-
基于Flask的岗位就业可视化系统(三)
前言
-
本项目综合了基本数据分析的流程,包括数据采集(爬虫)、数据清洗、数据存储、数据前后端可视化等
-
推荐阅读顺序为:数据采集——>数据清洗——>数据库存储——>基于Flask的前后端交互,有问题的话可以留言,有时间我会解疑~
-
感谢阅读、点赞和关注
开发环境
- 系统:Window 10 家庭中文版。
- 语言:Python(3.9)、MySQL。
- Python所需的库:pymysql、pandas、numpy、time、datetime、requests、etree、jieba、re、json、decimal、flask(没有的话pip安装一下就好)。
- 编辑器:jupyter notebook、Pycharm、SQLyog。
(如果下面代码在jupyter中运行不完全,建议直接使用Pycharm中运行)
文件说明
本项目下面有四个.ipynb的文件,下面分别阐述各个文件所对应的功能:(有py版本 可后台留言)-
数据采集:分别从前程无忧网站和猎聘网上以关键词数据挖掘爬取相关数据。其中,前程无忧上爬取了270页,有超过1万多条数据;而猎聘网上只爬取了400多条数据,主要为岗位要求文本数据,最后将爬取到的数据全部储存到csv文件中。
-
数据清洗:对爬取到的数据进行清洗,包括去重去缺失值、变量重编码、特征字段创造、文本分词等。
-
数据库存储:将清洗后的数据全部储存到MySQL中,其中对文本数据使用jieba.analyse下的extract_tags来获取文本中的关键词和权重大小,方便绘制词云。
-
基于Flask的前后端交互:使用Python一个小型轻量的Flask框架来进行Web可视化系统的搭建,在static中有css和js文件,js中大多为百度开源的ECharts,再通过自定义controller.js来使用ajax调用flask已设定好的路由,将数据异步刷新到templates下的main.html中。
技术栈
- Python爬虫:(requests和xpath)
- 数据清洗:详细了解项目中数据预处理的步骤,包括去重去缺失值、变量重编码、特征字段创造和文本数据预处理 (pandas、numpy)
- 数据库知识:select、insert等操作,(增删查改&pymysql) 。
- 前后端知识:(HTML、JQuery、JavaScript、Ajax)。
- Flask知识:一个轻量级的Web框架,利用Python实现前后端交互。(Flask)
三、数据库存储
需要先在数据库中定义好数据库以及表
这里改成自己数据库的用户名和密码
下面是 连接数据库 和 关闭数据库
def get_con(): con = pymysql.connect(host = 'localhost', user = '用户名', password = '密码', database = '数据库名', charset = 'utf8') cursor = con.cursor() return con, cursor def con_close(con, cursor): if cursor: cursor.close() if con: con.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
读取数据
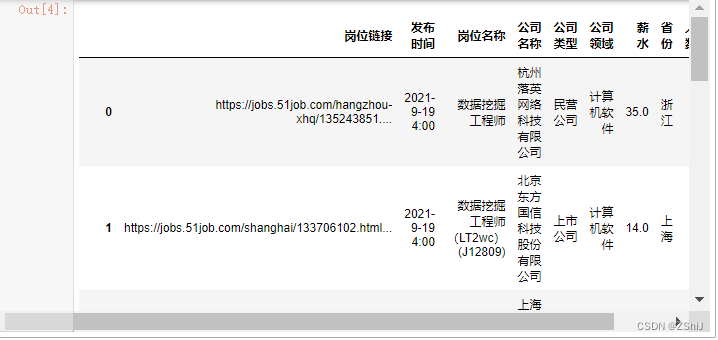
df = pd.read_csv('51job_data_preprocessing.csv', encoding = 'gb18030') df- 1
- 2
将每行数据都转变为tuple数据类型,然后遍历把每条数据都添加到sql中,有多次存数因而不使用上方函数
con, cursor = get_con() for i in range(len(df)): s = tuple(df.iloc[i, :]) print({s}) sql = f'insert into data_mining values{s}' cursor.execute(sql) con.commit() con_close(con, cursor)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

可以显示当前的时间time_str = time.strftime('%Y{}%m{}%d{} %X') time_str.format('年', '月', '日')- 1
- 2
将岗位要求数据存储到sql以及数据集中
把词云部分数据也存放进数据库中
df_cloud = pd.read_csv('liepin_job_detail.csv', encoding = 'gb18030') df_cloud- 1
- 2

将每一列英文全部转换为大写的df_cloud = df_cloud.apply(lambda x: [i.upper() for i in x]) df_cloud.head()- 1
- 2

对文本进行去重操作
s = np.unique(df_cloud.sum().tolist()).tolist()- 1
由于后期使用echarts绘制词云需要知道各个关键词的权重大小,所以下面使用jieba下的extract_tags来挖掘各个关键词和权重大小,注意extract_tags输入的是一个字符串,我们挑选出前150个关键词及权重
ss = aa.extract_tags(' '.join(s), topK = 150, withWeight = True) ss- 1
- 2

con, cursor = get_con() for i in range(len(ss)): sql = "insert into data_mining_cloud(词语, 权重) value ({0}, {1})".format(repr(ss[i][0]), ss[i][1]) cursor.execute(sql) con.commit() con_close(con, cursor)- 1
- 2
- 3
- 4
- 5
- 6
用repr方法可以自动帮我们加上引号
如果写不进sql中,可以参照这个,也可以直接存储到csv文件中
# # 存不进sql直接存储到csv文件中 # text, weight = [], [] # for i in range(len(ss)): # text.append(ss[i][0]) # weight.append(ss[i][1]) # df_cloud_clean = pd.DataFrame({'词语': text, '权重': weight}) # df_cloud_clean.to_csv('./wordcloud.csv', encoding = 'gb18030', index = None)- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
-
相关阅读:
Nodejs后端接口项目「可供练手」
又现信息泄露事件!融云揭秘通讯安全守护之道
HTML 简介
HQL,SQL刷题,尚硅谷(中级)
智能算力的枢纽如何构建?中国云都的淮海智算中心打了个样
金仓数据库 KingbaseES PL/SQL 过程语言参考手册(13. PL/SQL优化和调优)
百货商场会员系统 加强会员身份“认同感”(下)
PHP循环获取Excel表头字母A-Z,当超过时输出AA,AB,AC,AD······
Nginx优化
nodejs+vue+elementui+python酒店客房预订网站系统java
- 原文地址:https://blog.csdn.net/m0_53054984/article/details/137525223