-
【面试】测试/测开(未完成版)
1. 黑盒测试方法
黑盒测试:关注的是软件功能的实现,关注功能实现是否满足需求,测试对象是基于需求规格说明书。
1)等价类:有效等价类、无效等价类
2)边界值
3)因果图:不同的原因对应不同的结果
4)错误猜测:根据经验
5)场景设计
6)正交实验法:状态表、分析表
7)判定表:不同原因不同选择组合,如A原因选N、B原因选Y,组合结果为GO2. 白盒测试方法
白盒测试关注程序内部逻辑的实现,白盒测试的测试对象是基于被测试程序的源代码。
1)语句覆盖:设计足够的测试用例,使得被测程序中每条语句至少执行一次
2)条件覆盖:使得每一个判定获得每一种可能的结果至少一次
3)判定覆盖:使判定语句中的每个逻辑条件取真值与取假值至少出现一次
4)判定条件覆盖:使得判定语句中所有条件的可能取值至少出现一次,同时,所有判定语句的可能结果也至少出现一次
5)条件组合覆盖:使得每个判定中条件的各种可能组合都至少执行一次
6)路径覆盖:设计足够的测试用例,使得程序中的每一条可能组合的路径都至少执行一次3. 黑盒测试和白盒测试的区别
1)黑盒测试主要针对的是程序展现给用户的功能,而白盒测试则是主要针对程序的代码逻辑。前者测试最终功能,而后者测试后台程序。
2)测试方法不同
3)黑盒测试以规格需求说明书作为参考依据,而白盒测试需要以规格需求说明书以及程序设计文档等作为参考依据
无论采用哪种测试方法,毫无疑问都是为了找出缺陷,发现风险,从而确保软件的缺陷更少,质量更好。4. 性能测试主要指标
-
以前后端的角度看
1)前端:
响应时间、加载速度、消耗的流量
2)后端:
响应时间(关注接口)、并发用户数、内存占用、吞吐量(每秒事务数,在没有遇到性能瓶颈时:TPS=并发用户数*事务数/响应时间)、错误率、资源使用率(CPU占用率、内存使用率、磁盘I/O、网络I/O) -
以测试分析角度看
1)系统性能指标:
响应时间、系统处理能力(HPS每秒点击次数、TPS每秒处理交易次数、QPS系统每秒处理查询次数)、吞吐量、并发量、错误率
2)资源性能指标
CPU(用户态、系统态、等待态、空闲态)、内存、磁盘吞吐量、网络吞吐量
3)稳定性能指标
最短稳定时间:系统按照最大容量的80%或标准压力(系统的预期日常压力)情况下运行,能够稳定运行的最短时间。
5. 测试用例万能公式
-
万能公式
功能+性能+界面+兼容性+容错性+安全性+易用性+弱网+安装/卸载 -
黑盒测试
1)功能测试:
(展示)① 排版正常,不出现缺失、重叠等现象; ② 图片正常展示,无明显拉伸; ③ 字体大小样式展示正确,过长截断; ④ 点击跳转正常; ⑤ 用户滑动无卡顿; ⑥ 加载更多无重复
(功能)① 账户在登录和非登录状态下的操作; ② 用户在缺失经纬度时的距离展示; ③ 用户重复操作的结果; ④ 数量的更新; ⑤ 达到上限后需求的下线; ⑥ 时间点等条件的限制
2)性能测试:
① CPU
② 内存占用
③ 耗流量
④ 低配置设备的体验效果
⑤ 弱网测试
⑥ 压测后的QPS、HPS、TPS
⑦ 并发
⑧ 吞吐
⑨ 错误率 -
白盒测试
1)功能测试:
① 正向功能
② 参数不存在
③ 参数为空
④ 参数类型不匹配
⑤ 参数取值:边界值
⑥ tooken无效
⑦ 参数格式不正确
2)性能测试:
① 压力测试:系统在极限压力下的处理能力
② 狭义性能测试:系统能够达到的处理能力
③ 并发测试:测试数据库和应用服务器对并发请求的处理能力
3)安全性测试:
① 伪造tooken攻击
② SQL注入攻击
③ 循环遍历id
4)其他:
同一用户提交的参数信息完全一致,返回结果应该是同一个
6. 如何测试一个post请求方式,参数是String、int的接口
POST方法提交数据给服务器,涉及到Content-Type和消息主体编码方式两部分。服务器根据请求头中的Content-Type来判断消息主体的数据格式和编码方式,数据则存储在body参数中上传。
其实主要考虑以下几点:
① 请求方式
② 无参传入
③ 参数为空
④ 参数类型不匹配
⑤ 参数边界值
⑥ body的格式类型
⑦ tooken无效
⑧ sql注入
⑨ 性能测试:极限压力处理能力、一定的处理能力、并发请求
⑩ 伪造tooken等7. 事务隔离级别
事务具有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)四个特性。
1. 事务隔离级别要实际解决的问题
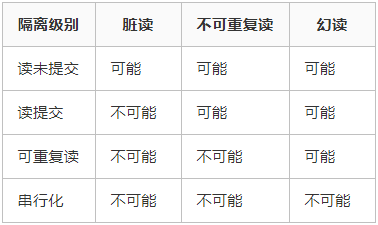
1)脏读:指的是读到了其他事务未提交的数据,即最终不一定存在的事务
2)可重复读:可重复读指的是在一个事务内,最开始读到的数据和事务结束前的任意时刻读到的同一批数据都是一致的。通常针对数据更新(UPDATE)操作
3)不可重复读:对比可重复读,不可重复读指的是在同一事务内,不同的时刻读到的同一批数据可能是不一样的,可能会受到其他事务的影响,比如其他事务改了这批数据并提交了。通常针对数据更新(UPDATE)操作。
4)幻读:幻读是针对数据插入(INSERT)操作来说的。假设事务A对某些行的内容作了更改,但是还未提交,此时事务B插入了与事务A更改前的记录相同的记录行,并且在事务A提交之前先提交了,而这时,在事务A中查询,会发现好像刚刚的更改对于某些数据未起作用,但其实是事务B刚插入进来的,让用户感觉很魔幻,感觉出现了幻觉,这就叫幻读。2. 事务隔离级别
1.)SQL 标准定义了四种隔离级别,MySQL 全都支持。这四种隔离级别分别是:
读未提交(READ UNCOMMITTED)
读提交 (READ COMMITTED)
可重复读 (REPEATABLE READ)
串行化 (SERIALIZABLE)
从上往下,隔离强度逐渐增强,性能逐渐变差。采用哪种隔离级别要根据系统需求权衡决定,其中,可重复读是 MySQL 的默认级别。
2)修改隔离级别的语句是:set [作用域] transaction isolation level [事务隔离级别]
举个栗子:下面这个语句的意思是设置全局隔离级别为读提交级别。
mysql> set global transaction isolation level read committed;
3)具体可以参考:MySQL事务隔离级别和实现原因8. 三次握手四次挥手
