-
MySQL 性能分析
MySQL 性能分析及索引失效
对 mysql 进行性能分析,主要就是提升查询的效率,其中索引占主导地位。对 mysql 进行性能分析主要有如下几种方式:
性能分析
方式一:查看 sql 执行频次
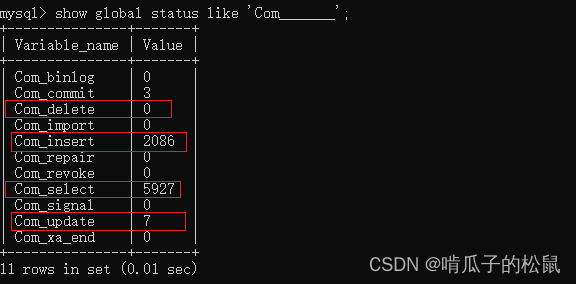
show global status like ‘Com_______’; // global 表示全局
show session status like ‘Com_______’;主要查看select、insert、update、delete四种情况,Value 表示执行的次数。如果 select 次数占大部分,也侧面的告诉了我们 sql 优化的方向,可以考虑给数据库表添加索引来提升查询效率。
方式二:慢查询日志
方式一找到了 sql 优化的方向,因此现在我们需要找到具体的慢 sql。刚好 mysql 也提供了慢查询日志,慢查询日志记录了执行时间超过指定参数(long_query_time,单位:秒。默认是10秒)的所有 sql 语句的日志,默认是没有开启的,需要我们修改配置文件。
- 如果是 Linux 系统下的 mysql,配置文件为:etc/my.cnf
// 开启慢查询日志
slow_query_log=1
long_query_time=2 // 慢查询设置的阈值- 由于本次我的演示为 Windows 版本的 mysql,修改慢查询配置分为指令和配置文件修改。
-
配置文件:C:\ProgramData\MySQL\MySQL Server 8.0\my.ini,具体配置文件为my.ini,如果路径不对可自行查询自己电脑的路径。

-
指令修改:show variables like ‘%quer%’;
show variables like ‘%quer%’; 用于查看 mysql 的各项配置。

set global slow_query_log=‘ON’; // 开启慢查询日志
set global slow_query_log_file=‘D:/logs/slow-sql-log.log’ // 重新设置慢查询的存放路径 -
演示:我已将 long_query_time 修改为 2 秒,person表中插入了一千七百多万行数据。
演示:select * from person;
然后查看慢查询日志文件:

查看具体的 sql 和耗时后,就可以针对该条 sql 进行优化了。
-
方式三:show profiles(详情)
方式二介绍的慢查询日志也有一点的弊端,假如有一条很简单的 sql,但是执行时间为 1.99 秒,因此就不会被记录到日志文件中,但是这确实也是存在的一种慢查询情况,因此引入 show profiles。show profiles 能够在做 sql 优化时帮助我们了解时间都耗费在哪里去了。
-
show profiling :查看当前 mysql 是否支持 prifile 操作
select @@hava_profiling;
-
profiling 默认是关闭的,开启 profiling
select @@profiling; // 查询结果0表示关闭状态,1表示开启
set profiling = 1; // 开启 -
执行几条 sql,然后查看 profiling
select * from person;
select * from person where id = 70935;
select * from person where name = ‘姓名test’;
select count(*) from person; -
查看 show profiles

具体的耗时和 sql 就展示出来了。-
查看指定 query_id 的 sql 语句各个阶段的耗时情况。
show profile for query 2; // 查看query_id 为 2 的耗时情况

