-
[PyTorch][chapter 61][强化学习-免模型学习1]
前言:
在现实的学习任务中,环境

其中的转移概率P,奖赏函数R 是未知的,或者状态X也是未知的
称为免模型学习(model-free learning)
目录:
1: 蒙特卡洛强化学习
2:同策略-蒙特卡洛强化学习
3: 异策略- 蒙特卡洛强化学习
一 蒙特卡洛强化学习
在免模型学习的情况下,策略迭代算法会遇到两个问题:
1: 是策略无法评估
因为无法做全概率展开。此时 只能通过在环境中执行相应的动作观察得到的奖赏和转移的状态、
解决方案:一种直接的策略评估代替方法就是“采样”,然后求平均累积奖赏,作为期望累积奖赏的近似,这称为“蒙特卡罗强化学习”。2: 策略迭代算法估计的是 状态值函数(state value function) V,而最终的策略是通过 状态 动作值函数(state-action value function) Q 来获得。
模型已知时,有很简单的从 V 到 Q 的转换方法,而模型未知 则会出现困难。
解决方案:所以我们将估计对象从 V 转为 Q,即:估计每一对 “状态-动作”的值函数。模型未知的情况下,我们从起始状态出发,使用某种策略进行采样,执行该策略T步,
并获得轨迹
 ,
,然后 对轨迹中出现的每一对 状态-动作,记录其后的奖赏之和,作为 状态-动作 对的一次
累积奖赏采样值. 多次采样得到多条轨迹后,将每个状态-动作对的累积奖赏采样值进行平均。即得到 状态-动作值函数的估计.

二 同策略蒙特卡洛强化学习
target Policy : 要优化的策略,也称为原始策略
behavior policy: 用来产生轨迹的策略
在on-policy 方案里面,两个策略相同。
要获得好的值函数估计,就需要不同的采样轨迹。
我们将确定性的策略
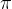 称为原始策略
称为原始策略原始策略上使用
 -贪心法的策略记为
-贪心法的策略记为
以概率
 选择策略1: 策略1 :
选择策略1: 策略1 :
以概率
选择策略2: 策略2:均匀概率选取动作,对于最大化值函数的原始策略

其中
 贪心策略
贪心策略 中:
中:当前最优动作被选中的概率

每个非最优动作选中的概率
 ,多次采样后将产生不同的采样轨迹。
,多次采样后将产生不同的采样轨迹。因此对于最大值函数的原始策略
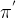 ,同样有
,同样有
算法中,每采样一条轨迹,就根据该轨迹涉及的所有"状态-动作"对值函数进行更新
同策略蒙特卡罗强化学习算法最终产生的是E-贪心策略。然而,引入E-贪心策略是为了便于策略评估,而不是最终使用
三 同策略蒙特卡洛算法 Python
整个算法分为三部分:
迭代
1: 使用behavior policy 生成轨迹
2: 根据轨迹的样本,进行策略评估
3: 根据策略评估的结果Q(累积奖赏),优化target policy(选择状态-动作 最大值)