参考:TCP三次握手四次挥手
1. 三次握手

注意:我们上面写的ack和ACK,不是同一个概念:- 小写的ack代表的是头部的确认号Acknowledge number, 缩写ack,是对上一个包的序号进行确认的号,ack=seq+1。
- 大写的ACK,则是我们上面说的TCP首部的标志位,用于标志的TCP包是否对上一个包进行了确认操作,如果确认了,则把ACK标志位设置成1
2. 四次挥手

在第四次挥手时,Client端向Server端发送标志位是ACK的报文段,然后Client端进入TIME_WAIT状态。此时,Client端等待2MSL的时间后依然没有收到回复,则证明Server端已正常关闭,那好,Client端也可以关闭连接了。3. 为何三次握手四次挥手
1)建立连接时因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。所以建立连接只需要三次握手。
2)由于TCP协议是一种面向连接的、可靠的、基于字节流的运输层通信协议,TCP是全双工模式。这就意味着,关闭连接时,当Client端发出FIN报文段时,只是表示Client端告诉Server端数据已经发送完毕了。当Server端收到FIN报文并返回ACK报文段,表示它已经知道Client端没有数据发送了,但是Server端还是可以发送数据到Client端的,所以Server很可能并不会立即关闭SOCKET,直到Server端把数据也发送完毕。当Server端也发送了FIN报文段时,这个时候就表示Server端也没有数据要发送了,就会告诉Client端,我也没有数据要发送了,之后彼此就会愉快的中断这次TCP连接。4. 四次挥手时,Client端为何要等待2MSL时间
MSL:报文段最大生存时间,它是任何报文段被丢弃前在网络内的最长时间。
1)保证TCP协议的全双工连接能够可靠关闭
由于IP协议的不可靠性或者是其它网络原因,导致了Server端没有收到Client端的ACK报文,那么Server端就会在超时之后重新发送FIN,如果此时Client端的连接已经关闭处于CLOESD状态,那么重发的FIN就找不到对应的连接了,从而导致连接错乱,所以,Client端发送完最后的ACK不能直接进入CLOSED状态,而要保持TIME_WAIT,当再次收到FIN的收,能够保证对方收到ACK,最后正确关闭连接。
2)保证这次连接的重复数据段从网络中消失
如果Client端发送最后的ACK直接进入CLOSED状态,然后又再向Server端发起一个新连接,这时不能保证新连接的与刚关闭的连接的端口号是不同的,也就是新连接和老连接的端口号可能一样了,那么就可能出现问题:如果前一次的连接某些数据滞留在网络中,这些延迟数据在建立新连接后到达Client端,由于新老连接的端口号和IP都一样,TCP协议就认为延迟数据是属于新连接的,新连接就会接收到脏数据,这样就会导致数据包混乱。所以TCP连接需要在TIME_WAIT状态等待2倍MSL,才能保证本次连接的所有数据在网络中消失。9. 进程通信方式
参考:进程通信和线程通信
-
进程通信:
1)管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
2)有名管道namedpipe:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
3)信号量semophore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
4)消息队列messagequeue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
5)信号signal:信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
6)共享内存shared memeory:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC (其实交“网络摄像机”,是IP Camera的简称)方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
7)套接字socket:套接口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同设备及其间的进程通信。 -
线程通信:
1)锁机制:包括互斥锁、条件变量、读写锁
-互斥锁提供了以排他方式防止数据结构被并发修改的方法。
-读写锁允许多个线程同时读共享数据,而对写操作是互斥的。
-条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
2)信号量机制(Semaphore):包括无名线程信号量和命名线程信号量
3)信号机制(Signal):类似进程间的信号处理 -
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制。
10. 数组和链表
-
数组
1)在内存中,数组是一块连续的区间
2)数组需要预留空间:在编译阶段就需要确定数组的空间,在运行阶段不允许更改,对空间的利用率较低,会存在浪费空间的现象
3)在数组的起始位置,插入和删除元素的效率较低
4)随机访问效率较高,时间复杂度可以达到O(1) 【优点】
5)数组的空间在不够用时需要进行扩容,扩容时需要将旧数组中所有元素向新数组中搬移,浪费资源
6)数组的空间是从栈分配的 -
链表
1)在内存中,元素的空间是分散的,不需要连续的空间
2)链表中的元素都会有两个属性,一个是元素的值,一个是指针地址,用于找到下一个元素的位置
3)查找数据效率较低,时间复杂度为O(N),需要遍历查找
4)空间不需要提前申请,是动态申请的,空间利用率高
5)任意位置插入元素和删除元素效率较高,时间复杂度为O(1)
5)链表的空间是从堆中分配的 -
优缺点
1)数组
优点:随机访问效率高
缺点:① 头插/头删效率低,时间复杂度为O(N); ② 空间利用率不高; ③ 对内存空间要求高,必须又足够的连续内存空间; ④ 数组大小固定,不能动态扩展
2)链表
