ABC357总结
A - Sanitize Hands
翻译
有一瓶消毒剂,正好可以消毒
请计算有多少个外星人可以给所有的手消毒。
在这里,即使开始时没有足够的消毒剂给一个外星人的所有手消毒,他们也会用完剩余的消毒剂。
分析
直接模拟即可。
code
return 0;
B - Uppercase and Lowercase
翻译
给你一个由小写和大写英文字母组成的字符串
如果
否则,将
分析
依旧是模拟,先统计
code
size();i++)
size();i++)
}
}
C - Sierpinski carpet
翻译
对于一个非负整数
- 对于
- 中央区块完全由白色单元格组成。
- 其他八个区块是
"#" 为黑色单元格,"." 为白色单元格。
给你一个非负整数
请按照指定格式打印

分析
根据题意,
可以选择递推或递归来构造。
值得一提的是,不能直接打表,
下面是递推的做法。
code
{
a[i][k+j*m]=a[i][k];
{
for(int k=0;k'.';
2*m]=a[i][k];
{
a[i+2*m][k+j*m]=a[i][k];
{
cout<<"\n";
D - 88888888
翻译
对于正整数
更确切地说,把
例如,
求
分析
这是比较毒瘤的一道题了。
对于
它总共有
显然,它是一个等比数列。
根据等比数列求和公式可知:
分子部分可以直接用快速幂求解,而分母则需要用到逆元,模数是质数,可以直接用费马小定理求逆元。
复杂度是
其中需要注意的是,
在指数上的
code
10,n+=s[i]-'0',m*=10,m%=mod;
return 0;
E - Reachability in Functional Graph
翻译
有一个有向图,图中有
每个顶点的出度为
计算有多少对顶点
这里,如果存在长度为
- 每个
分析
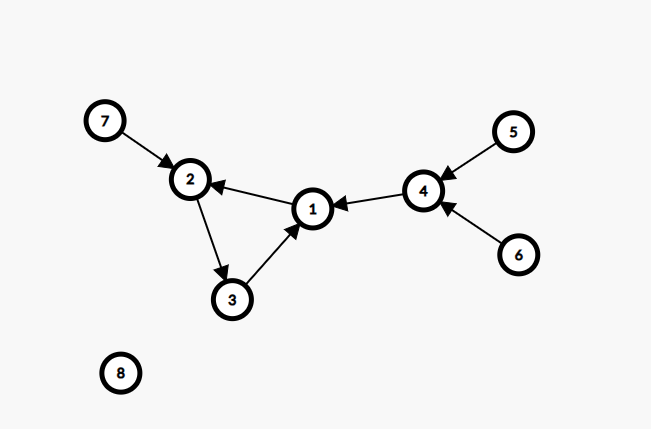
每个点出度都为
从某一个节点出发的路径中,必定是包含了一个环的,或者说每条路径都是以环结束的,且第一个到达的环的节点就是环的初始点。
对于一个环来说,环中的每一个节点能到达的只有环中的点,每个点对答案的贡献就是环的节点数。
设
例如
而在环外部的点,它必然能且只能到达一个环。从环的起始点开始往回走,依次统计节点贡献,每次加上自己。
例如
也就是说,首先要找到环,将环内部节点的
因为一条路径必然以环结尾,可以选一条路一直走下去,沿途标记路径上的节点。碰到已经标记了的节点时,判断是不是当前路径的标记。如果不是,说明这条路结尾的环已经被处理过了;如果是,说明找到了环的初始点,此时需要再绕着环走一圈,统计环的节点数,再走一圈,将环初始化。
最后记忆化搜索,进行统计。
code
return 0;
F - Two Sequence Queries
翻译
给你长度为
您还得到了
查询有三种类型:
1 l r x: 将2 l r x: 将3 l r: 输出
分析
一道明显的线段树,需要维护两个数组,处理两个懒标记。
需要维护的元素是:
-
当
-
当
code
update1(rc,l,r,x);
update2(rc,l,r,x);
query(rc,l,r);
" "<"\n";
" "<" "<"\n";
" "<"\n";
__EOF__
