-
[云原生] 二进制k8s集群(下)部署高可用master节点
在上一篇文章中,就已经完成了二进制k8s集群部署的搭建,但是单机master并不适用于企业的实际运用(因为单机master中,仅仅只有一台master作为节点服务器的调度指挥,一旦宕机。就意味着整个集群的瘫痪,所以成熟的k8s的集群一定要考虑到master的高可用。)企业的运用一般至少存在两台master及其以上的部署,本次将根据前面的部署,再添加一台master(三个master或者更多,也可以根据本次添加步骤重复添加)。添加master后,我们会将借助keepalived+nginx的架构,来实现高可用的master【也可以使用haproxy+keepalived或则是keepalived+lvs(不推荐,步骤过于复杂)
本次部署的架构组件
mater节点 mater01 192.168.73.100 kube-apiserver kube-controller-manager kube-scheduler master02 192.168.73.130 kube-apiserver kube-controller-manager kube-scheduler node节点 node01 192.168.73.110 kubelet kube-proxy docker (容器引擎) node02 192.168.73.120 kubelet kube-proxy docker (容器引擎) etcd cluster集群 etcd节点1 192.168.73.100(mater01) etcd etcd节点2 192.168.73.110(node01) etcd etcd节点3 192.168.73.120(node02) etcd load balance(高可用调度器) 主调度器 192.168.73.140 nginx,keepalived 从调度器 192.168.73.150 nginx,keepalived  架构说明:
架构说明:-
node节点的kubelet只能对接一个master节点的apiserver,不可能同时对接多个master节点的apiserver。简而言之,node节只能有一个master来领导。
-
kubelet和kube-proxy是通过kubelet.kubeconfig和kube-proxy.kubeconfig文件中的server参数进行对接 master节点的。
-
所以在多master节点的环境下,需要有nginx负载均衡器来进行调度,而且需要进行keepalived高可用的构建(主从两个节点) ,防止主节点宕机导致整个k8s集群的不可用。
一、新master节点的搭建
1.1 对master02 进行初始化配置
- #关闭防火墙
- systemctl stop firewalld
- systemctl disable firewalld
- iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
- #关闭selinux
- setenforce 0
- sed -i 's/enforcing/disabled/' /etc/selinux/config
- #关闭swap
- swapoff -a
- sed -ri 's/.*swap.*/#&/' /etc/fstab
- #根据规划设置主机名
- hostnamectl set-hostname master02
- su
- #在master添加hosts(添加到整个k8s集群的主机上,保证其他主机均有该映射)
- cat >> /etc/hosts << EOF
- 192.168.73.105 master01
- 192.168.73.110 master02
- 192.168.73.106 node01
- 192.168.73.107 node02
- EOF
- #调整内核参数
- cat > /etc/sysctl.d/k8s.conf << EOF
- #开启网桥模式,可将网桥的流量传递给iptables链
- net.bridge.bridge-nf-call-ip6tables = 1
- net.bridge.bridge-nf-call-iptables = 1
- #关闭ipv6协议
- net.ipv6.conf.all.disable_ipv6=1
- net.ipv4.ip_forward=1
- EOF
- sysctl --system
- #时间同步
- yum install ntpdate -y
- ntpdate ntp.aliyun.com
- #将时间同步的操作添加到计划性任务,确保所有节点保证时间的同步
- crontab -e
- */30 * * * * /usr/sbin/ntpdate ntp.aliyun.com
- crontab -l

1.2 将master01的配置移植到master02
- ##------------ 1、 master01节点,拷贝文件到master02 -------------------------------
- #从 master01 节点上拷贝证书文件、各master组件的配置文件和服务管理文件到 master02 节点
- scp -r etcd/ master02:`pwd`
- scp -r kubernetes/ master02:`pwd`
- scp /usr/lib/systemd/system/kube-* master02:/usr/lib/systemd/system/
- scp -r /root/.kube/ master02:/root/
-


- ##----------- 2、 master02节点,修改配置文件并启动相关服务-------------------------
- #修改配置文件kube-apiserver中的IP
- vim /opt/kubernetes/cfg/kube-apiserver
- KUBE_APISERVER_OPTS="--logtostderr=true \ #输出日志,false表示标准错误不输出到屏幕,而是输出到日志中。true表示标准错误会输出到屏幕。
- --v=4 \ #日志级别
- --etcd-servers=https://192.168.73.105:2379,https://192.168.73.106:2379,https://192.168.73.107:2379 \ #etcd节点的IP通信地址
- --bind-address=192.168.73.110 \ #修改,当前绑定的内网IP监听的地址
- --secure-port=6443 \ #基于HPPTS开放端口
- --advertise-address=192.168.73.110 \ #修改,内网通告地址,让其他node节点地址通信
- ......
- vim kube-controller-manager
- vim kube-scheduler
-
- #在 master02 节点上启动各服务并设置开机自启
- systemctl enable --now kube-apiserver.service
- systemctl enable --now kube-controller-manager.service
- systemctl enable --now kube-scheduler.service
-
- #将可执行文件,创建软链接
- ln -s /opt/kubernetes/bin/* /usr/local/bin/
-
- #查看node节点状态
- kubectl get nodes
- kubectl get nodes -o wide #-o=wide:输出额外信息;对于Pod,将输出Pod所在的Node名
- #此时在master02节点查到的node节点状态仅是从etcd查询到的信息,而此时node节点实际上并未与master02节点建立通信连接,因此需要使用一个VIP把node节点与master节点都关联起来