优点:① 任意位置插入和删除元素效率高,时间复杂度为O(1); ② 内存利用率高,不会浪费内存; ③ 空间大小不是固定的,可以动态扩展
缺点:随机访问效率低,时间复杂度为O(N) -
小结
对于想要快速访问,而不经常进行插入删除元素就选择数组;
对于需要经常插入删除元素,对随机访问的效率要求不是很高时选择链表
11. java多线程实现方式(未弄完)
多线程的形式上实现方式主要有两种,一种是继承Thread类,一种是实现Runnable接口。本质上实现方式都是来实现线程任务,然后启动线程执行线程任务(这里的线程任务实际上就是run方法)。
1)继承Thread类,重写run方法,调用strat才可以启动线程package com.kingh.thread.create; /** * 继承Thread类的方式创建线程 * * @author public class CreateThreadDemo1 extends Thread { public CreateThreadDemo1() { // 设置当前线程的名字 this.setName("MyThread"); } @Override public void run() { // 每隔1s中输出一次当前线程的名字 while (true) { // 输出线程的名字,与主线程名称相区分 printThreadInfo(); try { // 线程休眠一秒 Thread.sleep(1000); } catch (Exception e) { throw new RuntimeException(e); } } } public static void main(String[] args) throws Exception { // 注意这里,要调用start方法才能启动线程,不能调用run方法 new CreateThreadDemo1().start(); // 演示主线程继续向下执行 while (true) { printThreadInfo(); Thread.sleep(1000); } } /** * 输出当前线程的信息 */ private static void printThreadInfo() { System.out.println("当前运行的线程名为: " + Thread.currentThread().getName()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
2)实现Runnable接口,重写run
3) 使用匿名内部类,实现创建Thread子类的方式new Thread(){ … run(){}}.start();
4) 使用匿名内部类,实现 实现Runnable接口的方式
5) 使用Lambda表达式(lambda本质上是一个“匿名函数”)
(其实lambda表达式一般用于一个方法的实现上,该方法可以作为参数传入)
6) 使用线程池
7) 使用Callable(中间类FutureTask进行辅助,是获取结果的凭证)可参考:多线程创建方式
12. 线程的run()和start()有什么区别?
注意:在启动线程的时候,并不是调用线程类的run方法,而是调用了线程类的start方法。那么我们能不能调用run方法呢?
答案是肯定的,因为run方法是一个public声明的方法,因此我们是可以调用的,但是如果我们调用了run方法,那么这个方法将会作为一个普通的方法被调用,并不会开启线程。这里实际上是采用了设计模式中的模板方法模式,Thread类作为模板,而run方法是在变化的,因此放到子类来实现。
1)run()方法
run() 方法是线程的主体,它是线程需要执行的方法,线程启动后会自动执行 run() 方法中的代码。run() 方法通常包含线程的执行逻辑,可以通过重写 run() 方法来实现自定义逻辑。
2)start()方法
start() 方法是线程的启动方法,它是一个系统级别的方法,用于启动一个新线程。start() 方法会使 JVM 开辟一个新的线程,并在新的线程中运行当前线程对象的 run() 方法,而不是 run() 方法在当前线程中直接执行。也就是说,调用 start() 方法后,线程的状态变为可运行状态,JVM 会自动创建一个新线程,并在新线程中执行 run() 方法,直到 run() 执行结束或者调用了 stop() 方法。
3)小结
run() 方法是用户自定义的业务方法,直接调用 run() 仅仅是方法的调用;而 start() 方法是启动新线程的方法,内部会自动调用 run() 方法来执行线程的任务。13. 索引的概念、类型、优劣和使用注意
- 概念
索引是为了加速对表中数据行的检索而创建的一种分散的存储结构,实现原理(B+树) 。通俗点说类似于一本书的目录,通过目录可以快速查到你想要的数据。 - 优缺点
1)优点: 加快索引速度,大大减少查询时间,加索引比普通查询快很多
2)缺点:① 索引的创建和维护需要时间,随着数量增减需要的时间也会增加; ② 索引是需要占用物理空间的(也就是常说的用空间换时间),表空间是有最大上限设置的,如果一个表有大量索引会更快的到达上限值 - 使用注意
① 索引用在where条件经常使用的列
② 加索引列的内容不要频繁变化
③ 加索引列的内容不是唯一的几个值
④ 加索引列的值可以为null,并且可以存在多个null,但是不能有重复的空字符串“”
⑤ 对于创建多个列索引,如果不是一起使用的话,查询时索引不会起作用
⑥ 模糊查询时,like前面以%开头索引会失效
⑦ 如果该列类型是字符串,则作为条件查询时该列的值一定要用’ '引起来,否则索引失效
⑧ 如果条件中带or,那么条件中带索引会失效 - 类型
1)普通索引
普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。
CREATE INDEX index_name ON table(column)- 1
2)唯一索引
索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。CREATE UNIQUE INDEX indexName ON table(column)- 1
3)主键索引
