-
大模型微调发展-学习调研总结
模型微调前言
https://blog.csdn.net/weixin_39663060/article/details/130724730
针对于小公司,如何能够利用开源的大模型,在自己的数据上继续训练,从而应用于自己的业务场景?或低成本的方法微调大模型。
目前主流的方法包括2019年Houlsby N等人提出的Adapter Tuning, 2021年微软提出的LORA,斯坦福提出的Prefix-Tuning,谷歌提出的Prompt Tuning, 2022年清华提出的P-tuning V2.方法各自都有自己的特点,从个人使用情况来说,LORA的效果会好与其他几种方法。其他方法都有各自的一些问题:
- Adapter Tuning 增加了模型层数,引入了额外的推理延迟 zhuanlan.zhihu.com/p/574191259
- Prefix-Tuning 难于训练,且预留给Prompt的序列挤占了校友任务的输入序列空间,影响模型性能
- P-tuning V2很容易导致旧知识遗忘,微调之后的模型,在之前的问题上表现明显变差。
lora微调
www.zhihu.com/zvideo/1641972168081883136
Fine-tuning微调
利用已知的网络结构和已知的网络参数,修改output层为我们自己的层,微调最后一层前的若干层参数,这样就有效李永乐深度神经网络强大的泛华能力,也免去了复杂模型的计算。fine-tuning是当数据量不足时一个比较合适的选择。
其意义为:1. 基于训练过的模型。2. 若导出特征向量的方法进行迁移学习,后期的训练成本非常低,用CPU也可以。3. 适用于小数据集,不用从头开始重新训练。如果想用上大型神经网络的超强特征提取能力,需要靠迁移学习。
P-tuning
经典的应用场景是:基于p-tuning,可以提高少样本学习能力。如何提供,可以参考华为的盘古模型,其做了两方面努力:一是迁移学习、二是将P-tuning、priming等最新技术融入到盘古的微调框架中,进一步提升微调效果。
提示微调(Instruction Tuning)
一种提升语言模型的Zero-shot能力的方式就是指令微调。
工作大体都符合以下四种NLP范式
范式 第1、2种范式:完全监督学习;非神经网络和神经网络 第3种范式:预训练-微调 第四种范式:预训练-提示学习 训练数据 目标任务数据集 大规模生成语料,目标任务数据集 大规模生成语料;目标任务数据集 输入 我是谁? 我是谁 【CLS】我是谁【SEP】主题是【MASK】【MASK】【SEP】 输出 ,[0,0,1] [0,0,1] 【CLS】哲学【SEP】 输出层 一个线性变换 一个线性变换 无新增结构 特点 依赖目标任务数据集来获得文本表示 良好文本表示;目标任务获得下游任务数据 基于庞大的新预料来获得良好的文本表示。基于语言模型的文本生成能力,和下游任务特点,设计训练和推理策略 指令也可成为指示,即提示。对于已经掌握了基础语言能力的大模型来说,它通过向数据中注入任务描述,来提升模型的效果。向训练数据中加入任务描述的方式,便是提示学习的雏形。
针对任务主要做法
总结说有以下两种方式:
-
为输入文本增加(拼接)任务提示语言。
-
将分类标签(或预测目标)替换为与类别有一定语义对应关系的词句。
依据输入:[CLS]待分类文本[SEP]本文的主题是[MASK][MASK][SEP]
得到输出:[CLS]教育[SEP][CLS]哲学[SEP]
LLaMA-关系提取任务
- 论文:Language Model as Knowledge Bases?
文中,提出通过将关系抽取任务(三元组补全)修改为填空题,在不修改与训练语言模型的情况下,得到了比知识库更好的关系抽取效果。具体如下:
如:(Dante, born in, ?)三元组补全任务=》》 “dante was born in _” 任务。预测结果中显示:模型可能在预训练阶段学到了关于事实的知识,而学到的知识对三元组补全任务启动了作用
AutoPrompt-文本分类及蕴涵判断任务【重点研读】
论文阅读:AutoPrompt - 知乎 (zhihu.com) zhuanlan.zhihu.com/p/432575444
详解AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts - 知乎 (zhihu.com) zhuanlan.zhihu.com/p/612143138- 论文: Autoprompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts
论文中使用提示学习的方式做文本分类、文本蕴涵判断任务【蕴涵指的是两个文本之间的推理关系,一个文本为前提,一个为假设。若根据前提P能推理出假设H,则记做P蕴涵H,即P->H】。设计了一种自动得到优质提示模版方式:不改动语言模型,使用基于梯度搜索得到优质提示模版。
文中将关系收取任务改造为:
如:“Dante was born in [T][T][T][T] [MASK]”中被[MASK]遮蔽的部分。
这个模版中【T】是用来引导模型的触发词【提示信息】。论文证明了这些提示词可以提升语言模型的分类能力。详解:
【T】:预训练语言模型中知识或模式是既定的,不一定会按照我们预想的方式预测词语-需要给些“提示”,引导模型去做下游任务。LLAMA把若干触发词添加到文本和【MASK】.PET-使用擅长低资源模型标注去标签数据、扩大训练集
- 论文:Exploting Cloze Questions for Few shot Text Classification and Natural Language inference.