-
查看指定 query_id 的 sql 语句 cpu 的使用情况。
show profile cpu for query 2; // 查看query_id 为 2 的耗时情况
-
以上统计情况都仅供我们参考。
方式四:explain 执行计划
前三种都是通过 sql 执行的时间来粗略判断 sql 语句的执行性能,但也并非准确,要想真正判定一条 sql 的性能,可以通过 explain 查看 sql 执行计划。
语法:直接在select 语句之前加上 explain / descexplain select 字段1,字段2… from 表名 where 条件;
对于explain,我上篇笔记【七、MySql 优化->2. explain 介绍】也介绍了一点点:https://blog.csdn.net/weixin_44780078/article/details/131796843
此处再说明一下 type:性能由好到差的连接类型为 NULL、system、const、eq_ref、ref、range、index、all。
- NULL:NULL一般不可能出现,它表示不访问表或索引,比如 select 3; 直接打印 3。
- system:system 出现非常少,他是出现在 MyISAM、memory 的搜索引擎中,比如查询一行指定的数据,并且表中也只有一行数据的时候会出现 system。
- const:用主键或唯一索引查询一行时,一般是 const。
- eq_ref:当使用连接查询(left join、inner join、right join)通过两张表的主键查询一条数据时,会出现 eq_ref。
- ref:当使用非主键字段的索引查询数据时,会出现 ref。
- range:当使用非主键字段的索引查询范围数据时,会出现 range。(比如age建了索引,查询[18,20]范围年龄的人)
- index:使用了索引,但是遍历了整棵索引树,就会出现 index。
- all:全表通查,效率最低。
索引
一、最左前缀原则
如果对多个字段共同建立索引,则称为联合索引,联合索引遵循最左前缀原则。例如对字段name、age、major建立联合索引:(name,age,major)。
最左前缀原则:使用索引查询时必须从索引的最左边开始,不能跳过索引中的列。
对于上述举例联合索引,根据最左前缀原则:
- where name = ‘张三’ and age = 20 and major = ‘软件工程’,效率最高,索引全部生效;
- where name = ‘张三’ and major = ‘软件工程’,跳过了中间的 age,major 字段的索引失效;
- where age = 20 and major = ‘软件工程’,跳过了最左边的 name,索引全部失效;
二、索引失效
索引失效大前提,在加有索引列的字段上做了计算,下面开始逐一举例:
失效场景一:
联合索引中如果索引列使用了范围查询,范围查询后续字段的索引会失效:
如 where name = ‘张三’ and age > 20 and major = ‘软件工程’,major 字段列的索引失效。
失效场景二:
对加索引的字段使用了前模糊查询,或者前后模糊查询:
如 where name = ‘张三’ and major like ‘%工程’;
如 where name = ‘张三’ and major like ‘%工程%’;
失效场景三:
如果使用到了 or 连接条件,如 name = ‘张三’ or class = ‘三年级’,如果 name 字段列建有索引,则索引失效。只有 name 和 class 都建有索引的时候索引才生效。
失效场景四:
使用范围查询时,范围覆盖了整张表的数据或者整张表的大部分数据,mysql 会自行评估放弃走索引。
- 如 person 表有 100 万行数据,age都是 (0,100] 之内的,age 字段建有索引,查询时使用 where age > 0;查询数据包含了整张表,尽管有索引,但也不走索引。
- 再如 peson 表的所有列都有数据,使用 name is not null,明显整张表都是符合条件的,因此也不走所有。
三、索引 - sql提示
sql 提示,是优化数据库的一个重要手段,比如 person 表中单独对 age 字段建立了索引,(age,name,sex)建立了联合索引。这时假如我们要用 age 索引时,mysql 存在对于一种的索引选择。因此此时我们可以加入 sql 提示。
-
use index:建议使用某个索引
// 建议 mysql 使用哪个索引 explain select * from person use index (person_age_IDX) where age = 25;- 1
- 2
-
ignore index:不使用某个索引
// 告诉 mysql 不使用哪个索引 explain select * from person ignore index (person_name_age_sex_IDX) where age = 25;- 1
- 2
-
force index:必须使用哪个索引
// 告诉数据库必须使用哪个索引 explain select * from person force index (person_age_IDX) where age = 25;- 1
- 2
四、前缀索引
当字段类型为字符串(varchar、text)时,有可能字符串很长,因此建立索引也会很大,查询的时候也会浪费大量的磁盘 IO,影响查询效率,这时,可以将字符串的一部分前缀建立索引,从而节约空间、提示效率。
// 语法 create index idx_xxx on table_name(column(n));- 1
- 2
此时需要思考:对于取字符串的一部分建立索引,这里的前缀长度 n 取多少合适呢?
假如字符串只有三个:abcxhj、abczpl、abcfoop;明显可以看出前三位一样,从第四位开始才不一致,因此 n 需取4。
- 选择性:选择性是指不重复的记录数 / 数据表的总行数,选择性越大则代表查询效率最高,这里不难看出最大值为 1。
// 求选择性 sql,可依次缩小 n,找到 n 最小且比值最大的 n 值. select count(distinct substring(name, 1, n)) / count(*) from person;- 1
- 2
- 建立前缀索引:
// 对 name 字段建立前 n 个字符的前缀索引 create index idx_name_n on person(name(n));- 1
- 2
五、索引设计原则
- 针对数据量较大,且查询比较频繁的表建立索引;
- 针对常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引;
- 尽量选择区分度较高的列建立索引,比如主键 id,区分度越高效率越高;
- 如果是字符串字段,存储的字符过长时,可以建立前缀索引;
- 尽量使用联合索引,较少使用单列索引,因此在查询时联合索引很多时候可以有索引覆盖,而单列索引大概率会进行回表查询;
- 索引也不是越多越好,要适可而止,因为对表结构进行修改时索引都需要重构,会影响效率;
六、其他 sql 优化
场景一: 插入数据
-
insert 优化
-
批量插入:因为插入一次都需要进行创建连接、网络传输等等,比较耗时。
insert into person values(1, "张三", "男"), (2, "李四", "女");- 1
建议批量插入时也不要插入太多,1000条左右即可。
- 手动提交事务:mysql的事务是自动开启关闭的,批量插入时频繁开启/关闭影响性能。
start transaction; insert into person values(1, "张三", "男"); insert into person values(2, "赵六", "男"); insert into person values(3, "王五", "男"); commit;- 1
- 2
- 3
- 4
- 5
-
大批量插入:load
-
当我们要插入大批量的数据,比如一下子插入几百万甚至上千万行数据,这时用insert 效率就比较低,改用 load 可提升效率。
1、新建表:
create table user ( id int primary key auto_increment, username varchar(50) unique not null, password varchar(50) not null, name varchar(20) not null, birthday date default null, sex char(1) default null );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2、准备数据:对于字符串不用加引号。
1,张三001,123456,张三,2023-10-31,0 2,张三002,123456,李四,2023-10-30,1 3,张三003,123456,王五,2023-10-29,1 4,张三004,123456,赵六,2023-10-28,0 5,张三005,123456,孙琪,2023-10-27,0 6,张三006,123456,gh,2023-10-26,1 7,张三007,123456,紧哦碰,2023-10-25,0 8,张三008,123456,浮点数,2023-10-22,0 9,张三009,123456,就看见,2023-10-20,0 10,张三0010,123456,kl,2023-10-18,0 11,张三0011,123456,joioppo,2023-10-31,1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3、执行指令加载数据(就算load 1000万行数据也非常快)
// 换成 infile 登录 mysql --local-infile=1 -u root -p 'mysql密码' // 查看 local_infile 模块是否打开 show global variables like 'local_infile'; // 打开模块 set global local_infile='ON'; // 加载文件 load data local infile 'D:\BaiduNetdiskDownload\user_100.sql' into table user fields terminated by ',' lines terminated by '\n';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-
-
场景二: 主键优化
mysql 表的逻辑存储结构:mysql 有很多表,对于每张表都分成很多段 => 每个段分成很多区 => 每个区分成 64个 页,页里面存储的才是行数据。