主键索引是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引。CREATE TABLE 'table' ( 'id' int(11) NOT NULL AUTO_INCREMENT , PRIMARY KEY ('id') );- 1
- 2
- 3
- 4
4)组合索引(复合索引)
用户可以在多个列上建立索引,这种索引叫做复合索引(组合索引) 。查询时使用创建时第一个开始索引才有效,使用遵循左前缀集合。ALTER TABLE `tableName` ADD INDEX indexName (name,xb,age);- 1
14. 数据库查询的左外连接、分组、排序、删除、修改、更新
-
左外连接LEFT JOIN或LEFT OUTER JOIN
左向外联接的结果集包括 LEFT OUTER子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。 -
右外连接right join
其实左外连接和右外连接就相当于是给字段匹配的行做笛卡尔积,不匹配的就保持原有行,另外的为null
select a.*,b.* from a left join b on a.id=b.parent_id- 1
-
内连接inner join 和完全连接full join
① 内连接inner join:只输出匹配相等的值
② 完全连接full join:匹配成功的行以及左边表和右边表中未匹配成功的行,没有置null -
分组group by
select column_name from table_name group by column_name having conditions;- 1
在 group by子句之后处理having 子句,所以不能通过使用列别名来引用选择列表中指定的聚合函数。也就是说group by之后select出满足的,再进行having筛选出select。
- 排序order by
select 表字段 from 表名 order by 表字段 desc- 1
默认是升序asc
- 删除
delete from table_name where conditions; truncate table table_name; drop table table_name;- 1
- 2
- 3
① delete属于DML(数据操纵语言),drop和truncate属于DDL(数据定义语言)
② 执行效率:drop>truncate>delete
③ delete删除的数据可以恢复,另外俩不可以
④ 补充:
DQL:数据查询语言,由select… from…where…组成的语句
DML:数据操作语言,如insert、update、delete
DDL:数据定义语言,如create、drop、truncate,隐式操作,不能回滚
DCL:数据控制语言,如GRANT授权,ROLLBACK [WORK] TO [SAVEPOINT]回滚,COMMIT [WORK]提交- 修改alter
alter table table_name add/modify column_name ...- 1
参考:alter的使用
- 更新update
UPDATE student SET age=18,name='李' WHERE name='赵' or age=16- 1
- 2
- 3
15. delete、drop和truncate的区别
- 相同点:都可以删除整张表中的数据
- 不同点:
1)删除范围:drop(删除表中所有数据及表结构)>truncate(删除表中所有数据)>=delete(删除表中所有数据或部分数据)
2)查询条件:delete可以使用查询条件where进行表中数据删除,drop和truncate不可以
3)命令类型:delete属于DML,drop和truncate属于DDL
4)是否可恢复:delete删除的数据可以恢复/回滚,但是drop和truncate删除的数据不能恢复(隐式提交,不会触发触发器)
5)执行效率:drop>truncate>delete
6)删除方式:delete一行一行删除,并且由操作日志
7)空间释放:DELETE操作不会减少表或索引所占用的空间;当表被TRUNCATE 后,这个表和索引所占用的空间会恢复到初始大小。
8)操作对象:DELETE可以是table和view,其余只能是table
参考:drop、delete和truncate的区别
16. 四种常用修饰符
public > protected > default > private

17. Linux常用命令并解释(未弄完)
1)more:适用于查看内容较多的文本文件

2)echo终端输出,>和>>重定向echo hello world > a.txt- 1
(1)ls -l > 文件 (功能描述:列表的内容写入文件 a.txt 中(覆盖写)) (2)ls -al >> 文件 (功能描述:列表的内容追加到文件 aa.txt 的末尾) (3)cat 文件 1 > 文件 2 (功能描述:将文件 1 的内容覆盖到文件 2) (4)echo “内容” >> 文件- 1
- 2
- 3
- 4
> 覆盖写
>>末尾追加3)磁盘查看:df
4)查找文件:find path -name ‘file.txt’18. OSI七层模型,每层的作用是什么
参考:OSI七层模型及其作用
-
OSI七层模型

-
TCP/IP五层协议

-
TCP/UDP协议
1)TCP (Transmission Control Protocol)和UDP(User Datagram Protocol)协议属于传输层协议。
2)其中TCP提供IP环境下的数据可靠传输,它提供的服务包括数据流传送、可靠性、有效流控、全双工操作和多路复用。通过面向连接、端到端和可靠的数据包发送。通俗说,它是事先为所发送的数据开辟出连接好的通道,然后再进行数据发送;而UDP则不为IP提供可靠性、 流控或差错恢复功能。
3)一般来说,TCP对应的是可靠性要求高的应用,而UDP对应的则是可靠性要求低、传输经济的应用。
4)TCP支持的应用协议主要 有:Telnet、FTP、SMTP等;UDP支持的应用层协议主要有:NFS(网络文件系统)、SNMP(简单网络管理协议)、DNS(主域名称系统)、TFTP(通用文件传输协议)等.