- import numpy as ap
- # -*- coding: utf-8 -*-
- """
- Created on Fri Nov 3 09:37:32 2023
- @author: chengxf2
- """
- # -*- coding: utf-8 -*-
- """
- Created on Thu Nov 2 19:38:39 2023
- @author: cxf
- """
- import random
- from enum import Enum
- class State(Enum):
- #状态空间#
- shortWater =1 #缺水
- health = 2 #健康
- overflow = 3 #溢水
- apoptosis = 4 #凋亡
- class Action(Enum):
- #动作空间A#
- water = 1 #浇水
- noWater = 2 #不浇水
- class Env():
- def getReward(self, nextState):
- #针对转移到新的环境奖赏
- r = -100
- if nextState is State.shortWater:
- r =-1
- elif nextState is State.health:
- r = 1
- elif nextState is State.overflow:
- r= -1
- else:
- r = -100
- return r
- def action(self, state, action):
- if state is State.shortWater:
- #print("\n state--- ",state, "\t action---- ",action)
- if action is Action.water :
- S =[State.shortWater, State.health]
- proba =[0.4, 0.6]
- else:
- S =[State.shortWater, State.apoptosis]
- proba =[0.5, 0.5]
- elif state is State.health:
- #健康
- if action is Action.water :
- S =[State.health, State.overflow]
- proba =[0.6, 0.4]
- else:
- S =[State.shortWater, State.health]
- proba =[0.6, 0.4]
- elif state is State.overflow:
- #溢水
- if action is Action.water :
- S =[State.overflow, State.apoptosis]
- proba =[0.6, 0.4]
- else:
- S =[State.health, State.overflow]
- proba =[0.6, 0.4]
- else:
- #凋亡
- S =[State.apoptosis]
- proba =[1.0]
- #print("\n S",S, "\t prob ",proba)
- nextState = random.choices(S, proba)[0]
- reward= self.getReward(nextState)
- return nextState,reward
- def __init__(self):
- self.name = "环境空间"
- class Agent():
- def initPolicy(self):
- self.Q ={} #累积奖赏
- self.count ={} #[state,action] 出现的次数
- for state in self.S:
- for action in self.A:
- self. Q[state, action] = 0
- self.count[state,action]= 0
- def behavior(self,state):
- #使用行为策略 behavior-policy
- r = random.random()
- if r<self.epsi:
- #使用随机策略
- A= self.A
- randProb =[0.5,0.5]
- action = random.choices(A, randProb)[0]
- else:#使用target policy >1-epsi
- action = self.policy[state]
- return action
- def generate(self,T):
- #使用行为策略(e贪心策略),产生轨迹
- #轨迹[s0,a0,r0],[s1,a1,r1]......[rT-1,aT-1,rT-1]
- env = Env()
- state = State.shortWater #从缺水开始
- trajectory ={}
- for t in range(T):
- action = self.behavior(state)
- nextState,reward = env.action(state, action)
- trajectory[t] =[state, action, reward]
- state = nextState
- return trajectory
- def evaluate(self,T ,trajectory):
- #策略评估
- denominator =0
- for t in range(0,T):
- denominator =T-t
- R_t = 0
- acc = 0
- for i in range(t,T):
- r = trajectory[i][-1]
- acc = acc+r
- R_t = acc/denominator #t时刻的累积奖赏
- state_t = trajectory[t][0]
- action_t = trajectory[t][1]
- count = self.count[state_t, action_t]
- self.Q[state_t, action_t] = (self.Q[state_t, action_t]*count+R_t)/(count+1)
- self.count[state_t, action_t] +=1
- def improve(self):
- #策略提升
- for state in self.S:
- maxReward = self.Q[state,Action.water]
- for action in self.A:
- reward = self.Q[state,action]
- if reward>=maxReward:
- maxReward = reward
- self.policy[state] = action
- #print("\n state ",state, "\t maxReward ",maxReward)
- def learn(self):
- self.initPolicy()
- #target policy 最终要优化的策略
- self.policy ={}
- T =15
- for state in self.S:
- self.policy[state] = Action.noWater
- for s in range(1,self.epsidode): #采样第S 条轨迹
- #使用e 贪心策略生成轨迹
- trajectory = self.generate(T)
- #策略评估
- self.evaluate(T, trajectory)
- print("\n 迭代次数 %d"%s ,"\t 缺水:",self.policy[State.shortWater].name,
- "\t 健康:",self.policy[State.health].name,
- "\t 溢水:",self.policy[State.overflow].name,
- "\t 凋亡:",self.policy[State.apoptosis].name)
- #策略improve
- self.improve()
- def __init__(self):
- self.S = [State.shortWater, State.health, State.overflow, State.apoptosis]
- self.A = [Action.water, Action.noWater]
- self.Q ={} #累积奖赏
- self.count ={}
- self.policy ={}
- self.epsidode =1000
- self.epsi = 0.2
- if __name__ == "__main__":
- agent = Agent()
- agent.learn()
-
相关阅读:
【Java面试】MongoDB
【JavaWeb】Servlet属性设置
EVE111
原始资料的收集方法———定性资料的收集
oracle在Windows正常使用需要启动哪些服务
普中51-独立按键实验
Spring MVC 的核心组件有哪些?
java计算机毕业设计springboot+vue社区养老管理系统(源码+系统+mysql数据库+Lw文档)
百日刷题计划 ———— DAY2
基于JAVA医院预约挂号系统计算机毕业设计源码+系统+mysql数据库+lw文档+部署
- 原文地址:https://blog.csdn.net/chengxf2/article/details/134183448
