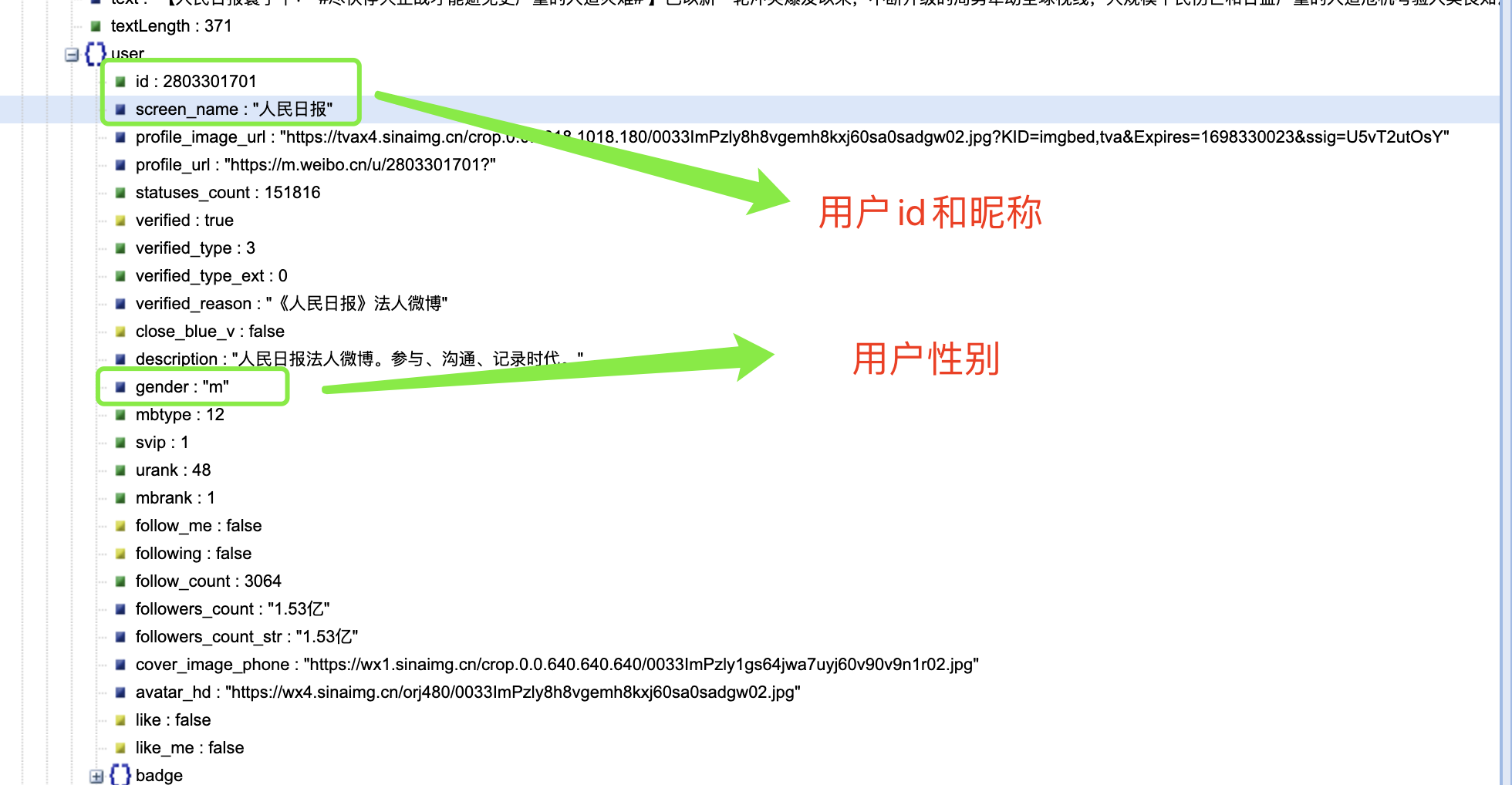
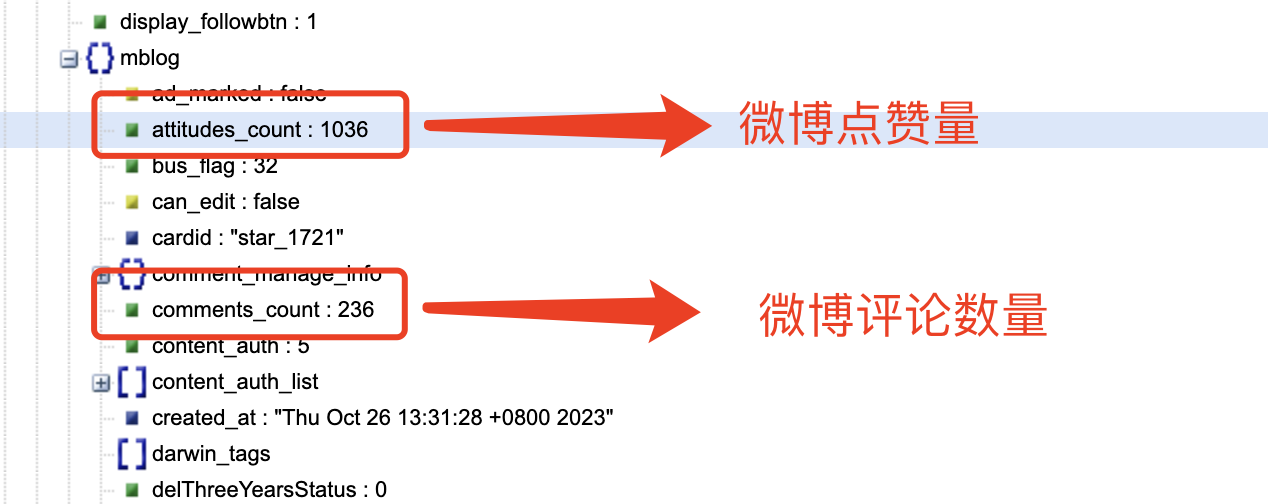
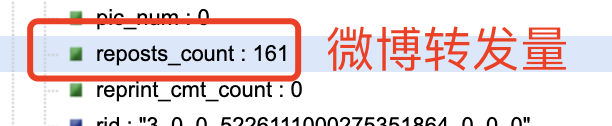
到了这里,我惊讶的发现爬取时并不需要用户的 cookie,可以证明网友的某些说法是正确的。
二、代码实现过程:
(1)导包
(2)设置基础的 URL 以及请求参数 params
(3)将微博的时间格式转换为标准的日期时间格式
(4)按页数 page 抓取微博内容数据
(5)定义长文本微博内容的爬取
(6)对 json 中的有效信息进行提取
(7)将爬取到的内容保存到 csv 文件内
(8)对csv数据进行处理
打开 csv 文件后会发现,存在重复的微博内容。 因为微博都有自己独有的 ID,故从 ID 下手对重复值进行删除处理。 在 Jupyter notebook 里面进行数据处理分析
三、完整的代码
完整爬虫代码(注释由gpt自动生成)
__EOF__