5)TCP/IP协议与低层的数据链路层和物理层无关,这也是TCP/IP的重要特点 -
OSI七层参考模型的各个层次的划分遵循下列原则:
1)同一层中的各网络节点都有相同的层次结构,具有同样的功能。
2)同一节点内相邻层之间通过接口(可以是逻辑接口)进行通信。
3)七层结构中的每一层使用下一层提供的服务,并且向其上层提供服务。
4)不同节点的同等层按照协议实现对等层之间的通信。
19. 左连接和右连接的区别
1)意思不一样:左连接只要左表有数据就可以检索到,影响的是右表
2)空值不一样:左连接中若左表条件数据在右表中没有,此时输出结果右表中数据置null20. 微信朋友圈点赞如何设计测试用例
1)界面:图片、文字、排版、时间、版本的适应
2)功能:点赞人、被点赞人、消息提醒、内容类型、点赞人数、点赞展示是否按时间排序
3)性能:并发、压力
4)兼容性:系统、微信版本、手机型号、手机低配、加载速度
5)弱网:
6)安全性:其他人能否看到非共同好友点赞,屏蔽删除能否点赞
7)安装/卸载/换设备
8)未加好友能否点赞
9)易用性:
10)容错性:关机、内存不够、断网等

21. 动态规划描述
参考:动态规划详解
- 概念
通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。动态规划常常适用于有重叠子问题和最优子结构性质的问题。 - 核心思想
动态规划最核心的思想,就在于拆分子问题,记住过往,减少重复计算 - 解题特征
如果一个问题,可以把所有可能的答案穷举出来,并且穷举出来后,发现存在重叠子问题,就可以考虑使用动态规划。
比如一些求最值的场景,如最长递增子序列、最小编辑距离、背包问题、凑零钱问题等等,都是动态规划的经典应用场景。
- 解题思路
① 穷举分析
② 确定边界
③ 找出规律,确定最优子结构
④ 写出状态转移方程 - 经典题型
动态规划有几个典型特征:最优子结构、状态转移方程、边界、重叠子问题。
在青蛙跳阶问题中:
f(n-1)和f(n-2) 称为 f(n) 的最优子结构
f(n)= f(n-1)+f(n-2)就称为状态转移方程
f(1) = 1, f(2) = 2 就是边界啦
比如f(10)= f(9)+f(8),f(9) = f(8) + f(7) ,f(8)就是重叠子问题
public class Solution { public int numWays(int n) { if (n<= 1) { return 1; } if (n == 2) { return 2; } int a = 1; int b = 2; int temp = ; for (int i = 3; i <= n; i++) { temp = (a + b)% 1000000007; a = b; b = temp; } return temp; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
22. 字符串S和T,返回S中包含T中所有字符的连续字串
-
思路:判断长度比较,hashMap使用,使用滑动窗口双指针
left和right从左边开始,right开始移动,比较当前字符是否出现在t中,若t中所有字符串均出现,此时就是一个满足条件的字符串,可以使用subString进行输出;然后left++,看目前left到right的部分是否包含t中所有字符,包含则输出,然后left++;若不包含则right++。可以使用HashMap进行存储判断是否存在(以数量进行判断)

-
参考:最小覆盖字串
-
getOrDefault()的使用
① getOrDefault() 方法获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值。
② getOrDefault() 方法的语法为:
hashmap.getOrDefault(Object key, V defaultValue)- 1
23. 判断一棵树是平衡二叉树
所谓的平衡二叉树是指以当前结点为根结点的树,左右子树的高度差不得超过1。
注意:空树也是平衡二叉树。- 思路:
平衡:root左子树高度-root右子树高度<=1 && root左右子树都平衡(递归实现) +判断空树 - 代码:
1)时间复杂度:O(N2)
// 二叉树的最大深度: public int maxDepth(TreeNode root) { // 其实就相当于层序遍历并记录:注意递归不在三目运算符中 // 如何判断一层遍历结束 if(root==null) { return 0; } // 返回是要判断左子树深还是右子树深 int leftTree = maxDepth(root.left); int rightTree = maxDepth(root.right); return (leftTree>rightTree? (leftTree+1):(rightTree+1)); } // 判断平衡二叉树 public boolean isBalanced(TreeNode root) { if(root==null) { return true; } // 返回是要判断左子树深还是右子树深 int leftTree = maxDepth(root.left); int rightTree = maxDepth(root.right); // 为什么绝对值要小于等于1:平衡树的定义--每个结点的左右子树(子结点)高度相差<=1 // 平衡:每个结点的左右子树相差不超过1 && 左右子树均平衡 return ((Math.abs(leftTree-rightTree)<=1) && (isBalanced(root.left)) && (isBalanced(root.right))); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