二、负载均衡的部署
- #配置load balancer集群双机热备负载均衡(nginx实现负载均衡,keepalived实现双机热备)
-
- #----------------- 1、两台负载均衡器配置nginx -------------------------------------
-
- #配置nginx的官方在线yum源,配置本地nginx的yum源
- cat > /etc/yum.repos.d/nginx.repo << 'EOF'
- [nginx]
- name=nginx repo
- baseurl=http://nginx.org/packages/centos/7/$basearch/
- gpgcheck=0
- EOF
-
- yum install nginx -y
-
- #修改nginx配置文件,配置四层反向代理负载均衡,指定k8s群集2台master的节点ip和6443端口
- vim /etc/nginx/nginx.conf
- events {
- worker_connections 1024;
- }
-
- #添加
- stream {
- log_format main '$remote_addr $upstream_addr - [$time_local] $status
- $upstream_bytes_sent';
- access_log /var/log/nginx/k8s-access.log main;
-
- upstream k8s-apiserver {
- server 192.168.73.105:6443; #master01
- server 192.168.73.110:6443; #master02
- }
- server {
- listen 6443;
- proxy_pass k8s-apiserver;
- }
- }
-
- http {
- ......
-
-
- #检查配置文件语法
- nginx -t
-
- #启动nginx服务,查看已监听6443端口
- systemctl start nginx
- systemctl enable nginx
- ss -lntp|grep nginx
-
-




- #------------------ 2、两台负载均衡器配置keepalived ------------------------------
-
- #部署keepalived服务
- yum install keepalived -y
-
- #修改keepalived配置文件
- vim /etc/keepalived/keepalived.conf
- ! Configuration File for keepalived
- global_defs {
- router_id nginx_master
- }
- vrrp_script check_nginx {
- script "/etc/nginx/check_nginx.sh" #指定检测脚本的路径,并且该脚本充当心跳检测脚本
- }
- vrrp_instance VI_1 {
- state MASTER #指定状态为master节点,109为BACKUP备用节点
- interface ens33
- virtual_router_id 51
- priority 100 #108优先级为100 109为90,优先级决定着主备的位置
- advert_int 1
- authentication {
- auth_type PASS
- auth_pass 1111
- }
- virtual_ipaddress {
- 192.168.73.66
- }
- track_script {
- check_nginx #追踪脚本的进程
- }
- }
- #将该文件 发送给备用调度器,并且将其中的配置修改为备用调度器的属性
- cd /etc/keepalived/
- scp keepalived.conf root@192.168.73.109:`pwd`
-
-
- #创建nginx状态检查脚本
- vim /etc/nginx/check_nginx.sh
- #!/bin/bash
- killall -0 nginx &>/dev/null
- if [ $? -ne 0 ];then
- systemctl stop keepalived
- fi
-
- chmod +x /etc/nginx/check_nginx.sh #为脚本增加执行权限
- #将该脚本发送给备用调度器
- cd /etc/nginx
- scp check_nginx.conf root@192.168.73.109:`pwd`
-
- #两台主备调度器启动keepalived服务(一定要先启动了nginx服务,再启动keepalived服务)
- systemctl start keepalived
- systemctl enable keepalived
- ip addr #查看主节点的VIP是否生成
-