场景三: order by优化

- Using filesort:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 fileSort 排序。order by 的字段没有建立索引(不考虑回表)
- Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为using index,不需要额外排序,操作效率高。order by 的字段建立了索引
order by 优化建议:
- 根据排序字段建立合适的索引,多字段排序时,也要遵循最左前缀法则。
- 尽量使用覆盖索引。
- 多字段排序,一个升序一个降序,此时需要注意联合索引在创建时的规则 (ASC / DESC)。
- 如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小 sort_buffer_size(默认是 256k)。
场景四: group by优化

- Using temporary:表示用到了临时表,效率比较低。
- Using index:表示用到了索引,效率很高。
场景五: limit优化
limit begin rows 解释:
select * from person limit 0,10 // 从第一行开始,返回10行(返回1-10行记录) select * from person limit 100,10 // 从第100行开始,返回10行(返回100-110行记录)- 1
- 2
但是随着起始行增加,查询耗时也会增加,limit begin rows 就是先把数据表的前 begin + rows 行数据先排序,排序后其他记录全部丢弃,只返回指定的 rows 行记录。
假如我要查询limit 5000000,10,从第500万行数据开始,返回10条记录,此时:
-
sql 1:
select * from person limit 5000000, 10;- 1

-
sql 2:
select t1.* from person t1,(select id from person order by id limit 5000000,10) t2 where t1.id = t2.id;- 1

发现第二种方式查询速度会更快,这是因为第一种方式是把 500 万行数据全部查询出来(查询的过程中需要走回表,并且回表 500万 + 10次)再排序返回;第二种方式是只排序 id,把 id 排序后只回表 10次就返回数据。
场景六: count优化
对于count 求记录数,有以下几种方式:
- count (*):mysql 不把每行的数据读取出来,只进行按行累加。效率最高,因为不读取任何数据
- count (1):mysql 会遍历整个表,但是也不读取数据,而是把读取的每行替换成数字 1,然后对行进行累加。
- count (主键):mysql 会把主键读取出来,判断是否为 null,不为 null 则累加,显然主键不会为 null,但是也会进行读取。
- count (字段):mysql 会读取指定的字段,判断是否为 null,不为 null 则累加。效率最差
场景七: update优化
在进行 update 操作时很简单,where 条件后面存在两种情况:
- 情况一:where 条件后的字段有索引,如果有索引,那么 mysql 会对行符合情况的一行加行锁。
- 情况二:where 条件后的字段未加索引,如果没有索引,mysql 则会对整张表加表锁。
很明显加了表锁会影响并发性能,因此 update 操作时尽量使用建立索引的字段做判断条件。
-
相关阅读:
python高阶函数心得笔记,python高阶函数知识
VM系列振弦读数模块采集测量数据的一般步骤
可托拉拽的WPF选项卡控件,强大好用!
CMake的使用
安全学习_开发相关_Java第三方组件Log4j&FastJSON及相关安全问题简介
辉芒微电子-使用verilog实现一个或门的电路。
Worthington 胆碱酯酶,丁酰相关说明书
飞天使-k8s基础组件分析-安全
k8s部署rocketmq5.1.4
用于设计 CNN 的 7 种不同卷积
- 原文地址:https://blog.csdn.net/weixin_44780078/article/details/133957409