② 优化版:时间复杂度O(N)
// 但是上面的方法时间复杂度:O(N^2) // 改进:边遍历边判断是否平衡,降低时间复杂度为O(n) public int maxDepth2(TreeNode root) { if (root==null) { return 0; } int leftTree = maxDepth2(root.left); int rightTree = maxDepth2(root.right); if(leftTree>=0 && rightTree>=0 && (Math.abs(leftTree-rightTree)<=1)) { return (Math.max(leftTree,rightTree)+1); } else { return -1; } } public boolean isBalanced2(TreeNode root) { return maxDepth2(root)>=0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 二叉树相关练习题参考二叉树练习题
24. 线程和进程的区别
1)进程包含线程;
2)线程比进程更轻量,创建更快、销毁也更快;
3) 同一个进程的多个线程之间共用一份内存和文件资源,而进程和进程之间则是独立的文件和内存资源;线程共用资源就省去了线程分配资源的过程
4) 进程是资源分配的基本单位,线程是调度执行的基本单位25. 线程池是什么
具体参考线程池详解
-
概念
线程池是一种利用池化技术思想来实现的线程管理技术,主要是为了复用线程、便利地管理线程和任务、并将线程的创建和任务的执行解耦开来。我们可以创建线程池来复用已经创建的线程来降低频繁创建和销毁线程所带来的资源消耗。在JAVA中主要是使用ThreadPoolExecutor类来创建线程池,并且JDK中也提供了Executors工厂类来创建线程池(不推荐使用)。 -
优点
① 降低资源消耗,复用已创建的线程来降低创建和销毁线程的消耗。
② 提高响应速度,任务到达时,可以不需要等待线程的创建立即执行。
③ 提高线程的可管理性,使用线程池能够统一的分配、调优和监控。 -
ThreadPoolExecutor类的构造方法
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
① corePoolSize,核心线程数量,决定是否创建新的线程来处理到来的任务
② maximumPoolSize,最大线程数量,线程池中允许创建线程地最大数量
③ keepAliveTime,线程空闲时存活的时间
④ unit,空闲存活时间单位
⑤ workQueue,任务队列,用于存放已提交的任务
⑥ threadFactory,线程工厂,用于创建线程执行任务
⑦ handler,拒绝策略,当线程池处于饱和时,使用某种策略来拒绝任务提交-
handler拒绝策略
① AbortPolicy:中断策略,直接抛异常 handler(回调,处理方法)
② CallerRunsPolicy:调用者来执行,而不是被调用者来执行(按理来说是被调用者执行);如果调用者也不执行就丢弃该任务
③ DiscardOldestPolicy:丢弃最老的未处理请求
④ DiscardPolicy:直接丢弃最新的任务
(实际开发中,需要根据请求来决定使用哪种策略) -
线程池五种状态

26. get和post的区别
http请求方法get和post是最常被用到的两个方法,get常用于向服务器请求数据,post常用于提交数据给服务器处理。
GET方法其实也可以传递少量的数据。 但它存在以下问题:- GET 方法不包含body,因此以在URL中拼接字段的方式传递数据,
2)GET方法中的URL参数会被显示到地址栏上,存在安全问题
3)GET传递的数据只能是键值对,无法传递其他类型的数据
因此出于传递大量、多种类型的数据和安全性的考虑,上传数据常使用post方法
① GET请求参数放在url中,不同浏览器和服务器会对长度进行不同的限制;post请求无限制
② get请求刷新服务器或者回退没有影响,post请求回退时会重新提交数据请求
③ get请求可以被缓存,post请求不会被缓存
④ get请求会被保存在浏览器历史记录当中,post不会。get请求可以被收藏为书签,因为参数就在url中;但post不能,它的参数不在url中。
⑤ get请求只能进行url编码(appliacation-x-www-form-urlencoded),post请求支持多种(multipart/form-data等)
参考get和post区别
27. 从输入一个网址到展示页面经历了哪些过程,用了哪些通信协议
1)DNS域名解析:本地hosts文件、 浏览器缓存、 本地域名解析服务器->根域名服务器 ->顶级域名服务器 -> 二级域名服务器 -> 将域名解析为IP地址。(通信协议:DNS协议)
2)三次握手建立连接:(通信协议:TCP)
3)发送HTTP请求:客户端给服务器发送HTTP请求,携带请求内容。(通信协议:HTTP)
4)服务器处理请求:服务器想文件系统等中检索需求所需内容
5)将处理结果返回给客户端:通过之前建立好的TCP进行返回
6)浏览器接收响应,并看情况关闭TCP(TCP四次挥手)
7)解析详细并进行渲染,最终在页面上显示
参考:url到页面渲染28. 白盒测试需要遵循的原则
1)保证一个模块中的所有独立路径至少被测试一次。
2)对所有的逻辑判定均需测试取真和取假两种情况。
3)在上下边界及可操作范围内运行所有循环。
4)检查程序的内部数据结构,保证其结构的有效性。

29. 深拷贝和浅拷贝