nginx心跳检测脚本说明:
killall -0 可以用来检测程序是否执行
如果服务未执行的情况下 会进行报错
并且 $?的返回码 为非0值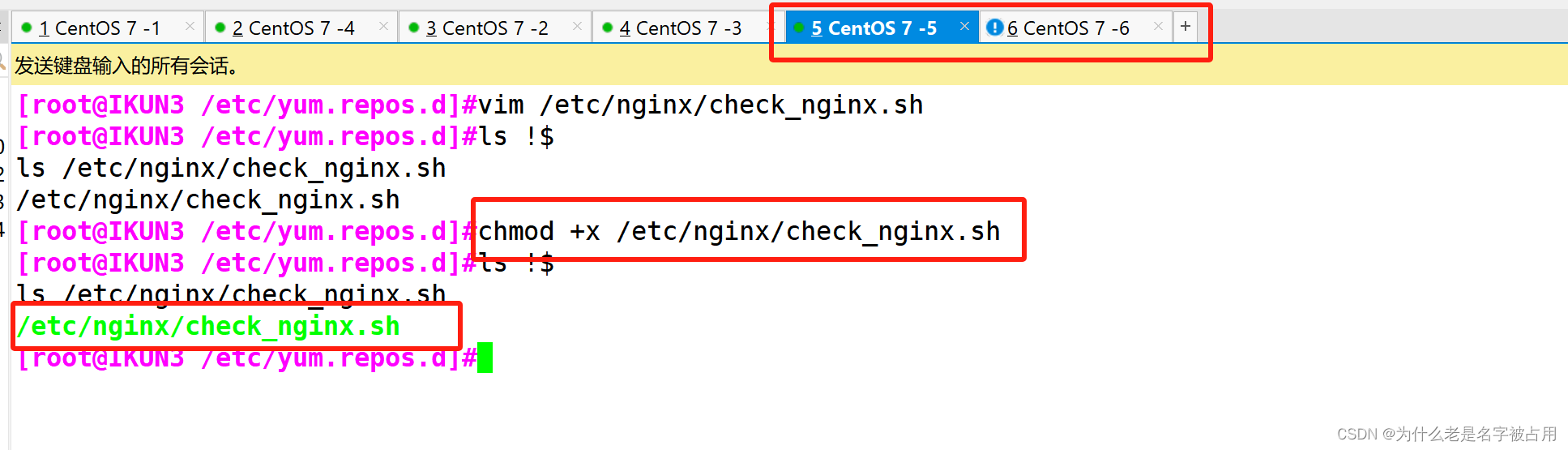
- vim /etc/keepalived/keepalived.conf
- scp /etc/keepalived/keepalived.conf 192.168.136.150:/etc/keepalived/
- systemctl enable --now keepalived.service
- systemctl status keepalived.service
- systemctl restart nginx keepalived.service
- ip a



- #---------------- 3、关闭主节点的nginx服务,模拟故障,测试keepalived-----------------------
-
- #关闭主节点lb01的Nginx服务,模拟宕机,观察VIP是否漂移到备节点
- systemctl stop nginx
- ip addr
- systemctl status keepalived #此时keepalived被脚本杀掉了
-
- #备节点查看是否生成了VIP
- ip addr #此时VIP漂移到备节点lb02
-


- //修改所有node节点上的bootstrap.kubeconfig,kubelet.kubeconfig配置文件为VIP
- [root@node01 /opt/kubernetes/cfg]#vim bootstrap.kubeconfig
- [root@node01 /opt/kubernetes/cfg]#vim kubelet.kubeconfig
- [root@node01 /opt/kubernetes/cfg]#vim kube-proxy.kubeconfig



- //重启node节点kubelet和kube-proxy服务
- systemctl restart kubelet.service
- systemctl restart kube-proxy.service

- //在 lb01 上查看 nginx 和 node 、 master 节点的连接状态
- netstat -natp | grep nginx

三、k8s的web UI界面的搭建
- //在 master01 节点上操作
- #上传 recommended.yaml 文件到 /opt/k8s 目录中,部署 CoreDNS
- cd /opt/k8s
- vim recommended.yaml
- #默认Dashboard只能集群内部访问,修改Service为NodePort类型,暴露到外部:
- kind: Service
- apiVersion: v1
- metadata:
- labels:
- k8s-app: kubernetes-dashboard
- name: kubernetes-dashboard
- namespace: kubernetes-dashboard
- spec:
- ports:
- - port: 443
- targetPort: 8443
- nodePort: 30001 #添加
- type: NodePort #添加
- selector:
- k8s-app: kubernetes-dashboard
- #通过recommended.yaml资源配置清单,使用kubectl apply创建资源,-f指定资源配置清单文件
- kubectl apply -f recommended.yaml
- #创建service account并绑定默认cluster-admin管理员集群角色
- kubectl create serviceaccount dashboard-admin -n kube-system
- kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
- #获取token值
- kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
- #使用输出的token登录Dashboard,访问node节点
- https://192.168.136.110:30001








-
-
相关阅读:
mysql数据库之字段类型
【Django】model模型—模型继承
环境配置 - Conda虚拟环境下配置jupyter notebook
数据结构之二叉搜索树
浏览器多开,数据之间相互不干扰
C++ day7
浅谈Python在人工智能领域的应用
区块链技术在金融领域的应用场景
dotnet 8 preview 1 即将发布
Python 集成 Nacos 配置中心
- 原文地址:https://blog.csdn.net/Cnm_147258/article/details/136250527