- 提示学习方法
将文本分类任务的输入修改为一个填空题,来让语言模型认识任务,而推理修改为一个文本生成任务,来充分利用语言模型的文本生成能力。比如情感类分类任务,原本输入:我喜欢这本电影,输出:正面,改成提示:“我喜欢这本电影,整体来看,这是一个_的电影”
提示函数方法
- 定义提示函数x’ = Fprompt(x),x为输入文本,x’为变换后的函数
- 设计一种模版,其应该包括一个输入模版f(X),一个答案模版f(Z),而f(Z)后续会被映射给最终的输出y。例如句子:“中国国土很大,确实,这是历经五千年积累的国家”,就可以设计成“f(x),确实,这是f(z)”的填空式
- 输入文本x填充f(x)
根据提示任务的分类

提示工程
引用
李鹏宇-zhuanlan.zhihu.com/p/406291495
大师兄-zhuanlan.zhihu.com/p/644369467
zhuanlan.zhihu.com/p/644369467
鹏飞大神的Pre-train-zhuanlan.zhihu.com/p/396098543
P-tuning:用“连续提示微调”来增强“超大规模语言模型”的下游能力
LLM大模型低资源微调p tuning v2和lora区别
Prompt范式第二阶段|Prefix-tuning、P-tuning、Prompt-tuning - 知乎 (zhihu.com)五万字综述!Prompt-Tuning:深度解读一种新的微调范式 - 知乎 (zhihu.com)zhuanlan.zhihu.com/p/618871247
Prompt范式第二阶段|Prefix-tuning、P-tuning、Prompt-tuning - 知乎 (zhihu.com) zhuanlan.zhihu.com/p/400790006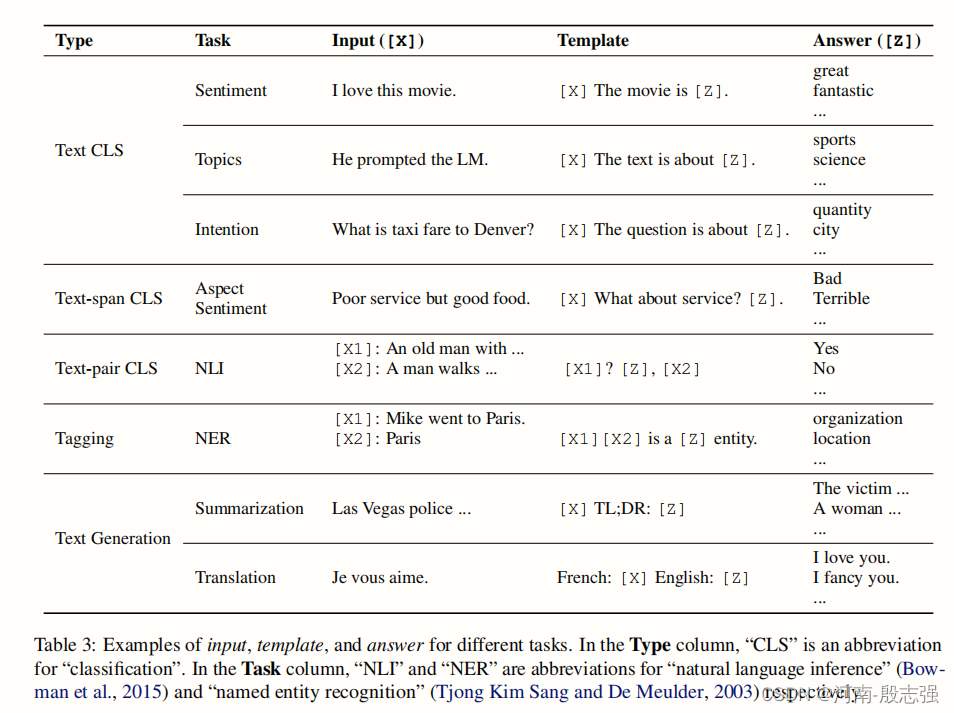
-
相关阅读:
用实例带你深入理解Java内存模型
如何获取springboot中所有的bean
前端性能优化手段
VScode---php环境搭建
C++类模板学习笔记
【SpringCloud】负载均衡
SeaTunnel 2.3.4 Cluster in K8S
日本购物网站的网络乞丐功能
Java 类和对象
AcWing 1294. 樱花
- 原文地址:https://blog.csdn.net/weixin_44077556/article/details/133976244