Ps.基本数据类型储存在栈中,而引用数据类型在栈中存储的是引用地址,实际的值存储在堆中
- 深拷贝(Deep Copy)和浅拷贝(Shallow Copy)是在进行对象拷贝时常用的两种方式,它们之间的主要区别在于是否复制了对象内部的数据。
1)浅拷贝只复制了对象本身,不会复制对象内部的数据。
2)深拷贝递归地复制了对象及其所有子对象的内容。
3) 引用拷贝是将一个对象的引用赋值给另一个变量,使得两个变量指向同一个对象。 - 浅拷贝修改原来对象的值会同步改变,深拷贝各自独立。
30. TCP和UDP的区别
1)连接:
TCP是面向连接的传输层协议,传输数据前需要先建立连接;UDP不需要建立连接,即时通信
2)服务对象:
TCP 是一对一的两点服务,即一条连接只有两个端点。
UDP 支持一对一、一对多、多对多的交互通信。
3)可靠性:
TCP 是可靠交付数据的,数据可以无差错、不丢失、不重复、按需到达。
UDP 是尽最大努力交付,不保证可靠交付数据。
4)拥塞控制、流量控制
TCP 有拥塞控制和流量控制机制,保证数据传输的安全性。
UDP 则没有,即使网络非常拥堵了,也不会影响 UDP 的发送速率。
5)首部开销
TCP 首部长度较长,会有一定的开销,首部在没有使用「选项」字段时是 20 个字节,如果使用了「选项」字段则会变长的。
UDP 首部只有 8 个字节,并且是固定不变的,开销较小
6)传输方式
TCP 是流式传输,没有边界,但保证顺序和可靠。
UDP 是一个包一个包的发送,是有边界的,但可能会丢包和乱序。
7)分片不同
TCP 的数据大小如果大于 MSS 大小(除去 IP 和 TCP 头部之后,一个网络包所能容纳的 TCP 数据的最大长度),则会在传输层进行分片,目标主机收到后,也同样在传输层组装 TCP 数据包,如果中途丢失了一个分片,只需要传输丢失的这个分片。
UDP 的数据大小如果大于 MTU 大小(最大传输单元,是可以在网络中传输的最大数据包大小),则会在 IP 层进行分片,目标主机收到后,在 IP 层组装完数据,接着再传给传输层31. 锁(未弄完)
https://www.cnblogs.com/lifegoeson/p/13683785.html
32. 自动化测试中selenium等待的类型
- 通过在脚本中设置等待的方式来避免由于网络延迟或浏览器卡顿导致的元素找不到的偶然失败问题
- 常用的三种等待
1)强制等待
① 利用time模块的sleep方法来实现,最简单粗暴的等待方法
② 弊端:严重影响代码的执行速度
# 强制等待3秒 time.sleep(3)- 1
- 2
2)隐式等待
① implicitly_wait()方法用来等待页面加载完成(直观的就是浏览器tab页上的小圈圈转完)网页加载完成则执行下一步
② 隐式等待只需要声明一次,一般在打开浏览器后进行声明
③ 声明之后对整个drvier的生命周期都有效,后面不用重复声明
④ 弊端:程序会一直等待页面加载完成,直到超时。有时我们需要的元素已经加载完成,但是依旧需要等待页面上所有的元素都加载完成才能下一步# 隐性等待5秒 driver.implicitly_wait(5)- 1
- 2
3)显示等待
①WebDriverWait,配合该类的until()和until_not()方法,就能够根据判断条件而进行灵活地等待了
② 它主要的意思就是:程序每隔xx秒看一眼,如果条件成立了,则执行下一步;否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException
③ 显示等待必须在每个需要等待的元素前面进行声明33. 数据库常用语句(未弄完)
34. app与web测试的区别
参考:web与app端测试
Ps. APP需要关注:安装/卸载/更新、中断(如关机、电话、短信等)、专项测试(如网络适配性、运营商环境、WIFI)、交互(鼠标、点击/手势/横屏等)、升级测试(原有功能、用户数据等)1)系统架构方面
web项目,b/s架构,基于浏览器的;web测试只要更新了服务器端,客户端就会同步会更新
app项目,c/s结构的,必须要有客户端;app 修改了服务端,则客户端用户所有核心版本都需要进行回归测试一遍
2)性能方面
web项目 需监测 响应时间、CPU、Memory、点击率、TPS、并发等
app项目 除了监测 响应时间、CPU、Memory外,还需监测流量、电量等
3)兼容方面
① web项目:
浏览器(火狐、谷歌、IE等)
操作系统(Windows7、Windows10、OSX、Linux等)
② app项目:
设备系统: iOS(ipad、iphone)、Android(三星、华为、联想等) 、Windows(Win7、Win8)、OSX(Mac)
手机设备可根据 手机型号、分辨率不同
4)相对于web项目,app华友专项测试
① 干扰测试:中断,来电,短信,关机,重启等
② 弱网络测试(模拟2g、3g、4g,wifi网络状态以及丢包情况);网络切换测试(网络断开后重连、3g切换到4g/wifi 等)
③ 安装、更新、卸载
安装:需考虑安装时的中断、弱网、安装后删除安装文件等情况
卸载:需考虑 卸载后是否删除app相关的文件
更新:分强制更新、非强制更新、增量包更新、断点续传、弱网状态下更新
5)测试工具
自动化工具:APP 一般使用 Appium; Web 一般使用 Selenium
性能测试工具:APP 一般使用 JMeter; Web 一般使用 LR、JMeter
6)界面操作:关于手机端测试,需注意手势,横竖屏切换,多点触控,前后台切换
7)安全测试:安装包是否可反编译代码、安装包是否签名、权限设置,例如访问通讯录等
8) 边界测试:可用存储空间少、没有SD卡/双SD卡、飞行模式、系统时间有误、第三方依赖(QQ、微信登录)等
9)权限测试:设置某个App是否可以获取该权限,例如是否可访问通讯录、相册、照相机等
10)升级测试:升级后原有功能是否受影响,用户数据是否丢失35. wait和sleep的区别
参考:wait和sleep区别
1)使用限制
① 使用 sleep 方法可以让让当前线程休眠,时间一到当前线程继续往下执行,在任何地方都能使用,但需要捕获 InterruptedException 异常。Thread.sleep(3000L);- 1
② 而使用 wait 方法则必须放在 synchronized 块里面,同样需要捕获 InterruptedException 异常,并且需要获取对象的锁。
synchronized (lock){ try { lock.wait(); } catch (InterruptedException e) { e.printStackTrace(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
而且 wait 还需要额外的方法 notify/ notifyAll 进行唤醒,它们同样需要放在 synchronized 块里面,且获取对象的锁。
2)使用场景
sleep 一般用于当前线程休眠,或者轮循暂停操作;wait 则多用于多线程之间的通信
3)所属类不同
sleep 是 Thread 类的静态本地方法,wait 则是 Object 类的本地方法
4)释放锁
wait 可以释放当前线程对 lock 对象锁的持有,而 sleep 则不会。
5)线程切换
sleep 会让出 CPU 执行时间且强制上下文切换;而 wait 则不一定,wait 后可能还是有机会重新竞争到锁继续执行的。36. 如何保证线程安全
参考线程安全
Java并发的三大基本特性:原子性、可见性以及有序性
解决办法:使用多线程之间使用关键字synchronized、或者使用锁(lock),或者volatile关键字。
① synchronized:自动锁,锁的释放是在synchronized同步代码执行完毕后自动释放。
弊端:多个线程需要判断锁,较为消耗资源、抢锁的资源。
② Lock锁是需要手动去加锁和释放锁,Lock相比于synchronized更加的灵活。tryLock()方法会尝试获取锁,如果锁不可用则返回false,如果锁是可以使用的,那么就直接获取锁且返回true。主动通过unLock()去释放锁。(竞争激烈使用Lock)
③ Volatile 关键字的作用是变量在多个线程之间可见。使用Volatile关键字将解决线程之间可见性,强制线程每次读取该值的时候都去“主内存”中取值。
volatile虽然具备可见性,但是不具备原子性。37. 常见中间件
-
中间件概念
① 中间件(英语:Middleware)顾名思义是系统软件和用户应用软件之间连接的软件,以便于软件各部件之间的沟通
② 总的作用是为处于自己上层的应用软件提供运行与开发的环境,帮助用户灵活、高效地开发和集成复杂的应用软件。 -
了解补充
中间件与操作系统和数据库共同构成基础软件三大支柱,是一种应用于分布式系统的基础软件,位于应用与操作系统、数据库之间,为上层应用软件提供开发、运行和集成的平台。中间件解决了异构网络环境下软件互联和互操作等共性问题,并提供标准接口、协议,为应用软件间共享资源提供了可复用的“标准件”。
-
常见中间件
Tomcat
Weblogic
Jboss
Jetty
Webshere
Glassfish
38. 线程状态
参考:线程状态
线程六种状态
① 初始(NEW):新创建了一个线程对象,但还没有调用start()方法。
② 运行(RUNNABLE):Java线程中将就绪(ready)和运行中(running)两种状态笼统的称为“运行”。
线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取CPU的使用权,此时处于就绪状态(ready)。就绪状态的线程在获得CPU时间片后变为运行中状态(running)。
③ 阻塞(BLOCKED):表示线程阻塞于锁。
④ 等待(WAITING):进入该状态的线程需要等待其他线程做出一些特定动作(通知或中断)。
⑤ 超时等待(TIMED_WAITING):该状态不同于WAITING,它可以在指定的时间后自行返回。
⑥ 终止(TERMINATED):表示该线程已经执行完毕。

39. 死锁产生的条件
循环等待、不可抢占、互斥、请求和保持
40. Bean的生命周期

41. 缺陷的生命周期
42. awk使用
43. 最长回文子串
44. 查看进程
参考:Linux查看进程命令
①ps -aux | grep java是以简单列表的形式显示出进程信息,通常用于查看进程的PID。(静态)
可以使用kill命令终止进程,如:kill -9 [PID],-9表示强迫进程立即停止
② top命令可以实时显示各个线程情况。要在top输出中开启线程查看,请调用top命令的“-H”选项,该选项会列出所有Linux线程。在top运行时,你也可以通过按“H”键将线程查看模式切换为开或关。
③ pstree命令以树状图的方式展现进程之间的派生关系,显示效果比较直观。45. chmod的数字含义
46. Java面向对象的三大特征并进行解释
-
-
相关阅读:
总结:不同的监控系统比较
rk版本编译系统
Git命令总结-常用-后续使用频繁的再添加~
Linux学习-数据类型学习
【Pindex】我用vue做了个“假终端”
MySQL主从复制与读写分离
在VMware上创建虚拟机并安装CentOS
QT几个小知识点总结
python 案例
C11线程池详解
- 原文地址:https://blog.csdn.net/weixin_54150521/article/details/134414733
